 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunities in AI/ML for the Rubin LSST Dark Energy Science Collaboration
Jan 20, 2026The Vera C. Rubin Observatory's Legacy Survey of Space and Time (LSST) will produce unprecedented volumes of heterogeneous astronomical data (images, catalogs, and alerts) that challenge traditional analysis pipelines. The LSST Dark Energy Science Collaboration (DESC) aims to derive robust constraints on dark energy and dark matter from these data, requiring methods that are statistically powerful, scalable, and operationally reliable. Artificial intelligence and machine learning (AI/ML) are already embedded across DESC science workflows, from photometric redshifts and transient classification to weak lensing inference and cosmological simulations. Yet their utility for precision cosmology hinges on trustworthy uncertainty quantification, robustness to covariate shift and model misspecification, and reproducible integration within scientific pipelines. This white paper surveys the current landscape of AI/ML across DESC's primary cosmological probes and cross-cutting analyses, revealing that the same core methodologies and fundamental challenges recur across disparate science cases. Since progress on these cross-cutting challenges would benefit multiple probes simultaneously, we identify key methodological research priorities, including Bayesian inference at scale, physics-informed methods, validation frameworks, and active learning for discovery. With an eye on emerging techniques, we also explore the potential of the latest foundation model methodologies and LLM-driven agentic AI systems to reshape DESC workflows, provided their deployment is coupled with rigorous evaluation and governance. Finally, we discuss critical software, computing, data infrastructure, and human capital requirements for the successful deployment of these new methodologies, and consider associated risks and opportunities for broader coordination with external actors.
Statistical Inference for Coadded Astronomical Images
Nov 17, 2022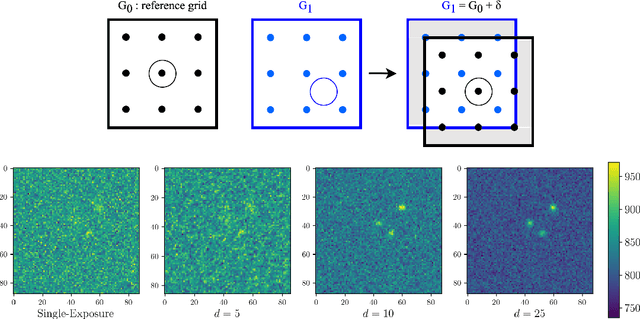
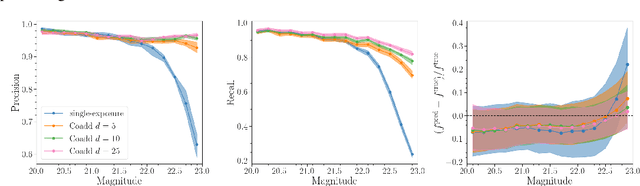
Coadded astronomical images are created by stacking multiple single-exposure images. Because coadded images are smaller in terms of data size than the single-exposure images they summarize, loading and processing them is less computationally expensive. However, image coaddition introduces additional dependence among pixels, which complicates principled statistical analysis of them. We present a principled Bayesian approach for performing light source parameter inference with coadded astronomical images. Our method implicitly marginalizes over the single-exposure pixel intensities that contribute to the coadded images, giving it the computational efficiency necessary to scale to next-generation astronomical surveys. As a proof of concept, we show that our method for estimating the locations and fluxes of stars using simulated coadds outperforms a method trained on single-exposure images.
Scalable Bayesian Inference for Detection and Deblending in Astronomical Images
Jul 12, 2022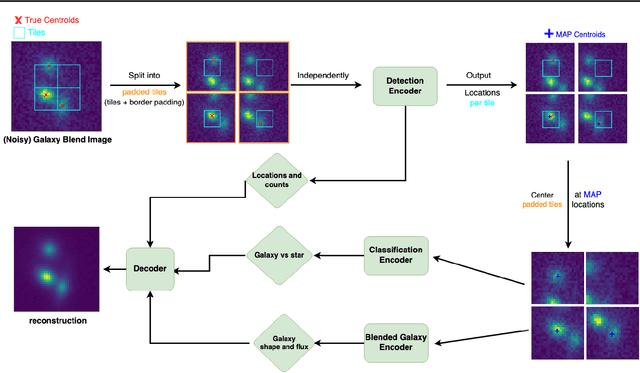
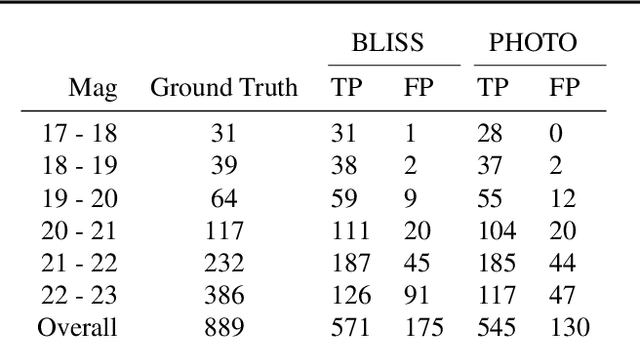

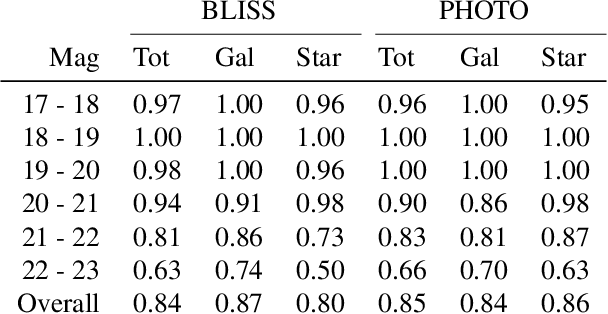
We present a new probabilistic method for detecting, deblending, and cataloging astronomical sources called the Bayesian Light Source Separator (BLISS). BLISS is based on deep generative models, which embed neural networks within a Bayesian model. For posterior inference, BLISS uses a new form of variational inference known as Forward Amortized Variational Inference. The BLISS inference routine is fast, requiring a single forward pass of the encoder networks on a GPU once the encoder networks are trained. BLISS can perform fully Bayesian inference on megapixel images in seconds, and produces highly accurate catalogs. BLISS is highly extensible, and has the potential to directly answer downstream scientific questions in addition to producing probabilistic catalogs.
