 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobally Convergent Variational Inference
Jan 14, 2025In variational inference (VI), an approximation of the posterior distribution is selected from a family of distributions through numerical optimization. With the most common variational objective function, known as the evidence lower bound (ELBO), only convergence to a local optimum can be guaranteed. In this work, we instead establish the global convergence of a particular VI method. This VI method, which may be considered an instance of neural posterior estimation (NPE), minimizes an expectation of the inclusive (forward) KL divergence to fit a variational distribution that is parameterized by a neural network. Our convergence result relies on the neural tangent kernel (NTK) to characterize the gradient dynamics that arise from considering the variational objective in function space. In the asymptotic regime of a fixed, positive-definite neural tangent kernel, we establish conditions under which the variational objective admits a unique solution in a reproducing kernel Hilbert space (RKHS). Then, we show that the gradient descent dynamics in function space converge to this unique function. In ablation studies and practical problems, we demonstrate that our results explain the behavior of NPE in non-asymptotic finite-neuron settings, and show that NPE outperforms ELBO-based optimization, which often converges to shallow local optima.
Sequential Monte Carlo for Inclusive KL Minimization in Amortized Variational Inference
Mar 15, 2024



For training an encoder network to perform amortized variational inference, the Kullback-Leibler (KL) divergence from the exact posterior to its approximation, known as the inclusive or forward KL, is an increasingly popular choice of variational objective due to the mass-covering property of its minimizer. However, minimizing this objective is challenging. A popular existing approach, Reweighted Wake-Sleep (RWS), suffers from heavily biased gradients and a circular pathology that results in highly concentrated variational distributions. As an alternative, we propose SMC-Wake, a procedure for fitting an amortized variational approximation that uses likelihood-tempered sequential Monte Carlo samplers to estimate the gradient of the inclusive KL divergence. We propose three gradient estimators, all of which are asymptotically unbiased in the number of iterations and two of which are strongly consistent. Our method interleaves stochastic gradient updates, SMC samplers, and iterative improvement to an estimate of the normalizing constant to reduce bias from self-normalization. In experiments with both simulated and real datasets, SMC-Wake fits variational distributions that approximate the posterior more accurately than existing methods.
Diffusion Models for Probabilistic Deconvolution of Galaxy Images
Jul 20, 2023



Telescopes capture images with a particular point spread function (PSF). Inferring what an image would have looked like with a much sharper PSF, a problem known as PSF deconvolution, is ill-posed because PSF convolution is not an invertible transformation. Deep generative models are appealing for PSF deconvolution because they can infer a posterior distribution over candidate images that, if convolved with the PSF, could have generated the observation. However, classical deep generative models such as VAEs and GANs often provide inadequate sample diversity. As an alternative, we propose a classifier-free conditional diffusion model for PSF deconvolution of galaxy images. We demonstrate that this diffusion model captures a greater diversity of possible deconvolutions compared to a conditional VAE.
Variational Inference with Coverage Guarantees
May 23, 2023



