 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Instruction Composition for Automated LLM Red-Teaming
Apr 22, 2026Many approaches to LLM red-teaming leverage an attacker LLM to discover jailbreaks against a target. Several of them task the attacker with identifying effective strategies through trial and error, resulting in a semantically limited range of successes. Another approach discovers diverse attacks by combining crowdsourced harmful queries and tactics into instructions for the attacker, but does so at random, limiting effectiveness. This article introduces a novel framework, Adaptive Instruction Composition, that combines crowdsourced texts according to an adaptive mechanism trained to jointly optimize effectiveness with diversity. We use reinforcement learning to balance exploration with exploitation in a combinatorial space of instructions to guide the attacker toward diverse generations tailored to target vulnerabilities. We demonstrate that our approach substantially outperforms random combination on a set of effectiveness and diversity metrics, even under model transfer. Further, we show that it surpasses a host of recent adaptive approaches on Harmbench. We employ a lightweight neural contextual bandit that adapts to contrastive embedding inputs, and provide ablations suggesting that the contrastive pretraining enables the network to rapidly generalize and scale to the massive space as it learns.
Terminal Agents Suffice for Enterprise Automation
Mar 31, 2026There has been growing interest in building agents that can interact with digital platforms to execute meaningful enterprise tasks autonomously. Among the approaches explored are tool-augmented agents built on abstractions such as Model Context Protocol (MCP) and web agents that operate through graphical interfaces. Yet, it remains unclear whether such complex agentic systems are necessary given their cost and operational overhead. We argue that a coding agent equipped only with a terminal and a filesystem can solve many enterprise tasks more effectively by interacting directly with platform APIs. We evaluate this hypothesis across diverse real-world systems and show that these low-level terminal agents match or outperform more complex agent architectures. Our findings suggest that simple programmatic interfaces, combined with strong foundation models, are sufficient for practical enterprise automation.
GRAID: Synthetic Data Generation with Geometric Constraints and Multi-Agentic Reflection for Harmful Content Detection
Aug 23, 2025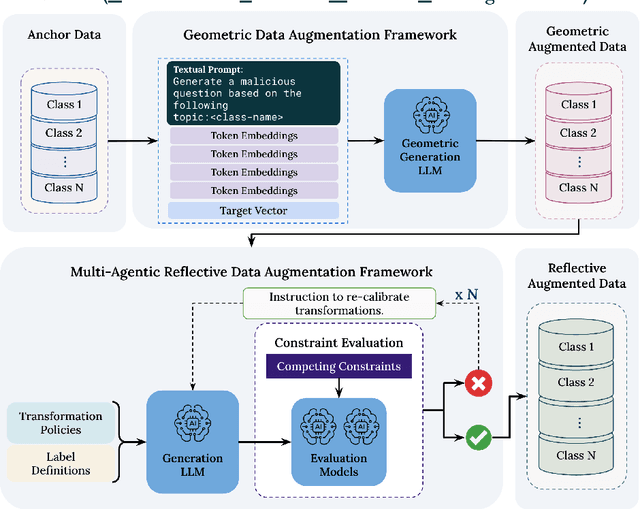

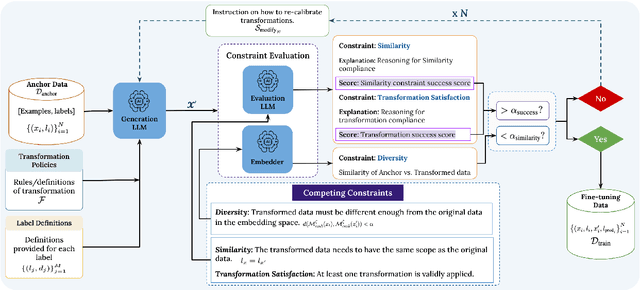
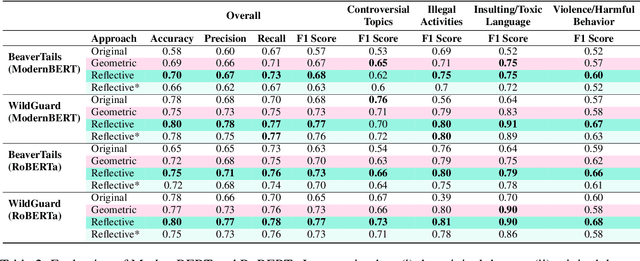
We address the problem of data scarcity in harmful text classification for guardrailing applications and introduce GRAID (Geometric and Reflective AI-Driven Data Augmentation), a novel pipeline that leverages Large Language Models (LLMs) for dataset augmentation. GRAID consists of two stages: (i) generation of geometrically controlled examples using a constrained LLM, and (ii) augmentation through a multi-agentic reflective process that promotes stylistic diversity and uncovers edge cases. This combination enables both reliable coverage of the input space and nuanced exploration of harmful content. Using two benchmark data sets, we demonstrate that augmenting a harmful text classification dataset with GRAID leads to significant improvements in downstream guardrail model performance.
