 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFall Detection using Knowledge Distillation Based Long short-term memory for Offline Embedded and Low Power Devices
Aug 24, 2023This paper presents a cost-effective, low-power approach to unintentional fall detection using knowledge distillation-based LSTM (Long Short-Term Memory) models to significantly improve accuracy. With a primary focus on analyzing time-series data collected from various sensors, the solution offers real-time detection capabilities, ensuring prompt and reliable identification of falls. The authors investigate fall detection models that are based on different sensors, comparing their accuracy rates and performance. Furthermore, they employ the technique of knowledge distillation to enhance the models' precision, resulting in refined accurate configurations that consume lower power. As a result, this proposed solution presents a compelling avenue for the development of energy-efficient fall detection systems for future advancements in this critical domain.
Monitored Distillation for Positive Congruent Depth Completion
Mar 30, 2022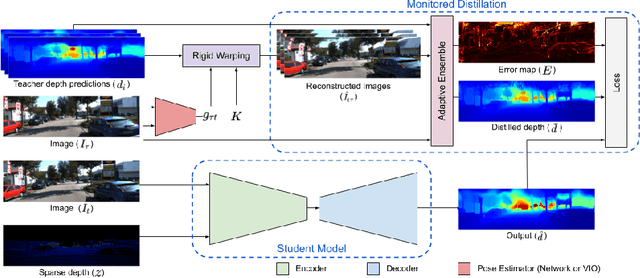
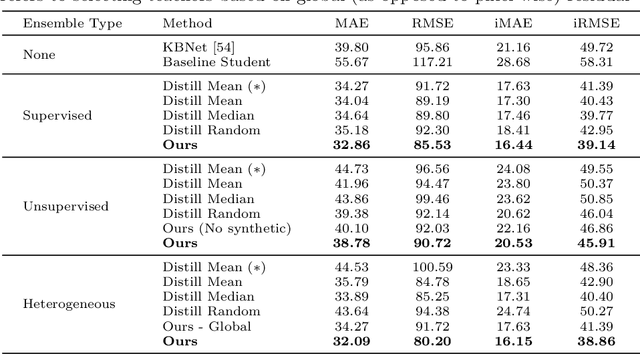
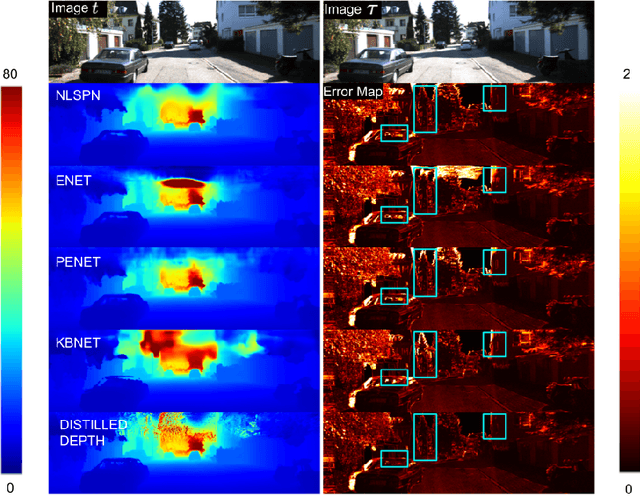
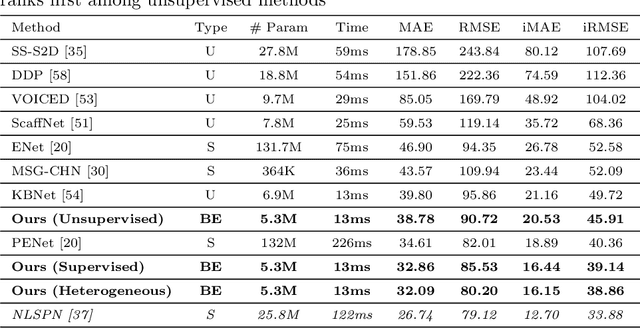
We propose a method to infer a dense depth map from a single image, its calibration, and the associated sparse point cloud. In order to leverage existing models that produce putative depth maps (teacher models), we propose an adaptive knowledge distillation approach that yields a positive congruent training process, where a student model avoids learning the error modes of the teachers. We consider the scenario of a blind ensemble where we do not have access to ground truth for model selection nor training. The crux of our method, termed Monitored Distillation, lies in a validation criterion that allows us to learn from teachers by choosing predictions that best minimize the photometric reprojection error for a given image. The result of which is a distilled depth map and a confidence map, or "monitor", for how well a prediction from a particular teacher fits the observed image. The monitor adaptively weights the distilled depth where, if all of the teachers exhibit high residuals, the standard unsupervised image reconstruction loss takes over as the supervisory signal. On indoor scenes (VOID), we outperform blind ensembling baselines by 13.3% and unsupervised methods by 20.3%; we boast a 79% model size reduction while maintaining comparable performance to the best supervised method. For outdoors (KITTI), we tie for 5th overall on the benchmark despite not using ground truth.
Small Lesion Segmentation in Brain MRIs with Subpixel Embedding
Sep 18, 2021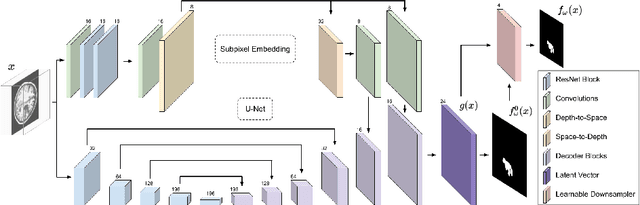

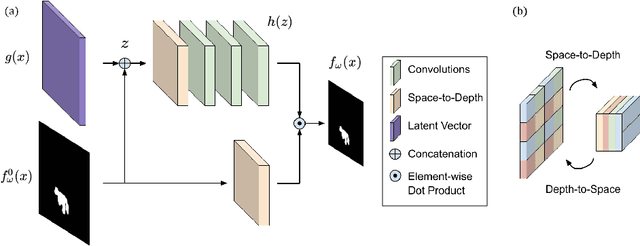
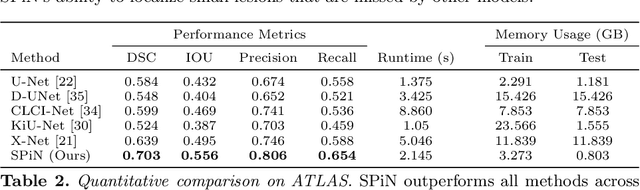
We present a method to segment MRI scans of the human brain into ischemic stroke lesion and normal tissues. We propose a neural network architecture in the form of a standard encoder-decoder where predictions are guided by a spatial expansion embedding network. Our embedding network learns features that can resolve detailed structures in the brain without the need for high-resolution training images, which are often unavailable and expensive to acquire. Alternatively, the encoder-decoder learns global structures by means of striding and max pooling. Our embedding network complements the encoder-decoder architecture by guiding the decoder with fine-grained details lost to spatial downsampling during the encoder stage. Unlike previous works, our decoder outputs at 2 times the input resolution, where a single pixel in the input resolution is predicted by four neighboring subpixels in our output. To obtain the output at the original scale, we propose a learnable downsampler (as opposed to hand-crafted ones e.g. bilinear) that combines subpixel predictions. Our approach improves the baseline architecture by approximately 11.7% and achieves the state of the art on the ATLAS public benchmark dataset with a smaller memory footprint and faster runtime than the best competing method. Our source code has been made available at: https://github.com/alexklwong/subpixel-embedding-segmentation.