 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFall Detection using Knowledge Distillation Based Long short-term memory for Offline Embedded and Low Power Devices
Aug 24, 2023This paper presents a cost-effective, low-power approach to unintentional fall detection using knowledge distillation-based LSTM (Long Short-Term Memory) models to significantly improve accuracy. With a primary focus on analyzing time-series data collected from various sensors, the solution offers real-time detection capabilities, ensuring prompt and reliable identification of falls. The authors investigate fall detection models that are based on different sensors, comparing their accuracy rates and performance. Furthermore, they employ the technique of knowledge distillation to enhance the models' precision, resulting in refined accurate configurations that consume lower power. As a result, this proposed solution presents a compelling avenue for the development of energy-efficient fall detection systems for future advancements in this critical domain.
DeepActsNet: Spatial and Motion features from Face, Hands, and Body Combined with Convolutional and Graph Networks for Improved Action Recognition
Sep 21, 2020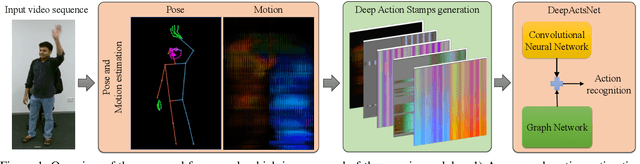
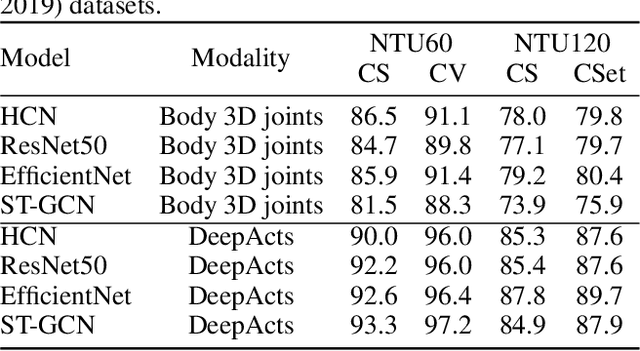

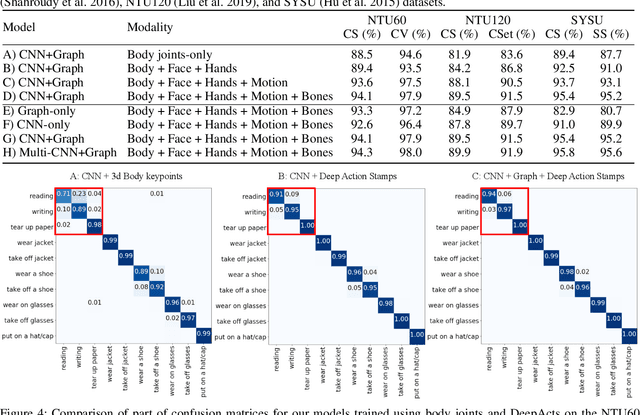
Existing action recognition methods mainly focus on joint and bone information in human body skeleton data due to its robustness to complex backgrounds and dynamic characteristics of the environments. In this paper, we combine body skeleton data with spatial and motion information from face and two hands, and present Deep Action Stamps (DeepActs), a novel data representation to encode actions from video sequences. We also present DeepActsNet, a deep learning based model with modality-specific Convolutional and Graph sub-networks for highly accurate action recognition based on Deep Action Stamps. Experiments on three challenging action recognition datasets (NTU60, NTU120, and SYSU) show that DeepActs produce considerable improvements in the recognition performance of standard convolutional and graph networks. Experiments also show that the fusion of modality-specific convolutional and structural features learnt by our DeepActsNet yields consistent improvements in action recognition accuracy over the state-of-the-art on the target datasets.
