 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePattern-Enhanced RT-DETR for Multi-Class Battery Detection
May 13, 2026Accurate and efficient battery detection is increasingly important for applications in electronic waste recycling, industrial quality control, and automated sorting systems. In this paper, we present both a comprehensive benchmark and a novel method for multi-class battery detection. We systematically compare three CNN-based detectors (YOLOv8n, YOLOv8s, YOLO11n) and two transformer-based detectors (RT-DETR-L, RT-DETR-X) on a publicly available dataset of approximately 8,591 annotated images under identical experimental conditions, and further propose PaQ-RT-DETR, which introduces pattern-based dynamic query generation into RT-DETR to alleviate query activation imbalance with negligible computational overhead. Among baselines, YOLO11n achieves the best CNN-based accuracy (mAP@50: 0.779) at only 2.6M parameters, while YOLOv8n delivers the fastest inference at ~1,667 FPS. PaQ-RT-DETR-X achieves the highest overall mAP@50 of 0.782, surpassing RT-DETR-X by +2.8% with consistent per-class gains across all six battery categories including the data-scarce Bike Battery class. Our findings provide practical guidance for selecting object detection models in battery-related industrial applications.
MedDCR: Learning to Design Agentic Workflows for Medical Coding
Nov 17, 2025Medical coding converts free-text clinical notes into standardized diagnostic and procedural codes, which are essential for billing, hospital operations, and medical research. Unlike ordinary text classification, it requires multi-step reasoning: extracting diagnostic concepts, applying guideline constraints, mapping to hierarchical codebooks, and ensuring cross-document consistency. Recent advances leverage agentic LLMs, but most rely on rigid, manually crafted workflows that fail to capture the nuance and variability of real-world documentation, leaving open the question of how to systematically learn effective workflows. We present MedDCR, a closed-loop framework that treats workflow design as a learning problem. A Designer proposes workflows, a Coder executes them, and a Reflector evaluates predictions and provides constructive feedback, while a memory archive preserves prior designs for reuse and iterative refinement. On benchmark datasets, MedDCR outperforms state-of-the-art baselines and produces interpretable, adaptable workflows that better reflect real coding practice, improving both the reliability and trustworthiness of automated systems.
ICDAR 2021 Competition on Scientific Literature Parsing
Jun 08, 2021
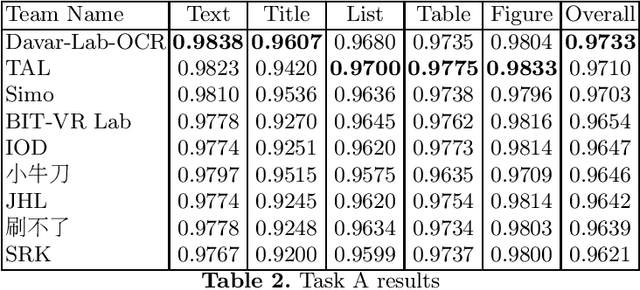
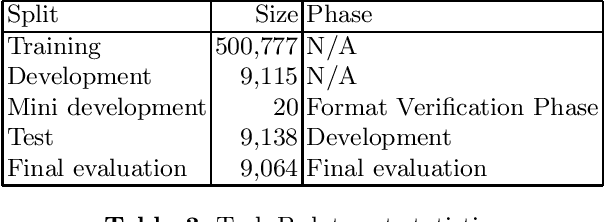
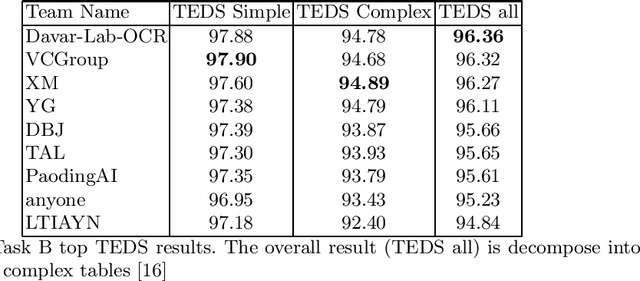
Scientific literature contain important information related to cutting-edge innovations in diverse domains. Advances in natural language processing have been driving the fast development in automated information extraction from scientific literature. However, scientific literature is often available in unstructured PDF format. While PDF is great for preserving basic visual elements, such as characters, lines, shapes, etc., on a canvas for presentation to humans, automatic processing of the PDF format by machines presents many challenges. With over 2.5 trillion PDF documents in existence, these issues are prevalent in many other important application domains as well. Our ICDAR 2021 Scientific Literature Parsing Competition (ICDAR2021-SLP) aims to drive the advances specifically in document understanding. ICDAR2021-SLP leverages the PubLayNet and PubTabNet datasets, which provide hundreds of thousands of training and evaluation examples. In Task A, Document Layout Recognition, submissions with the highest performance combine object detection and specialised solutions for the different categories. In Task B, Table Recognition, top submissions rely on methods to identify table components and post-processing methods to generate the table structure and content. Results from both tasks show an impressive performance and opens the possibility for high performance practical applications.