Machine Learning and Cosmology
Mar 15, 2022Methods based on machine learning have recently made substantial inroads in many corners of cosmology. Through this process, new computational tools, new perspectives on data collection, model development, analysis, and discovery, as well as new communities and educational pathways have emerged. Despite rapid progress, substantial potential at the intersection of cosmology and machine learning remains untapped. In this white paper, we summarize current and ongoing developments relating to the application of machine learning within cosmology and provide a set of recommendations aimed at maximizing the scientific impact of these burgeoning tools over the coming decade through both technical development as well as the fostering of emerging communities.
DeepSZ: Identification of Sunyaev-Zel'dovich Galaxy Clusters using Deep Learning
Mar 08, 2021
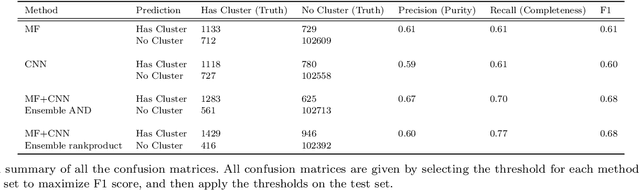

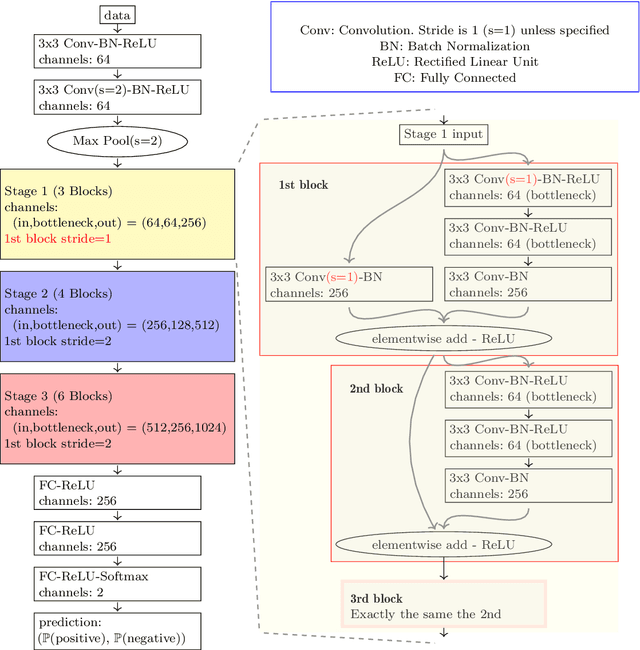
Galaxy clusters identified from the Sunyaev Zel'dovich (SZ) effect are a key ingredient in multi-wavelength cluster-based cosmology. We present a comparison between two methods of cluster identification: the standard Matched Filter (MF) method in SZ cluster finding and a method using Convolutional Neural Networks (CNN). We further implement and show results for a `combined' identifier. We apply the methods to simulated millimeter maps for several observing frequencies for an SPT-3G-like survey. There are some key differences between the methods. The MF method requires image pre-processing to remove point sources and a model for the noise, while the CNN method requires very little pre-processing of images. Additionally, the CNN requires tuning of hyperparameters in the model and takes as input, cutout images of the sky. Specifically, we use the CNN to classify whether or not an 8 arcmin $\times$ 8 arcmin cutout of the sky contains a cluster. We compare differences in purity and completeness. The MF signal-to-noise ratio depends on both mass and redshift. Our CNN, trained for a given mass threshold, captures a different set of clusters than the MF, some of which have SNR below the MF detection threshold. However, the CNN tends to mis-classify cutouts whose clusters are located near the edge of the cutout, which can be mitigated with staggered cutouts. We leverage the complementarity of the two methods, combining the scores from each method for identification. The purity and completeness of the MF alone are both 0.61, assuming a standard detection threshold. The purity and completeness of the CNN alone are 0.59 and 0.61. The combined classification method yields 0.60 and 0.77, a significant increase for completeness with a modest decrease in purity. We advocate for combined methods that increase the confidence of many lower signal-to-noise clusters.
Algorithms and Statistical Models for Scientific Discovery in the Petabyte Era
Nov 05, 2019The field of astronomy has arrived at a turning point in terms of size and complexity of both datasets and scientific collaboration. Commensurately, algorithms and statistical models have begun to adapt --- e.g., via the onset of artificial intelligence --- which itself presents new challenges and opportunities for growth. This white paper aims to offer guidance and ideas for how we can evolve our technical and collaborative frameworks to promote efficient algorithmic development and take advantage of opportunities for scientific discovery in the petabyte era. We discuss challenges for discovery in large and complex data sets; challenges and requirements for the next stage of development of statistical methodologies and algorithmic tool sets; how we might change our paradigms of collaboration and education; and the ethical implications of scientists' contributions to widely applicable algorithms and computational modeling. We start with six distinct recommendations that are supported by the commentary following them. This white paper is related to a larger corpus of effort that has taken place within and around the Petabytes to Science Workshops (https://petabytestoscience.github.io/).