SSHFD: Single Shot Human Fall Detection with Occluded Joints Resilience
Apr 03, 2020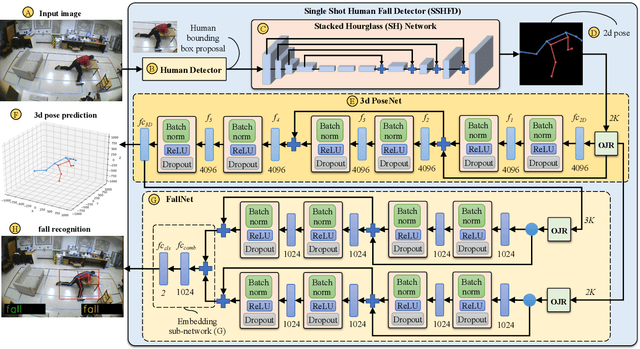
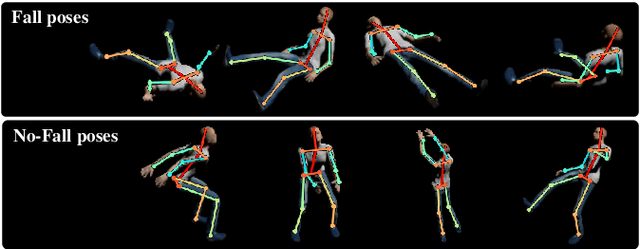
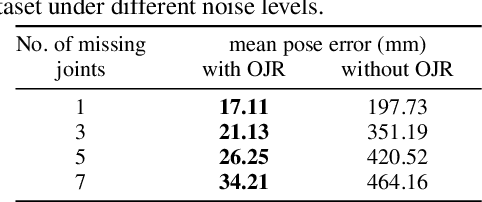

Falling can have fatal consequences for elderly people especially if the fallen person is unable to call for help due to loss of consciousness or any injury. Automatic fall detection systems can assist through prompt fall alarms and by minimizing the fear of falling when living independently at home. Existing vision-based fall detection systems lack generalization to unseen environments due to challenges such as variations in physical appearances, different camera viewpoints, occlusions, and background clutter. In this paper, we explore ways to overcome the above challenges and present Single Shot Human Fall Detector (SSHFD), a deep learning based framework for automatic fall detection from a single image. This is achieved through two key innovations. First, we present a human pose based fall representation which is invariant to appearance characteristics. Second, we present neural network models for 3d pose estimation and fall recognition which are resilient to missing joints due to occluded body parts. Experiments on public fall datasets show that our framework successfully transfers knowledge of 3d pose estimation and fall recognition learnt purely from synthetic data to unseen real-world data, showcasing its generalization capability for accurate fall detection in real-world scenarios.
Ensemble Knowledge Distillation for Learning Improved and Efficient Networks
Sep 19, 2019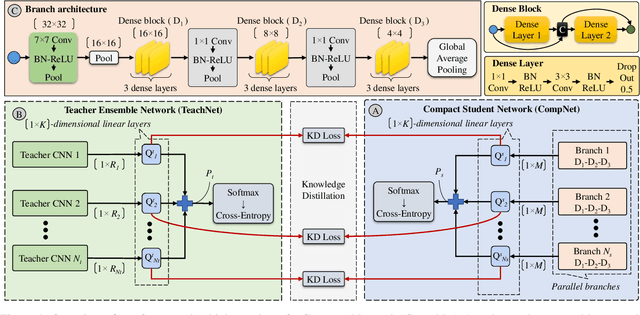
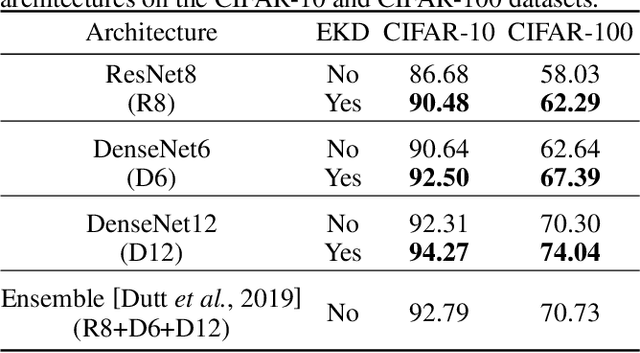
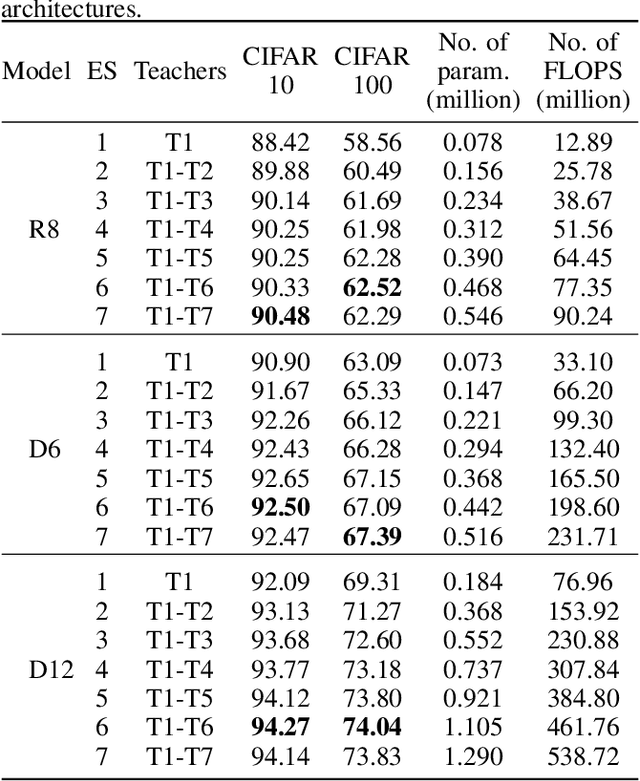
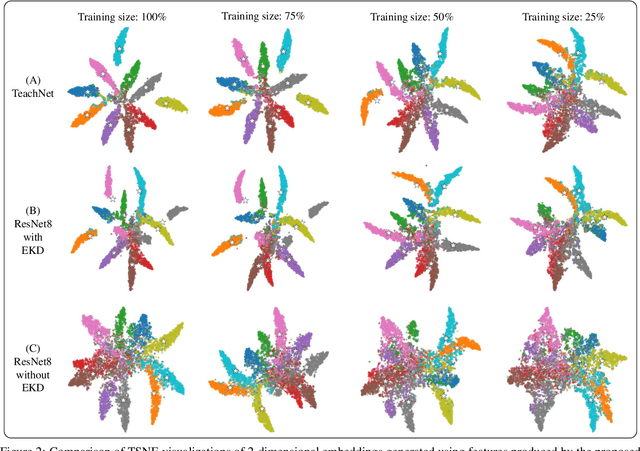
Ensemble models comprising of deep Convolutional Neural Networks (CNN) have shown significant improvements in model generalization but at the cost of large computation and memory requirements. In this paper, we present a framework for learning compact CNN models with improved classification performance and model generalization. For this, we propose a CNN architecture of a compact student model with parallel branches which are trained using ground truth labels and information from high capacity teacher networks in an ensemble learning fashion. Our framework provides two main