 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Absence withSymptoms that *T* Show up Decades Later to Recover Empty Categories
Dec 02, 2024
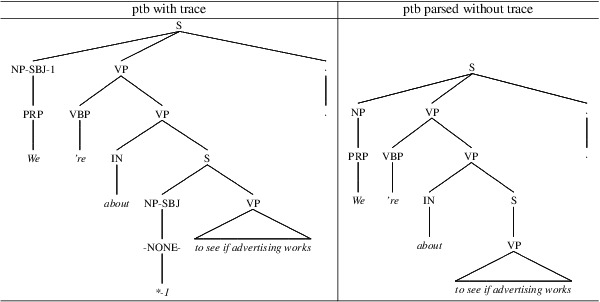
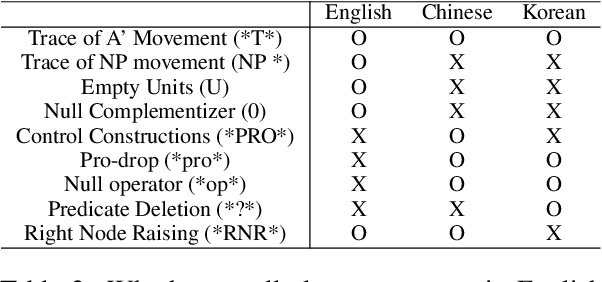
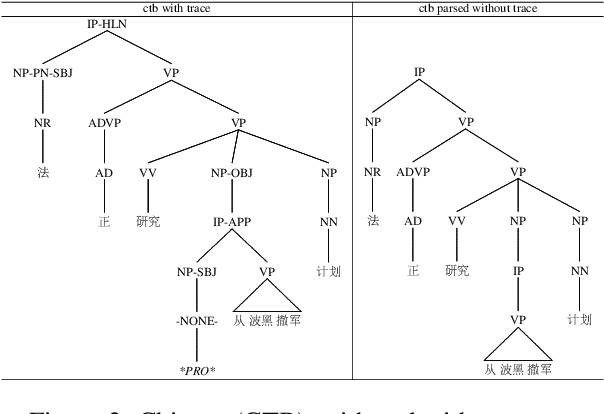
This paper explores null elements in English, Chinese, and Korean Penn treebanks. Null elements contain important syntactic and semantic information, yet they have typically been treated as entities to be removed during language processing tasks, particularly in constituency parsing. Thus, we work towards the removal and, in particular, the restoration of null elements in parse trees. We focus on expanding a rule-based approach utilizing linguistic context information to Chinese, as rule based approaches have historically only been applied to English. We also worked to conduct neural experiments with a language agnostic sequence-to-sequence model to recover null elements for English (PTB), Chinese (CTB) and Korean (KTB). To the best of the authors' knowledge, null elements in three different languages have been explored and compared for the first time. In expanding a rule based approach to Chinese, we achieved an overall F1 score of 80.00, which is comparable to past results in the CTB. In our neural experiments we achieved F1 scores up to 90.94, 85.38 and 88.79 for English, Chinese, and Korean respectively with functional labels.
DeepSZ: Identification of Sunyaev-Zel'dovich Galaxy Clusters using Deep Learning
Mar 08, 2021
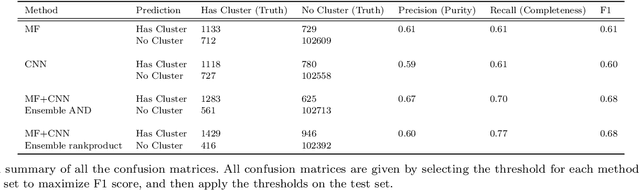

Galaxy clusters identified from the Sunyaev Zel'dovich (SZ) effect are a key ingredient in multi-wavelength cluster-based cosmology. We present a comparison between two methods of cluster identification: the standard Matched Filter (MF) method in SZ cluster finding and a method using Convolutional Neural Networks (CNN). We further implement and show results for a `combined' identifier. We apply the methods to simulated millimeter maps for several observing frequencies for an SPT-3G-like survey. There are some key differences between the methods. The MF method requires image pre-processing to remove point sources and a model for the noise, while the CNN method requires very little pre-processing of images. Additionally, the CNN requires tuning of hyperparameters in the model and takes as input, cutout images of the sky. Specifically, we use the CNN to classify whether or not an 8 arcmin $\times$ 8 arcmin cutout of the sky contains a cluster. We compare differences in purity and completeness. The MF signal-to-noise ratio depends on both mass and redshift. Our CNN, trained for a given mass threshold, captures a different set of clusters than the MF, some of which have SNR below the MF detection threshold. However, the CNN tends to mis-classify cutouts whose clusters are located near the edge of the cutout, which can be mitigated with staggered cutouts. We leverage the complementarity of the two methods, combining the scores from each method for identification. The purity and completeness of the MF alone are both 0.61, assuming a standard detection threshold. The purity and completeness of the CNN alone are 0.59 and 0.61. The combined classification method yields 0.60 and 0.77, a significant increase for completeness with a modest decrease in purity. We advocate for combined methods that increase the confidence of many lower signal-to-noise clusters.