Grey-box Adversarial Attack And Defence For Sentiment Classification
Mar 22, 2021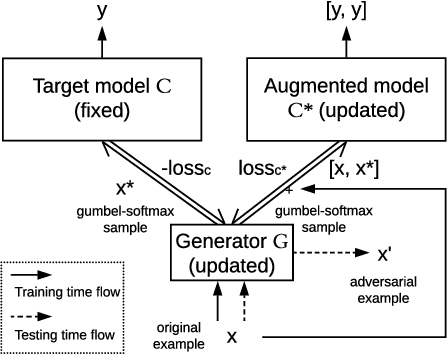
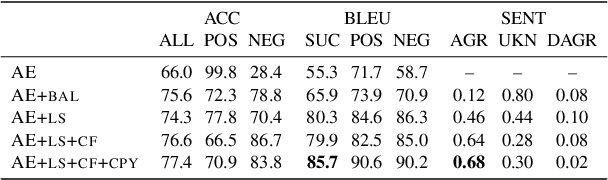
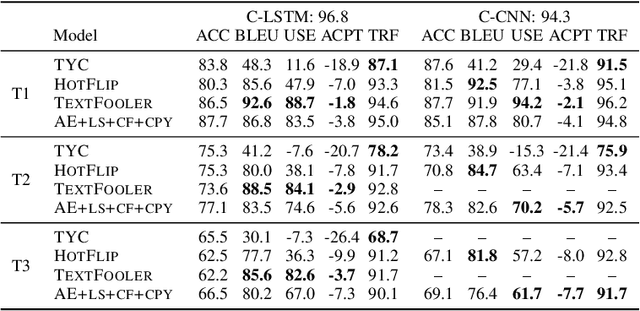
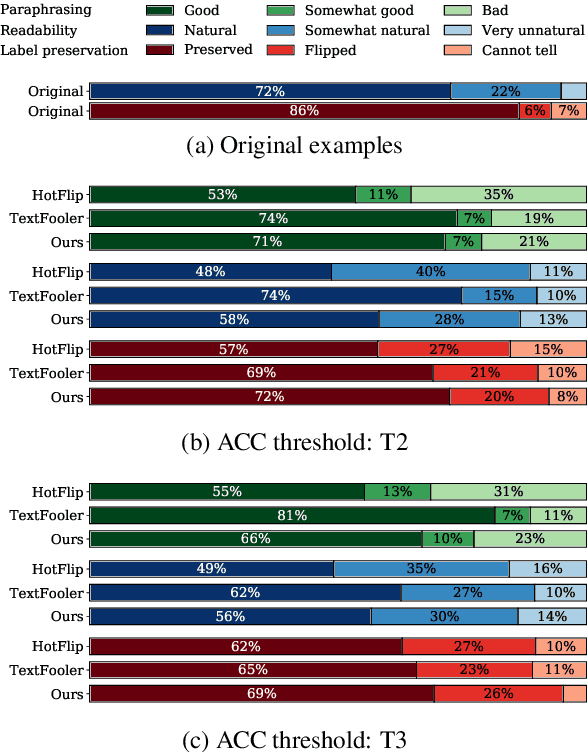
We introduce a grey-box adversarial attack and defence framework for sentiment classification. We address the issues of differentiability, label preservation and input reconstruction for adversarial attack and defence in one unified framework. Our results show that once trained, the attacking model is capable of generating high-quality adversarial examples substantially faster (one order of magnitude less in time) than state-of-the-art attacking methods. These examples also preserve the original sentiment according to human evaluation. Additionally, our framework produces an improved classifier that is robust in defending against multiple adversarial attacking methods. Code is available at: https://github.com/ibm-aur-nlp/adv-def-text-dist.