benefits: i) Distilling knowledge from different teachers into the student network promotes heterogeneity in feature learning at different branches of the student network and enables the network to learn diverse solutions to the target problem. ii) Coupling the branches of the student network through ensembling encourages collaboration and improves the quality of the final predictions by reducing variance in the network outputs. Experiments on the well established CIFAR-10 and CIFAR-100 datasets show that our Ensemble Knowledge Distillation (EKD) improves classification accuracy and model generalization especially in situations with limited training data. Experiments also show that our EKD based compact networks outperform in terms of mean accuracy on the test datasets compared to state-of-the-art knowledge distillation based methods.
PubLayNet: largest dataset ever for document layout analysis
Aug 16, 2019
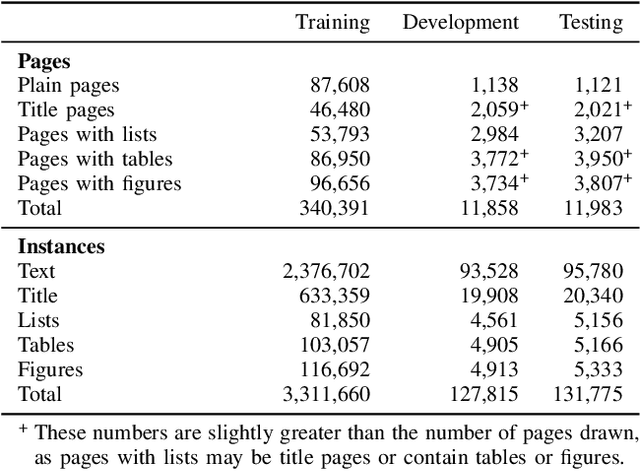

Recognizing the layout of unstructured digital documents is an important step when parsing the documents into structured machine-readable format for downstream applications. Deep neural networks that are developed for computer vision have been proven to be an effective method to analyze layout of document images. However, document layout datasets that are currently publicly available are several magnitudes smaller than established computing vision datasets. Models have to be trained by transfer learning from a base model that is pre-trained on a traditional computer vision dataset. In this paper, we develop the PubLayNet dataset for document layout analysis by automatically matching the XML representations and the content of over 1 million PDF articles that are publicly available on PubMed Central. The size of the dataset is comparable to established computer vision datasets, containing over 360 thousand document images, where typical document layout elements are annotated. The experiments demonstrate that deep neural networks trained on PubLayNet accurately recognize the layout of scientific articles. The pre-trained models are also a more effective base mode for transfer learning on a different document domain. We release the dataset (https://github.com/ibm-aur-nlp/PubLayNet) to support development and evaluation of more advanced models for document layout analysis.