Amortized variational inference produces a posterior approximator that can compute a posterior approximation given any new observation. Unfortunately, there are few guarantees about the quality of these approximate posteriors. We propose Conformalized Amortized Neural Variational Inference (CANVI), a procedure that is scalable, easily implemented, and provides guaranteed marginal coverage. Given a collection of candidate amortized posterior approximators, CANVI constructs conformalized predictors based on each candidate, compares the predictors using a metric known as predictive efficiency, and returns the most efficient predictor. CANVI ensures that the resulting predictor constructs regions that contain the truth with high probability (exactly how high is prespecified by the user). CANVI is agnostic to design decisions in formulating the candidate approximators and only requires access to samples from the forward model, permitting its use in likelihood-free settings. We prove lower bounds on the predictive efficiency of the regions produced by CANVI and explore how the quality of a posterior approximation relates to the predictive efficiency of prediction regions based on that approximation. Finally, we demonstrate the accurate calibration and high predictive efficiency of CANVI on a suite of simulation-based inference benchmark tasks and an important scientific task: analyzing galaxy emission spectra.
Statistical Inference for Coadded Astronomical Images
Nov 17, 2022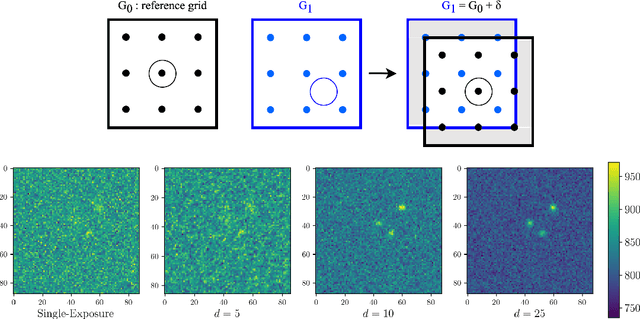
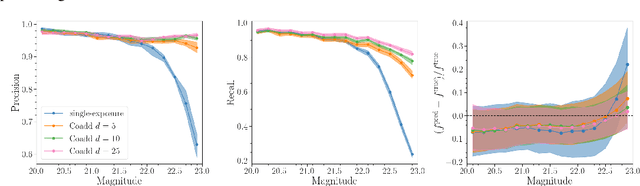
Coadded astronomical images are created by stacking multiple single-exposure images. Because coadded images are smaller in terms of data size than the single-exposure images they summarize, loading and processing them is less computationally expensive. However, image coaddition introduces additional dependence among pixels, which complicates principled statistical analysis of them. We present a principled Bayesian approach for performing light source parameter inference with coadded astronomical images. Our method implicitly marginalizes over the single-exposure pixel intensities that contribute to the coadded images, giving it the computational efficiency necessary to scale to next-generation astronomical surveys. As a proof of concept, we show that our method for estimating the locations and fluxes of stars using simulated coadds outperforms a method trained on single-exposure images.
Dynamic Survival Transformers for Causal Inference with Electronic Health Records
Oct 25, 2022



In medicine, researchers often seek to infer the effects of a given treatment on patients' outcomes. However, the standard methods for causal survival analysis make simplistic assumptions about the data-generating process and cannot capture complex interactions among patient covariates. We introduce the Dynamic Survival Transformer (DynST), a deep survival model that trains on electronic health records (EHRs). Unlike previous transformers used in survival analysis, DynST can make use of time-varying information to predict evolving survival probabilities. We derive a semi-synthetic EHR dataset from MIMIC-III to show that DynST can accurately estimate the causal effect of a treatment intervention on restricted mean survival time (RMST). We demonstrate that DynST achieves better predictive and causal estimation than two alternative models.
Scalable Bayesian Inference for Detection and Deblending in Astronomical Images
Jul 12, 2022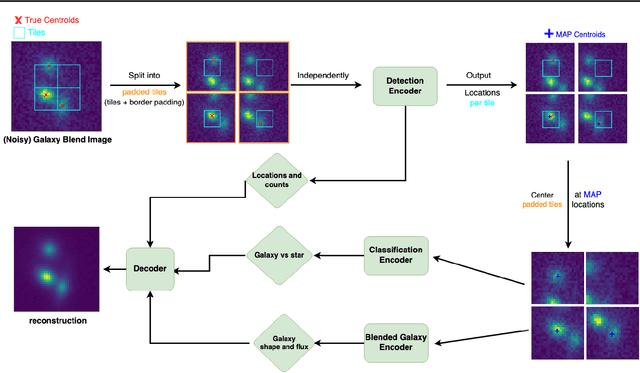
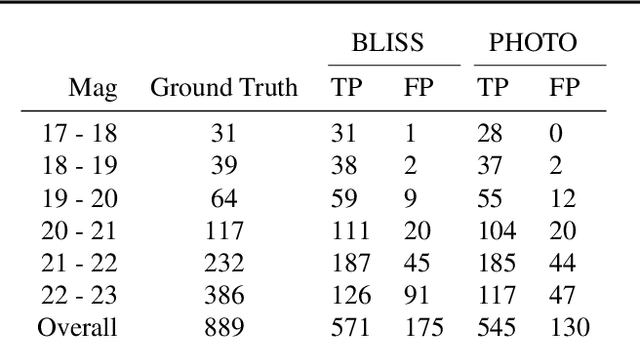