Elephant in the Room: An Evaluation Framework for Assessing Adversarial Examples in NLP
Jan 22, 2020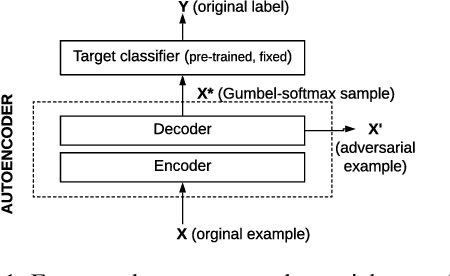

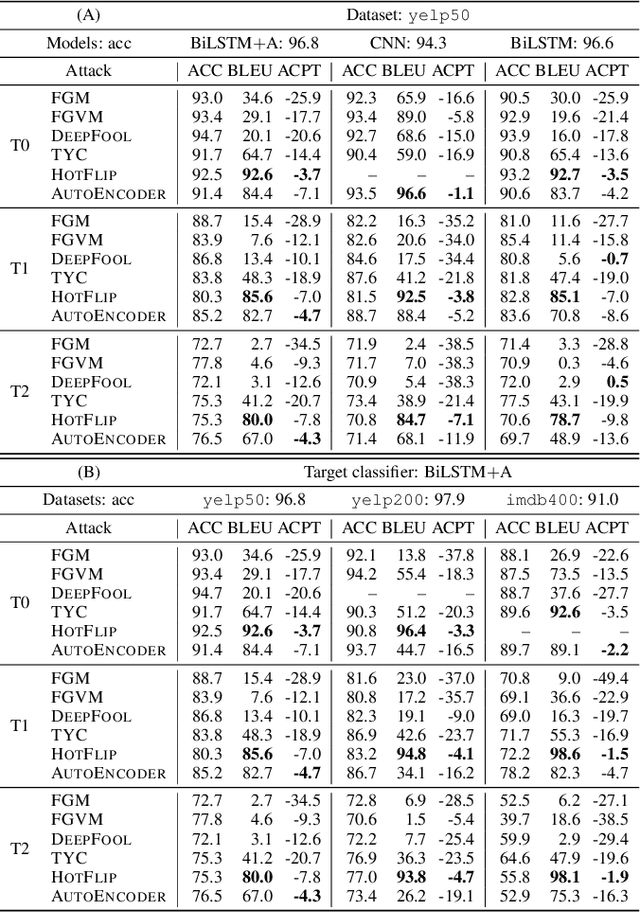
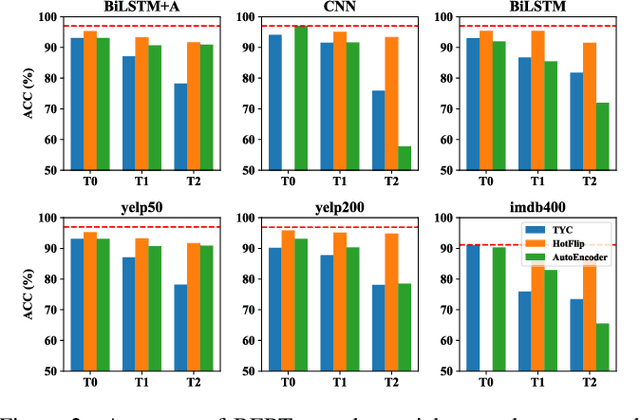
An adversarial example is an input transformed by small perturbations that machine learning models consistently misclassify. While there are a number of methods proposed to generate adversarial examples for text data, it is not trivial to assess the quality of these adversarial examples, as minor perturbations (such as changing a word in a sentence) can lead to a significant shift in their meaning, readability and classification label. In this paper, we propose an evaluation framework to assess the quality of adversarial examples based on the aforementioned properties. We experiment with five benchmark attacking methods and an alternative approach based on an auto-encoder, and found that these methods generate adversarial examples with poor readability and content preservation. We also learned that there are multiple factors that can influence the attacking performance, such as the the length of text examples and the input domain.