SeizureNet: A Deep Convolutional Neural Network for Accurate Seizure Type Classification and Seizure Detection
Mar 08, 2019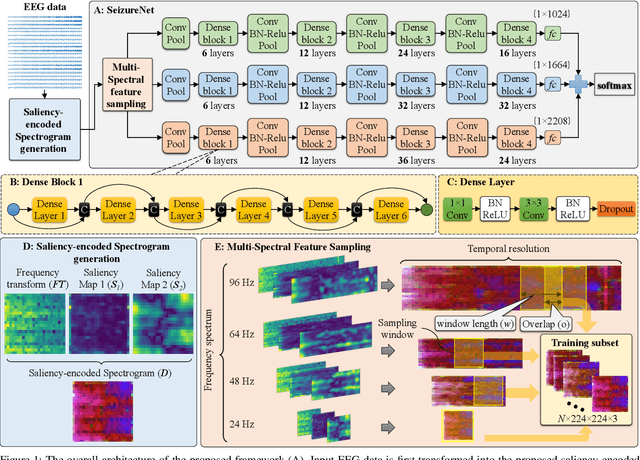

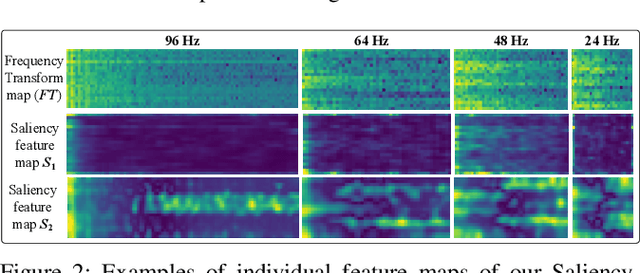
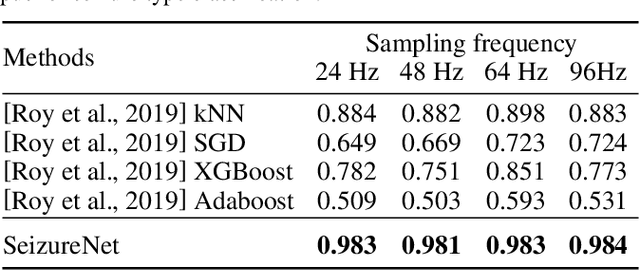
Automatic epileptic seizure analysis is important because the differentiation of neural patterns among different patients can be used to classify people with specific types of epilepsy. This could enable more efficient management of the disease. Automatic seizure type classification using clinical electroencephalograms (EEGs) is challenging due to factors such as low signal to noise ratios, signal artefacts, high variance in the seizure semiology among individual epileptic patients, and limited clinical data constraints. To overcome these challenges, in this paper, we present a deep learning based framework which uses a Convolutional Neural Network (CNN) with dense connections and learns highly robust features at different spatial and temporal resolutions of the EEG data spectrum for accurate cross-patient seizure type classification. We evaluate our framework for seizure type classification and seizure detection on the recently released TUH EEG Seizure Corpus, where our framework achieves overall weighted f 1 scores of up to 0.90 and 0.88, thereby setting new benchmarks on the dataset.