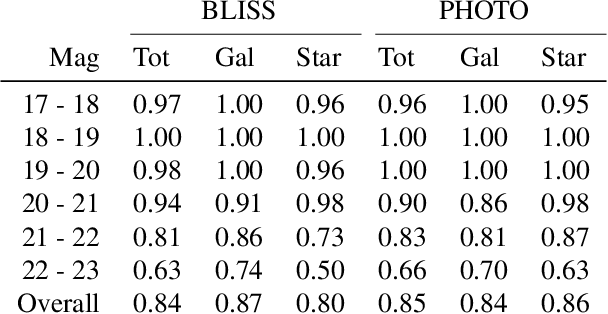
We present a new probabilistic method for detecting, deblending, and cataloging astronomical sources called the Bayesian Light Source Separator (BLISS). BLISS is based on deep generative models, which embed neural networks within a Bayesian model. For posterior inference, BLISS uses a new form of variational inference known as Forward Amortized Variational Inference. The BLISS inference routine is fast, requiring a single forward pass of the encoder networks on a GPU once the encoder networks are trained. BLISS can perform fully Bayesian inference on megapixel images in seconds, and produces highly accurate catalogs. BLISS is highly extensible, and has the potential to directly answer downstream scientific questions in addition to producing probabilistic catalogs.
Normalizing Flows for Knockoff-free Controlled Feature Selection
Jun 03, 2021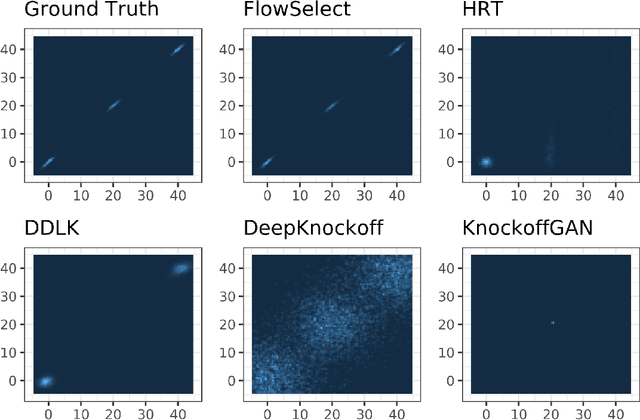