Image-based table recognition: data, model, and evaluation
Jan 07, 2020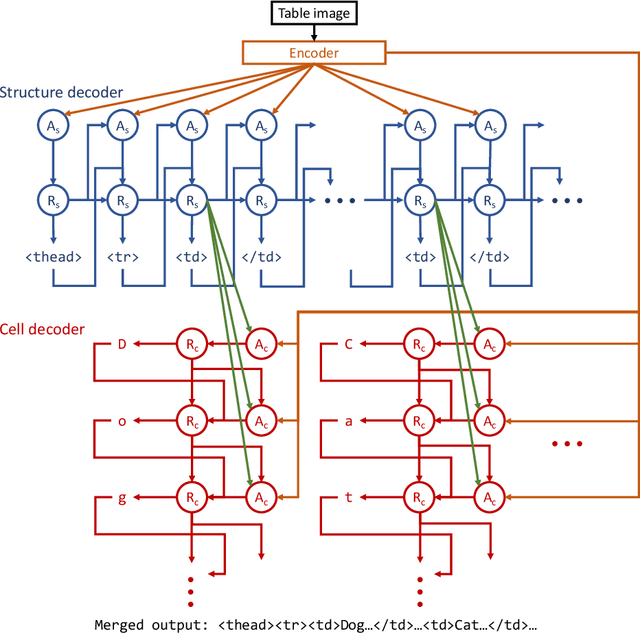
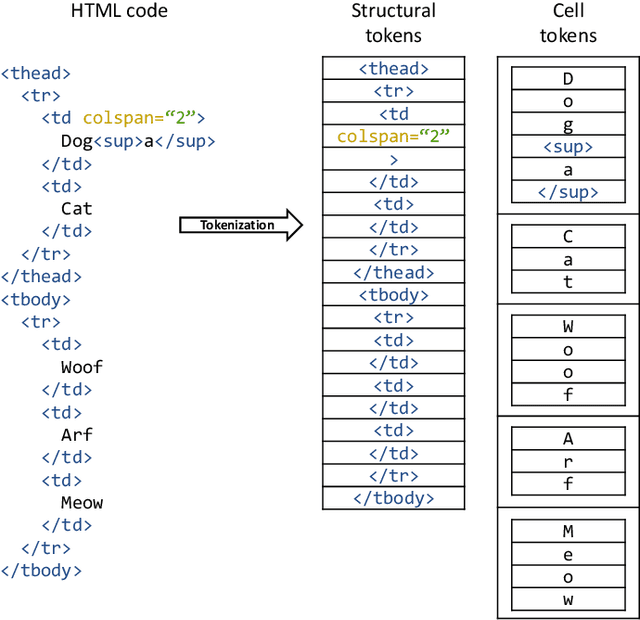
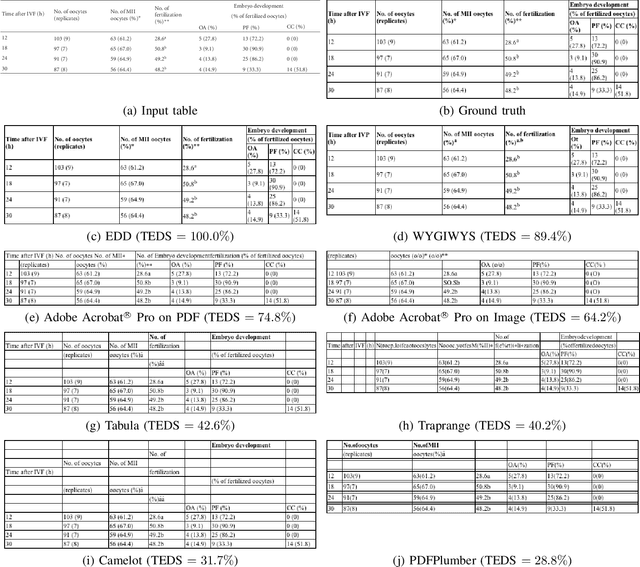

Important information that relates to a specific topic in a document is often organized in tabular format to assist readers with information retrieval and comparison, which may be difficult to provide in natural language. However, tabular data in unstructured digital documents, e.g., Portable Document Format (PDF) and images, are difficult to parse into structured machine-readable format, due to complexity and diversity in their structure and style. To facilitate image-based table recognition with deep learning, we develop the largest publicly available table recognition dataset PubTabNet (https://github.com/ibm-aur-nlp/PubTabNet), containing 568k table images with corresponding structured HTML representation. PubTabNet is automatically generated by matching the XML and PDF representations of the scientific articles in PubMed Central Open Access Subset (PMCOA). We also propose a novel attention-based encoder-dual-decoder (EDD) architecture that converts images of tables into HTML code. The model has a structure decoder which reconstructs the table structure and helps the cell decoder to recognize cell content. In addition, we propose a new Tree-Edit-Distance-based Similarity (TEDS) metric for table recognition. The experiments demonstrate that the EDD model can accurately recognize complex tables solely relying on the image representation, outperforming the state-of-the-art by 9.7% absolute TEDS score.