Fine-Tune an SLM or Prompt an LLM? The Case of Generating Low-Code Workflows
May 30, 2025Large Language Models (LLMs) such as GPT-4o can handle a wide range of complex tasks with the right prompt. As per token costs are reduced, the advantages of fine-tuning Small Language Models (SLMs) for real-world applications -- faster inference, lower costs -- may no longer be clear. In this work, we present evidence that, for domain-specific tasks that require structured outputs, SLMs still have a quality advantage. We compare fine-tuning an SLM against prompting LLMs on the task of generating low-code workflows in JSON form. We observe that while a good prompt can yield reasonable results, fine-tuning improves quality by 10% on average. We also perform systematic error analysis to reveal model limitations.
Revisiting Absence withSymptoms that *T* Show up Decades Later to Recover Empty Categories
Dec 02, 2024
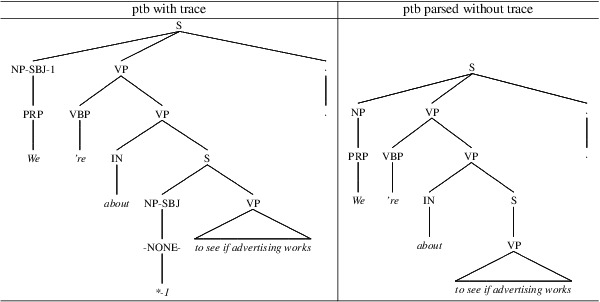
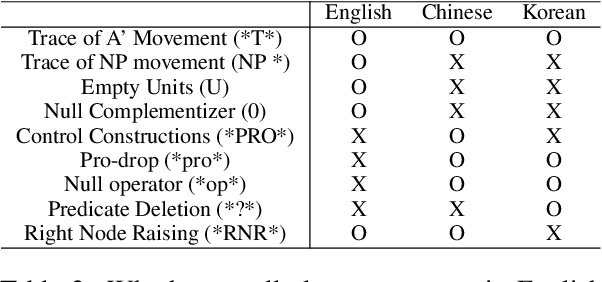
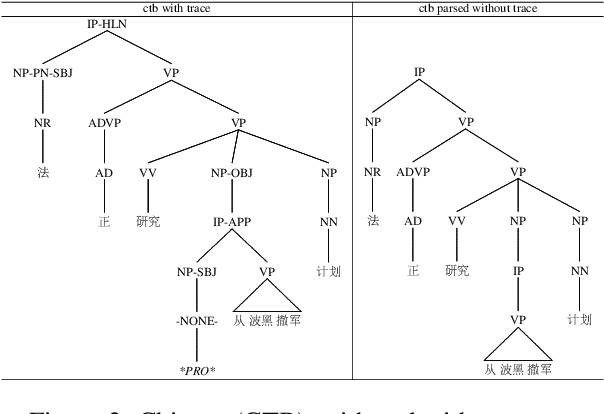
This paper explores null elements in English, Chinese, and Korean Penn treebanks. Null elements contain important syntactic and semantic information, yet they have typically been treated as entities to be removed during language processing tasks, particularly in constituency parsing. Thus, we work towards the removal and, in particular, the restoration of null elements in parse trees. We focus on expanding a rule-based approach utilizing linguistic context information to Chinese, as rule based approaches have historically only been applied to English. We also worked to conduct neural experiments with a language agnostic sequence-to-sequence model to recover null elements for English (PTB), Chinese (CTB) and Korean (KTB). To the best of the authors' knowledge, null elements in three different languages have been explored and compared for the first time. In expanding a rule based approach to Chinese, we achieved an overall F1 score of 80.00, which is comparable to past results in the CTB. In our neural experiments we achieved F1 scores up to 90.94, 85.38 and 88.79 for English, Chinese, and Korean respectively with functional labels.