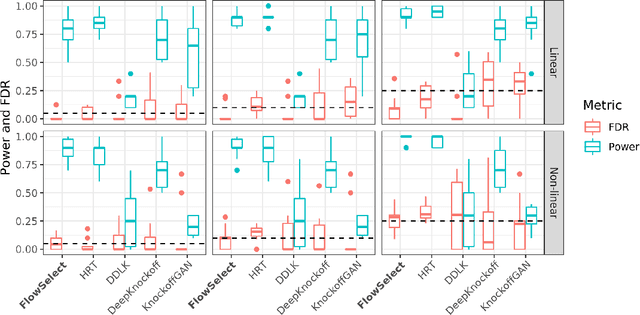
The goal of controlled feature selection is to discover the features a response depends on while limiting the proportion of false discoveries to a predefined level. Recently, multiple methods have been proposed that use deep learning to generate knockoffs for controlled feature selection through the Model-X knockoff framework. We demonstrate, however, that these methods often fail to control the false discovery rate (FDR). There are two reasons for this shortcoming. First, these methods often learn inaccurate models of features. Second, the "swap" property, which is required for knockoffs to be valid, is often not well enforced. We propose a new procedure called FlowSelect that remedies both of these problems. To more accurately model the features, FlowSelect uses normalizing flows, the state-of-the-art method for density estimation. To circumvent the need to enforce the swap property, FlowSelect uses a novel MCMC-based procedure to directly compute p-values for each feature. Asymptotically, FlowSelect controls the FDR exactly. Empirically, FlowSelect controls the FDR well on both synthetic and semi-synthetic benchmarks, whereas competing knockoff-based approaches fail to do so. FlowSelect also demonstrates greater power on these benchmarks. Additionally, using data from a genome-wide association study of soybeans, FlowSelect correctly infers the genetic variants associated with specific soybean traits.
Variational Inference for Deblending Crowded Starfields
Feb 04, 2021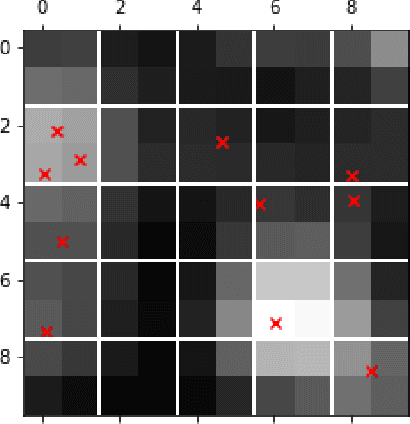
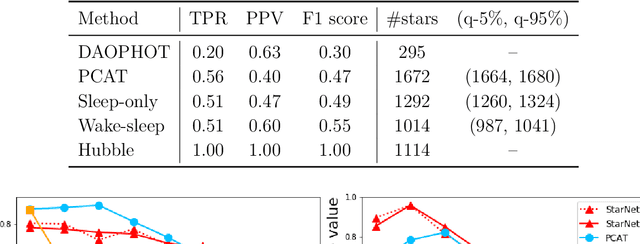
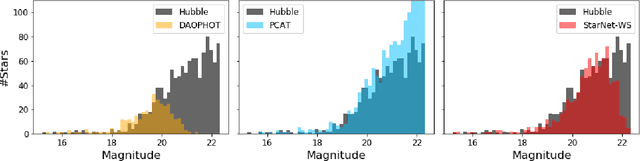
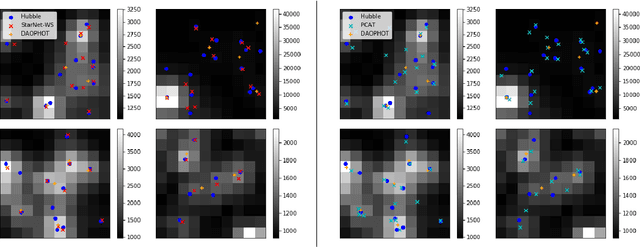
In the image data collected by astronomical surveys, stars and galaxies often overlap. Deblending is the task of distinguishing and characterizing individual light sources from survey images. We propose StarNet, a fully Bayesian method to deblend sources in astronomical images of crowded star fields. StarNet leverages recent advances in variational inference, including amortized variational distributions and the wake-sleep algorithm. Wake-sleep, which minimizes forward KL divergence, has significant benefits compared to traditional variational inference, which minimizes a reverse KL divergence. In our experiments with SDSS images of the M2 globular cluster, StarNet is substantially more accurate than two competing methods: Probablistic Cataloging (PCAT), a method that uses MCMC for inference, and a software pipeline employed by SDSS for deblending (DAOPHOT). In addition, StarNet is as much as $100,000$ times faster than PCAT, exhibiting the scaling characteristics necessary to perform fully Bayesian inference on modern astronomical surveys.
Flows Succeed Where GANs Fail: Lessons from Low-Dimensional Data
Jun 17, 2020

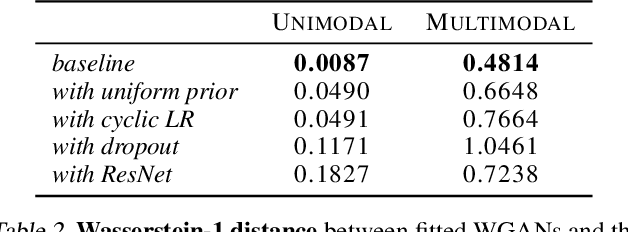
Normalizing flows and generative adversarial networks (GANs) are both approaches to density estimation that use deep neural networks to transform samples from an uninformative prior distribution to an approximation of the data distribution. There is great interest in both for general-purpose statistical modeling, but the two approaches have seldom been compared to each other for modeling non-image data. The difficulty of computing likelihoods with GANs, which are implicit models, makes conducting such a comparison challenging. We work around this difficulty by considering several low-dimensional synthetic datasets. An extensive grid search over GAN architectures, hyperparameters, and training procedures suggests that no GAN is capable of modeling our simple low-dimensional data well, a task we view as a prerequisite for an approach to be considered suitable for general-purpose statistical modeling. Several normalizing flows, on the other hand, excelled at these tasks, even substantially outperforming WGAN in terms of Wasserstein distance---the metric that WGAN alone targets. Overall, normalizing flows appear to be more reliable tools for statistical inference than GANs.