Global Locality in Event Extraction
Sep 11, 2019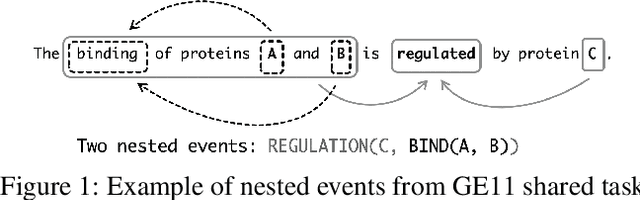
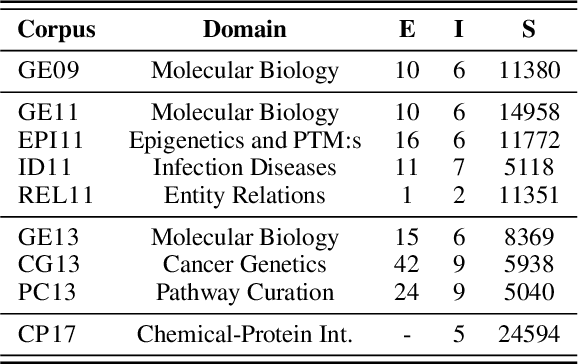
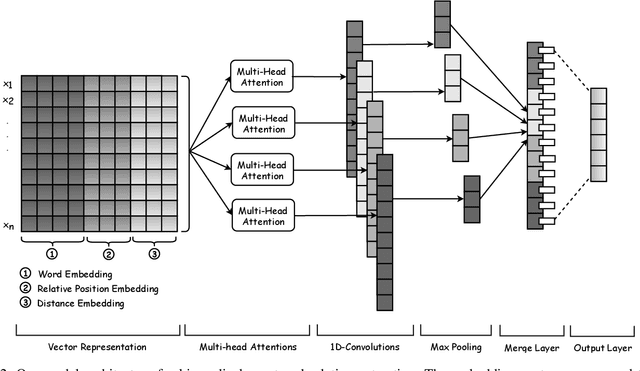
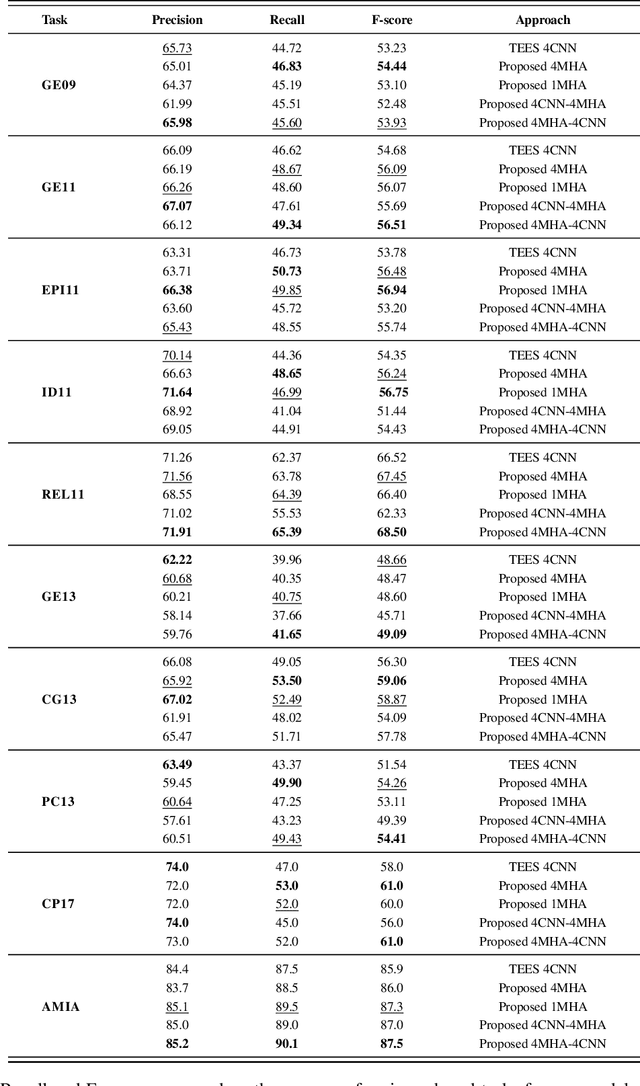
Due to the exponential growth of biomedical literature, event and relation extraction are important tasks in biomedical text mining. Most work in relation extraction detect a single entity pair mention on a short span of text, which is not ideal due to long sentences that appear in biomedical contexts. We propose an approach to both event and relation extraction, for simultaneously predicting relationships between all mention pairs in a text. Our model includes a set of multi-head attentions and convolutions, an adaptation of the transformer architecture, which offers self-attention the ability to strengthen dependencies among related elements, and models the interaction between features extracted by multiple attention heads. Experiment results demonstrate that our approach outperforms the state-of-the-art on a set of benchmark biomedical corpora including BioNLP 2009, 2011, 2013 and BioCreative 2017 shared tasks.
PubLayNet: largest dataset ever for document layout analysis
Aug 16, 2019
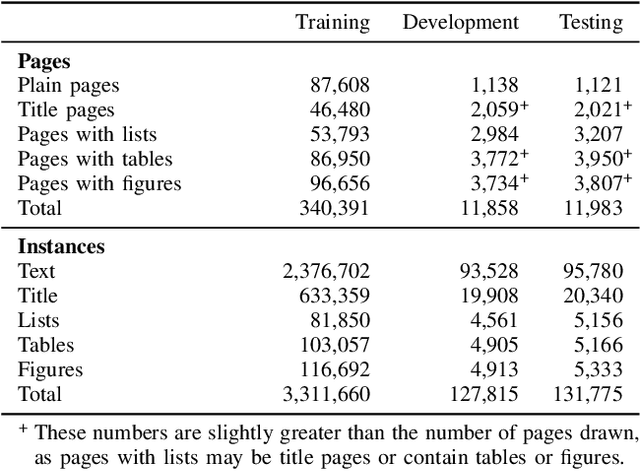

Recognizing the layout of unstructured digital documents is an important step when parsing the documents into structured machine-readable format for downstream applications. Deep neural networks that are developed for computer vision have been proven to be an effective method to analyze layout of document images. However, document layout datasets that are currently publicly available are several magnitudes smaller than established computing vision datasets. Models have to be trained by transfer learning from a base model that is pre-trained on a traditional computer vision dataset. In this paper, we develop the PubLayNet dataset for document layout analysis by automatically matching the XML representations and the content of over 1 million PDF articles that are publicly available on PubMed Central. The size of the dataset is comparable to established computer vision datasets, containing over 360 thousand document images, where typical document layout elements are annotated. The experiments demonstrate that deep neural networks trained on PubLayNet accurately recognize the layout of scientific articles. The pre-trained models are also a more effective base mode for transfer learning on a different document domain. We release the dataset (https://github.com/ibm-aur-nlp/PubLayNet) to support development and evaluation of more advanced models for document layout analysis.