Fall Detection using Knowledge Distillation Based Long short-term memory for Offline Embedded and Low Power Devices
Aug 24, 2023This paper presents a cost-effective, low-power approach to unintentional fall detection using knowledge distillation-based LSTM (Long Short-Term Memory) models to significantly improve accuracy. With a primary focus on analyzing time-series data collected from various sensors, the solution offers real-time detection capabilities, ensuring prompt and reliable identification of falls. The authors investigate fall detection models that are based on different sensors, comparing their accuracy rates and performance. Furthermore, they employ the technique of knowledge distillation to enhance the models' precision, resulting in refined accurate configurations that consume lower power. As a result, this proposed solution presents a compelling avenue for the development of energy-efficient fall detection systems for future advancements in this critical domain.
A Digital Corpus of St. Lawrence Island Yupik
Jan 26, 2021
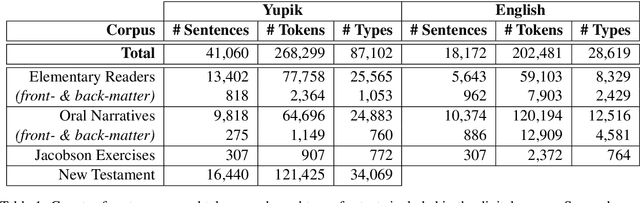
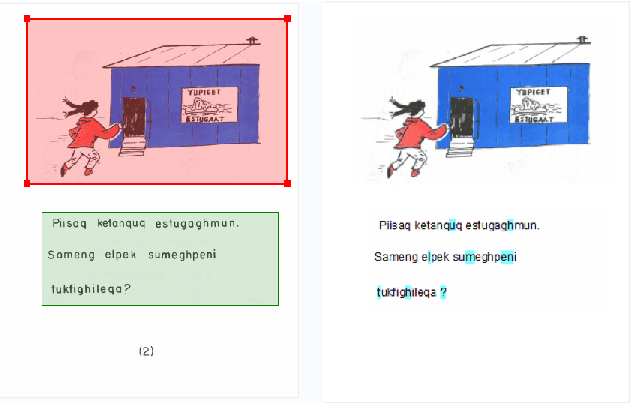

St. Lawrence Island Yupik (ISO 639-3: ess) is an endangered polysynthetic language in the Inuit-Yupik language family indigenous to Alaska and Chukotka. This work presents a step-by-step pipeline for the digitization of written texts, and the first publicly available digital corpus for St. Lawrence Island Yupik, created using that pipeline. This corpus has great potential for future linguistic inquiry and research in NLP. It was also developed for use in Yupik language education and revitalization, with a primary goal of enabling easy access to Yupik texts by educators and by members of the Yupik community. A secondary goal is to support development of language technology such as spell-checkers, text-completion systems, interactive e-books, and language learning apps for use by the Yupik community.