Machine Learning for Seizure Type Classification: Setting the benchmark
Feb 04, 2019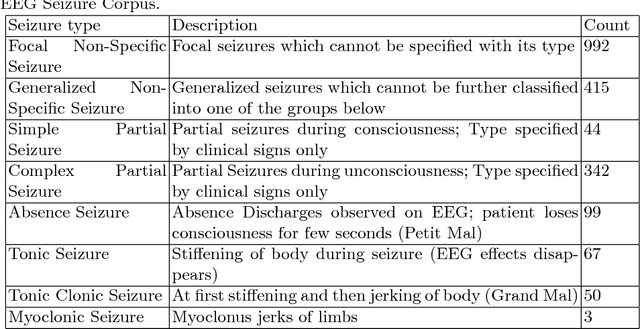
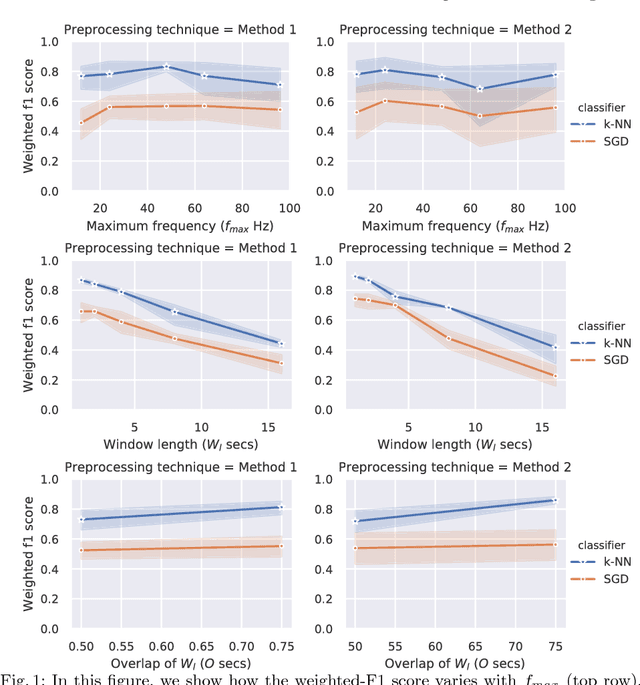
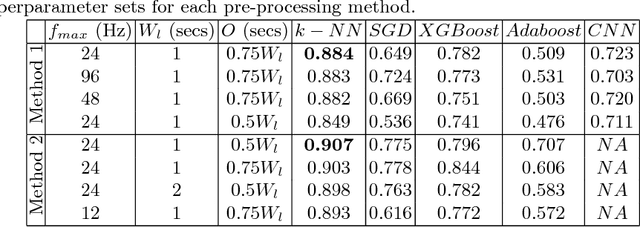
Accurate classification of seizure types plays a crucial role in the treatment and disease management of epileptic patients. Epileptic seizure type not only impacts on the choice of drugs but also on the range of activities a patient can safely engage in. With recent advances being made towards artificial intelligence enabled automatic seizure detection, the next frontier is the automatic classification of seizure types. On that note, in this paper, we undertake the first study to explore the application of machine learning algorithms for multi-class seizure type classification. We used the recently released TUH EEG Seizure Corpus and conducted a thorough search space exploration to evaluate the performance of a combination of various pre-processing techniques, machine learning algorithms, and corresponding hyperparameters on this task. We show that our algorithms can reach a weighted F1 score of up to 0.907 thereby setting the first benchmark for scalp EEG based multi-class seizure type classification.
Densely Supervised Grasp Detector (DSGD)
Oct 01, 2018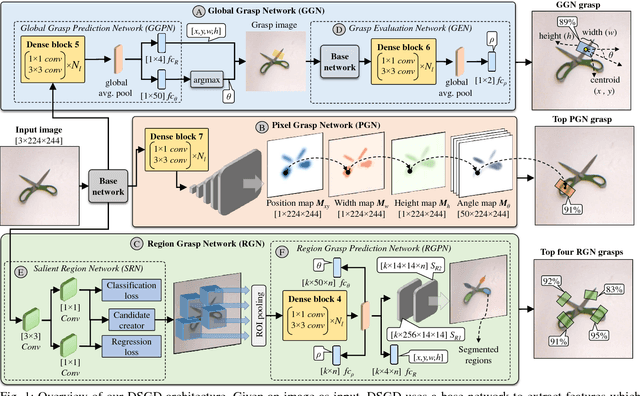
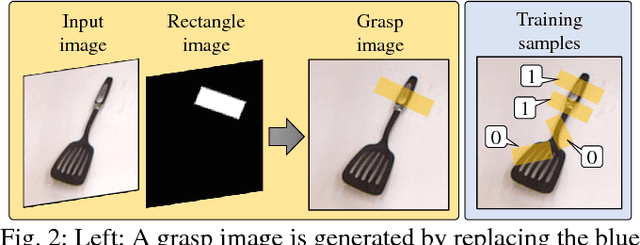
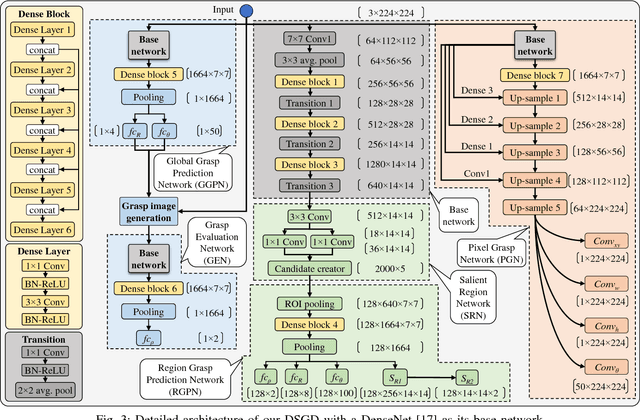

This paper presents Densely Supervised Grasp Detector (DSGD), a deep learning framework which combines CNN structures with layer-wise feature fusion and produces grasps and their confidence scores at different levels of the image hierarchy (i.e., global-, region-, and pixel-levels). Specifically, at the global-level, DSGD uses the entire image information to predict a grasp and its confidence score. At the region-level, DSGD uses a region proposal network to identify salient regions in the image and predicts a grasp for each salient region. At the pixel-level, DSGD uses a fully convolutional network and predicts a grasp and its confidence at every pixel. The grasp with the highest confidence score is selected as the output of DSGD. This