 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobally Convergent Variational Inference
Jan 14, 2025In variational inference (VI), an approximation of the posterior distribution is selected from a family of distributions through numerical optimization. With the most common variational objective function, known as the evidence lower bound (ELBO), only convergence to a local optimum can be guaranteed. In this work, we instead establish the global convergence of a particular VI method. This VI method, which may be considered an instance of neural posterior estimation (NPE), minimizes an expectation of the inclusive (forward) KL divergence to fit a variational distribution that is parameterized by a neural network. Our convergence result relies on the neural tangent kernel (NTK) to characterize the gradient dynamics that arise from considering the variational objective in function space. In the asymptotic regime of a fixed, positive-definite neural tangent kernel, we establish conditions under which the variational objective admits a unique solution in a reproducing kernel Hilbert space (RKHS). Then, we show that the gradient descent dynamics in function space converge to this unique function. In ablation studies and practical problems, we demonstrate that our results explain the behavior of NPE in non-asymptotic finite-neuron settings, and show that NPE outperforms ELBO-based optimization, which often converges to shallow local optima.
Sequential Monte Carlo for Inclusive KL Minimization in Amortized Variational Inference
Mar 15, 2024



For training an encoder network to perform amortized variational inference, the Kullback-Leibler (KL) divergence from the exact posterior to its approximation, known as the inclusive or forward KL, is an increasingly popular choice of variational objective due to the mass-covering property of its minimizer. However, minimizing this objective is challenging. A popular existing approach, Reweighted Wake-Sleep (RWS), suffers from heavily biased gradients and a circular pathology that results in highly concentrated variational distributions. As an alternative, we propose SMC-Wake, a procedure for fitting an amortized variational approximation that uses likelihood-tempered sequential Monte Carlo samplers to estimate the gradient of the inclusive KL divergence. We propose three gradient estimators, all of which are asymptotically unbiased in the number of iterations and two of which are strongly consistent. Our method interleaves stochastic gradient updates, SMC samplers, and iterative improvement to an estimate of the normalizing constant to reduce bias from self-normalization. In experiments with both simulated and real datasets, SMC-Wake fits variational distributions that approximate the posterior more accurately than existing methods.
Variational Inference with Coverage Guarantees
May 23, 2023



Amortized variational inference produces a posterior approximator that can compute a posterior approximation given any new observation. Unfortunately, there are few guarantees about the quality of these approximate posteriors. We propose Conformalized Amortized Neural Variational Inference (CANVI), a procedure that is scalable, easily implemented, and provides guaranteed marginal coverage. Given a collection of candidate amortized posterior approximators, CANVI constructs conformalized predictors based on each candidate, compares the predictors using a metric known as predictive efficiency, and returns the most efficient predictor. CANVI ensures that the resulting predictor constructs regions that contain the truth with high probability (exactly how high is prespecified by the user). CANVI is agnostic to design decisions in formulating the candidate approximators and only requires access to samples from the forward model, permitting its use in likelihood-free settings. We prove lower bounds on the predictive efficiency of the regions produced by CANVI and explore how the quality of a posterior approximation relates to the predictive efficiency of prediction regions based on that approximation. Finally, we demonstrate the accurate calibration and high predictive efficiency of CANVI on a suite of simulation-based inference benchmark tasks and an important scientific task: analyzing galaxy emission spectra.
General linear-time inference for Gaussian Processes on one dimension
Mar 11, 2020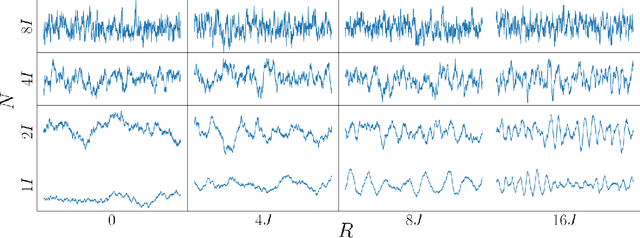
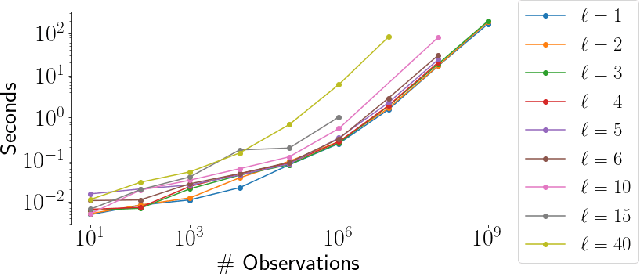


Gaussian Processes (GPs) provide a powerful probabilistic framework for interpolation, forecasting, and smoothing, but have been hampered by computational scaling issues. Here we prove that for data sampled on one dimension (e.g., a time series sampled at arbitrarily-spaced intervals), approximate GP inference at any desired level of accuracy requires computational effort that scales linearly with the number of observations; this new theorem enables inference on much larger datasets than was previously feasible. To achieve this improved scaling we propose a new family of stationary covariance kernels: the Latent Exponentially Generated (LEG) family, which admits a convenient stable state-space representation that allows linear-time inference. We prove that any continuous integrable stationary kernel can be approximated arbitrarily well by some member of the LEG family. The proof draws connections to Spectral Mixture Kernels, providing new insight about the flexibility of this popular family of kernels. We propose parallelized algorithms for performing inference and learning in the LEG model, test the algorithm on real and synthetic data, and demonstrate scaling to datasets with billions of samples.