 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Impact of the Quality of Textual Data on Feature Representation and Machine Learning Models
Feb 12, 2025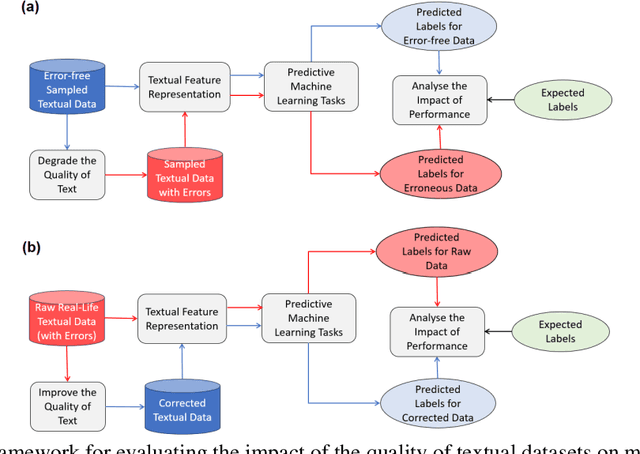
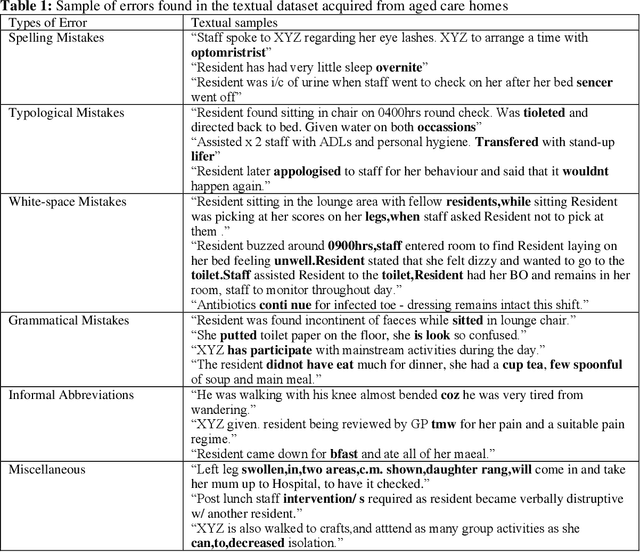
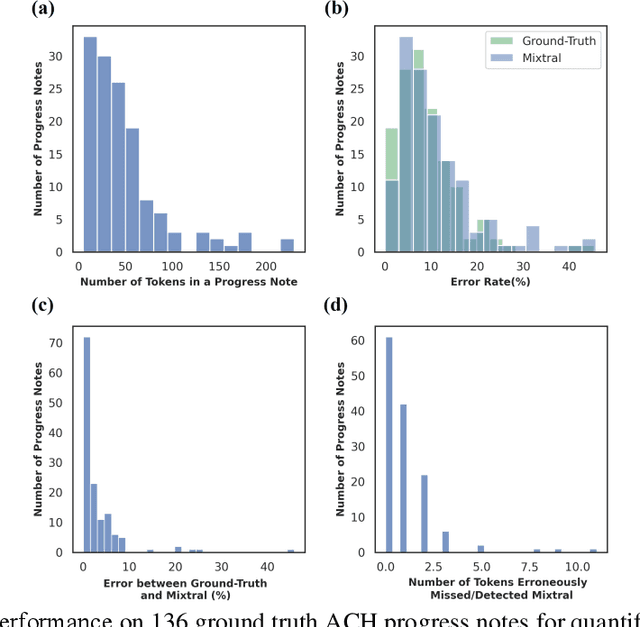
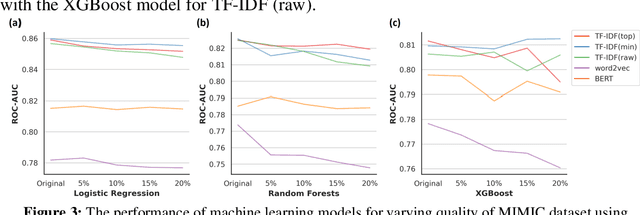
Background: Data collected in controlled settings typically results in high-quality datasets. However, in real-world applications, the quality of data collection is often compromised. It is well established that the quality of a dataset significantly impacts the performance of machine learning models. Methods: A rudimentary error rate metric was developed to evaluate textual dataset quality at the token level. Mixtral Large Language Model (LLM) was used to quantify and correct errors in low quality datasets. The study analyzed two healthcare datasets: the high-quality MIMIC-III public hospital dataset and a lower-quality private dataset from Australian aged care homes. Errors were systematically introduced into MIMIC at varying rates, while the ACH dataset quality was improved using the LLM. Results: For the sampled 35,774 and 6,336 patients from the MIMIC and ACH datasets respectively, we used Mixtral to introduce errors in MIMIC and correct errors in ACH. Mixtral correctly detected errors in 63% of progress notes, with 17% containing a single token misclassified due to medical terminology. LLMs demonstrated potential for improving progress note quality by addressing various errors. Under varying error rates, feature representation performance was tolerant to lower error rates (<10%) but declined significantly at higher rates. Conclusions: The study revealed that models performed relatively well on datasets with lower error rates (<10%), but their performance declined significantly as error rates increased (>=10%). Therefore, it is crucial to evaluate the quality of a dataset before utilizing it for machine learning tasks. For datasets with higher error rates, implementing corrective measures is essential to ensure the reliability and effectiveness of machine learning models.