selection from hierarchically generated grasp candidates overcomes limitations of the individual models. DSGD outperforms state-of-the-art methods on the Cornell grasp dataset in terms of grasp accuracy. Evaluation on a multi-object dataset and real-world robotic grasping experiments show that DSGD produces highly stable grasps on a set of unseen objects in new environments. It achieves 96% grasp detection accuracy and 90% robotic grasping success rate with real-time inference speed.
Improving classification accuracy of feedforward neural networks for spiking neuromorphic chips
May 19, 2017
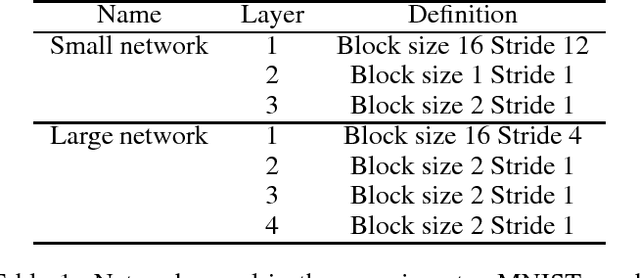
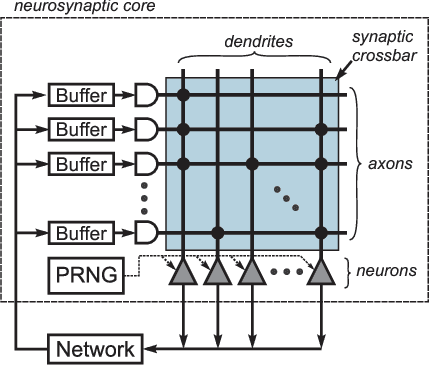
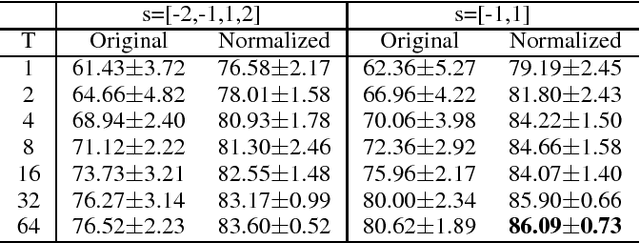
Deep Neural Networks (DNN) achieve human level performance in many image analytics tasks but DNNs are mostly deployed to GPU platforms that consume a considerable amount of power. New hardware platforms using lower precision arithmetic achieve drastic reductions in power consumption. More recently, brain-inspired spiking neuromorphic chips have achieved even lower power consumption, on the order of milliwatts, while still offering real-time processing. However, for deploying DNNs to energy efficient neuromorphic chips the incompatibility between continuous neurons and synaptic weights of traditional DNNs, discrete spiking neurons and synapses of neuromorphic chips need to be overcome. Previous work has achieved this by training a network to learn continuous probabilities, before it is deployed to a neuromorphic architecture, such as IBM TrueNorth Neurosynaptic System, by random sampling these probabilities. The main contribution of this paper is a new learning algorithm that learns a TrueNorth configuration ready for deployment. We achieve this by training directly a binary hardware crossbar that accommodates the TrueNorth axon configuration constrains and we propose a different neuron model. Results of our approach trained on electroencephalogram (EEG) data show a significant improvement with previous work (76% vs 86% accuracy) while maintaining state of the art performance on the MNIST handwritten data set.
