 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElephant in the Room: An Evaluation Framework for Assessing Adversarial Examples in NLP
Paper and Code
Jan 22, 2020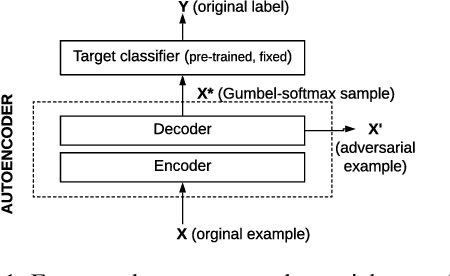

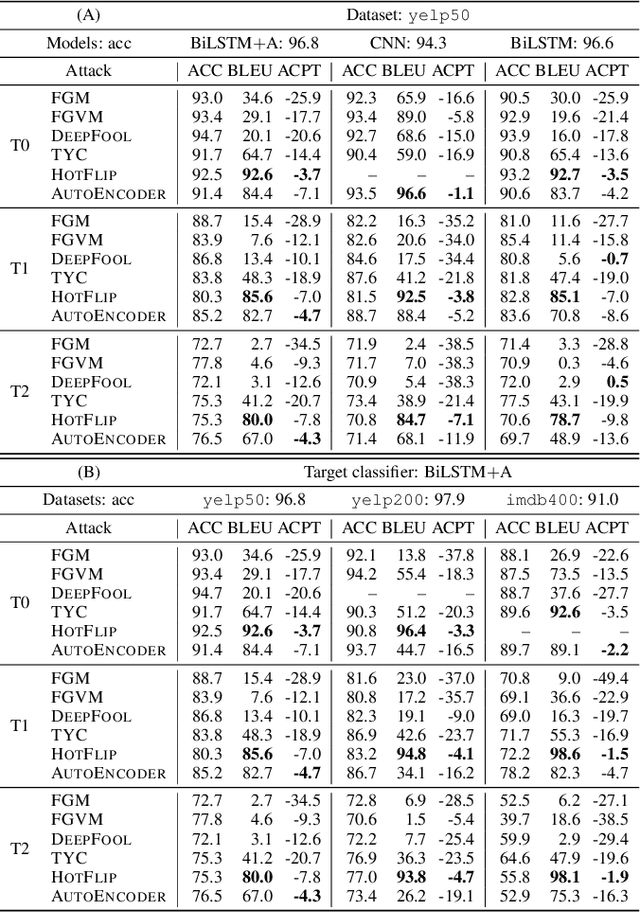
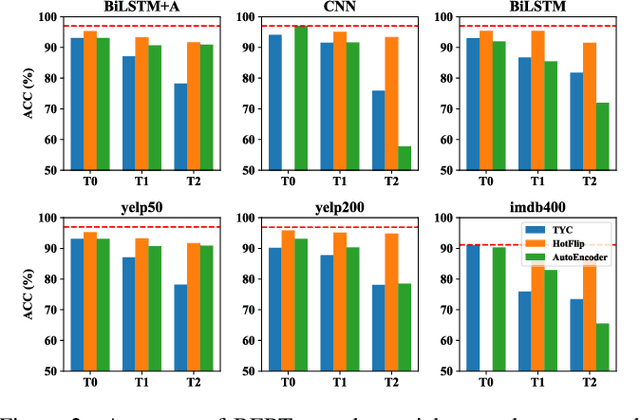
An adversarial example is an input transformed by small perturbations that machine learning models consistently misclassify. While there are a number of methods proposed to generate adversarial examples for text data, it is not trivial to assess the quality of these adversarial examples, as minor perturbations (such as changing a word in a sentence) can lead to a significant shift in their meaning, readability and classification label. In this paper, we propose an evaluation framework to assess the quality of adversarial examples based on the aforementioned properties. We experiment with five benchmark attacking methods and an alternative approach based on an auto-encoder, and found that these methods generate adversarial examples with poor readability and content preservation. We also learned that there are multiple factors that can influence the attacking performance, such as the the length of text examples and the input domain.