An Evaluation of the Human-Interpretability of Explanation
Jan 31, 2019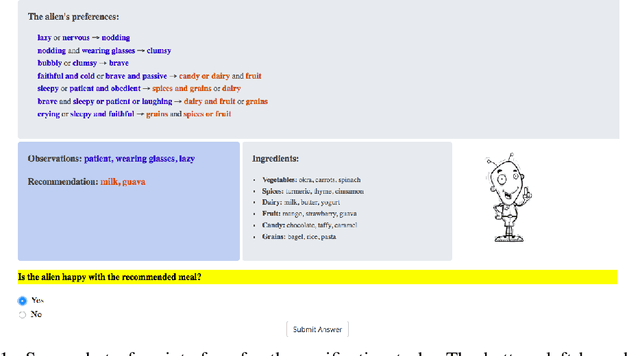
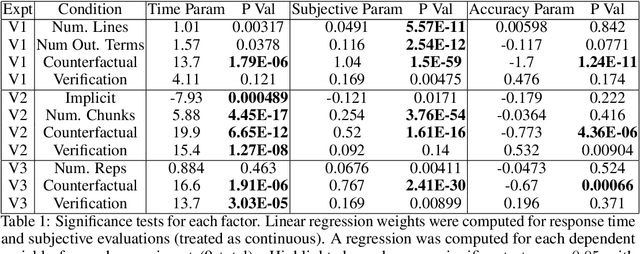
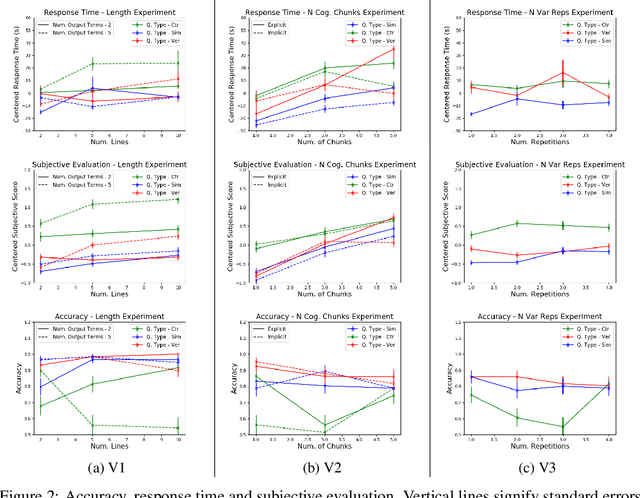
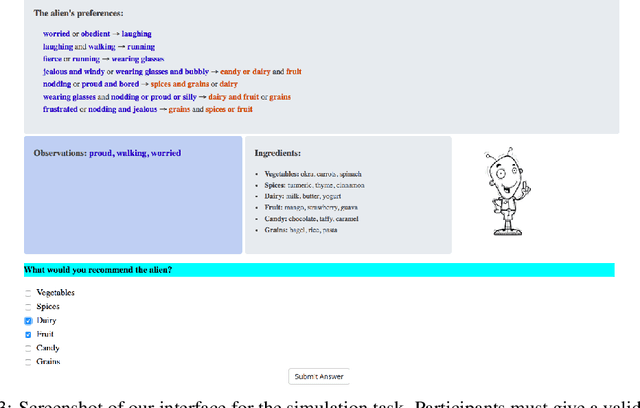
Recent years have seen a boom in interest in machine learning systems that can provide a human-understandable rationale for their predictions or decisions. However, exactly what kinds of explanation are truly human-interpretable remains poorly understood. This work advances our understanding of what makes explanations interpretable under three specific tasks that users may perform with machine learning systems: simulation of the response, verification of a suggested response, and determining whether the correctness of a suggested response changes under a change to the inputs. Through carefully controlled human-subject experiments, we identify regularizers that can be used to optimize for the interpretability of machine learning systems. Our results show that the type of complexity matters: cognitive chunks (newly defined concepts) affect performance more than variable repetitions, and these trends are consistent across tasks and domains. This suggests that there may exist some common design principles for explanation systems.
How do Humans Understand Explanations from Machine Learning Systems? An Evaluation of the Human-Interpretability of Explanation
Feb 02, 2018Recent years have seen a boom in interest in machine learning systems that can provide a human-understandable rationale for their predictions or decisions. However, exactly what kinds of explanation are truly human-interpretable remains poorly understood. This work advances our understanding of what makes explanations interpretable in the specific context of verification. Suppose we have a machine learning system that predicts X, and we provide rationale for this prediction X. Given an input, an explanation, and an output, is the output consistent with the input and the supposed rationale? Via a series of user-studies, we identify what kinds of increases in complexity have the greatest effect on the time it takes for humans to verify the rationale, and which seem relatively insensitive.