Improving energy efficiency and classification accuracy of neuromorphic chips by learning binary synaptic crossbars
May 25, 2016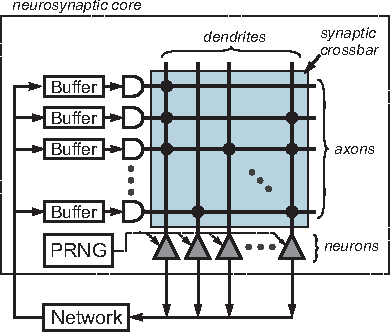
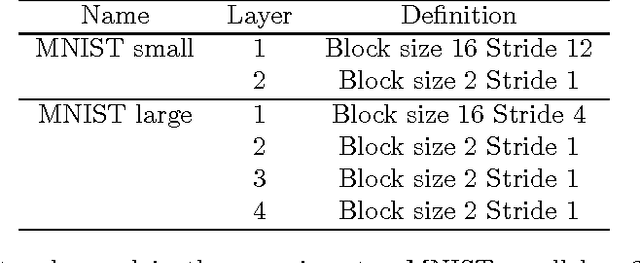
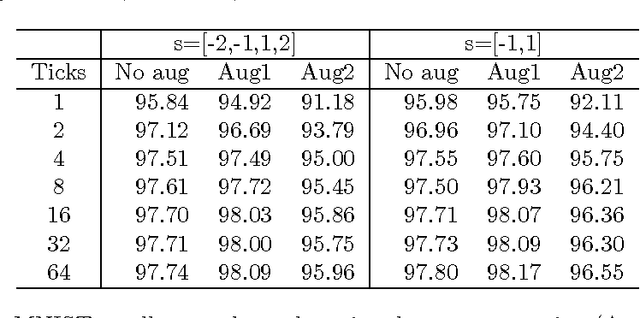
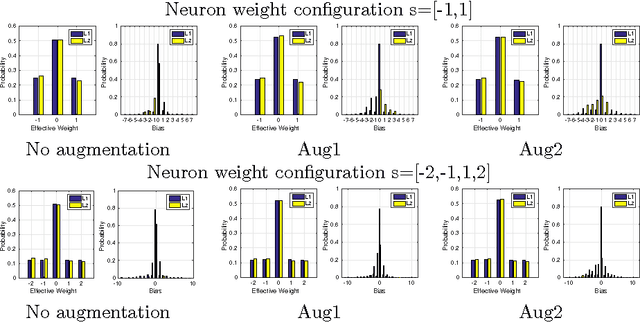
Deep Neural Networks (DNN) have achieved human level performance in many image analytics tasks but DNNs are mostly deployed to GPU platforms that consume a considerable amount of power. Brain-inspired spiking neuromorphic chips consume low power and can be highly parallelized. However, for deploying DNNs to energy efficient neuromorphic chips the incompatibility between continuous neurons and synaptic weights of traditional DNNs, discrete spiking neurons and synapses of neuromorphic chips has to be overcome. Previous work has achieved this by training a network to learn continuous probabilities and deployment to a neuromorphic architecture by random sampling these probabilities. An ensemble of sampled networks is needed to approximate the performance of the trained network. In the work presented in this paper, we have extended previous research by directly learning binary synaptic crossbars. Results on MNIST show that better performance can be achieved with a small network in one time step (92.7% maximum observed accuracy vs 95.98% accuracy in our work). Top results on a larger network are similar to previously published results (99.42% maximum observed accuracy vs 99.45% accuracy in our work). More importantly, in our work a smaller ensemble is needed to achieve similar or better accuracy than previous work, which translates into significantly decreased energy consumption for both networks. Results of our work are stable since they do not require random sampling.