Elephant in the Room: An Evaluation Framework for Assessing Adversarial Examples in NLP
Jan 22, 2020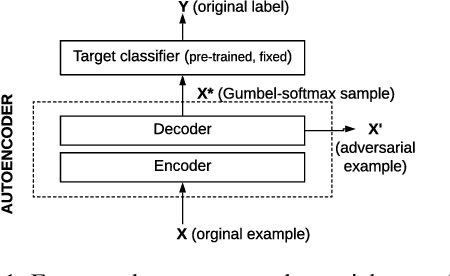

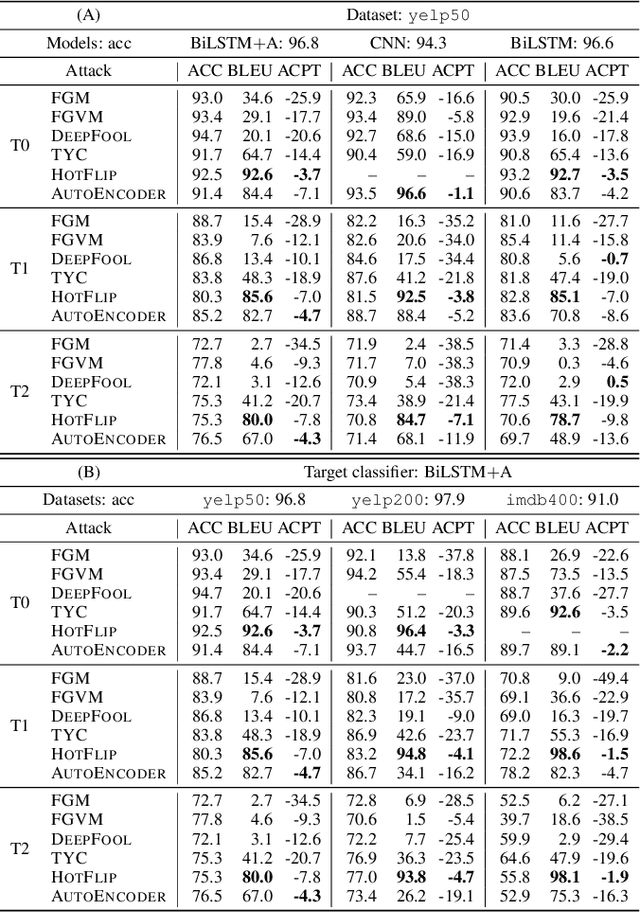
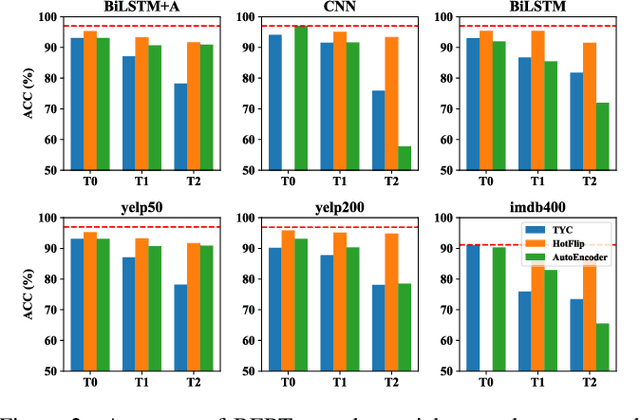
An adversarial example is an input transformed by small perturbations that machine learning models consistently misclassify. While there are a number of methods proposed to generate adversarial examples for text data, it is not trivial to assess the quality of these adversarial examples, as minor perturbations (such as changing a word in a sentence) can lead to a significant shift in their meaning, readability and classification label. In this paper, we propose an evaluation framework to assess the quality of adversarial examples based on the aforementioned properties. We experiment with five benchmark attacking methods and an alternative approach based on an auto-encoder, and found that these methods generate adversarial examples with poor readability and content preservation. We also learned that there are multiple factors that can influence the attacking performance, such as the the length of text examples and the input domain.