 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Light Image Enhancement Challenge at NTIRE 2026
Apr 19, 2026This paper presents a comprehensive review of the NTIRE 2026 Low Light Image Enhancement Challenge, highlighting the proposed solutions and final results. The objective of this challenge is to identify effective networks capable of producing clearer and visually compelling images in diverse and challenging conditions by learning representative visual cues with the purpose of restoring information loss due to low-contrast and noisy images. A total of 195 participants registered for the first track and 153 for the second track of the competition, and 22 teams ultimately submitted valid entries. This paper thoroughly evaluates the state-of-the-art advances in (joint denoising and) low-light image enhancement, showcasing the significant progress in the field, while leveraging samples of our novel dataset.
Dynamic Topology Awareness: Breaking the Granularity Rigidity in Vision-Language Navigation
Jan 29, 2026Vision-Language Navigation in Continuous Environments (VLN-CE) presents a core challenge: grounding high-level linguistic instructions into precise, safe, and long-horizon spatial actions. Explicit topological maps have proven to be a vital solution for providing robust spatial memory in such tasks. However, existing topological planning methods suffer from a "Granularity Rigidity" problem. Specifically, these methods typically rely on fixed geometric thresholds to sample nodes, which fails to adapt to varying environmental complexities. This rigidity leads to a critical mismatch: the model tends to over-sample in simple areas, causing computational redundancy, while under-sampling in high-uncertainty regions, increasing collision risks and compromising precision. To address this, we propose DGNav, a framework for Dynamic Topological Navigation, introducing a context-aware mechanism to modulate map density and connectivity on-the-fly. Our approach comprises two core innovations: (1) A Scene-Aware Adaptive Strategy that dynamically modulates graph construction thresholds based on the dispersion of predicted waypoints, enabling "densification on demand" in challenging environments; (2) A Dynamic Graph Transformer that reconstructs graph connectivity by fusing visual, linguistic, and geometric cues into dynamic edge weights, enabling the agent to filter out topological noise and enhancing instruction adherence. Extensive experiments on the R2R-CE and RxR-CE benchmarks demonstrate DGNav exhibits superior navigation performance and strong generalization capabilities. Furthermore, ablation studies confirm that our framework achieves an optimal trade-off between navigation efficiency and safe exploration. The code is available at https://github.com/shannanshouyin/DGNav.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Real-time CARFAC Cochlea Model Acceleration on FPGA for Underwater Acoustic Sensing Systems
Aug 11, 2025This paper presents a real-time, energy-efficient embedded system implementing an array of Cascade of Asymmetric Resonators with Fast-Acting Compression (CARFAC) cochlea models for underwater sound analysis. Built on the AMD Kria KV260 System-on-Module (SoM), the system integrates a Rust-based software framework on the processor for real-time interfacing and synchronization with multiple hydrophone inputs, and a hardware-accelerated implementation of the CARFAC models on a Field-Programmable Gate Array (FPGA) for real-time sound pre-processing. Compared to prior work, the CARFAC accelerator achieves improved scalability and processing speed while reducing resource usage through optimized time-multiplexing, pipelined design, and elimination of costly division circuits. Experimental results demonstrate 13.5% hardware utilization for a single 64-channel CARFAC instance and a whole board power consumption of 3.11 W when processing a 256 kHz input signal in real time.
Multi-Agent-as-Judge: Aligning LLM-Agent-Based Automated Evaluation with Multi-Dimensional Human Evaluation
Jul 28, 2025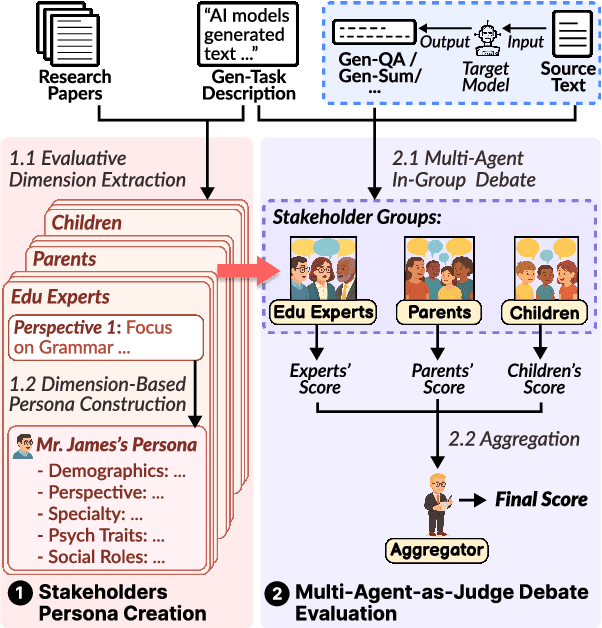



Nearly all human work is collaborative; thus, the evaluation of real-world NLP applications often requires multiple dimensions that align with diverse human perspectives. As real human evaluator resources are often scarce and costly, the emerging "LLM-as-a-judge" paradigm sheds light on a promising approach to leverage LLM agents to believably simulate human evaluators. Yet, to date, existing LLM-as-a-judge approaches face two limitations: persona descriptions of agents are often arbitrarily designed, and the frameworks are not generalizable to other tasks. To address these challenges, we propose MAJ-EVAL, a Multi-Agent-as-Judge evaluation framework that can automatically construct multiple evaluator personas with distinct dimensions from relevant text documents (e.g., research papers), instantiate LLM agents with the personas, and engage in-group debates with multi-agents to Generate multi-dimensional feedback. Our evaluation experiments in both the educational and medical domains demonstrate that MAJ-EVAL can generate evaluation results that better align with human experts' ratings compared with conventional automated evaluation metrics and existing LLM-as-a-judge methods.
A Hierarchical Probabilistic Framework for Incremental Knowledge Tracing in Classroom Settings
Jun 11, 2025Knowledge tracing (KT) aims to estimate a student's evolving knowledge state and predict their performance on new exercises based on performance history. Many realistic classroom settings for KT are typically low-resource in data and require online updates as students' exercise history grows, which creates significant challenges for existing KT approaches. To restore strong performance under low-resource conditions, we revisit the hierarchical knowledge concept (KC) information, which is typically available in many classroom settings and can provide strong prior when data are sparse. We therefore propose Knowledge-Tree-based Knowledge Tracing (KT$^2$), a probabilistic KT framework that models student understanding over a tree-structured hierarchy of knowledge concepts using a Hidden Markov Tree Model. KT$^2$ estimates student mastery via an EM algorithm and supports personalized prediction through an incremental update mechanism as new responses arrive. Our experiments show that KT$^2$ consistently outperforms strong baselines in realistic online, low-resource settings.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
VoD: Learning Volume of Differences for Video-Based Deepfake Detection
Mar 10, 2025



The rapid development of deep learning and generative AI technologies has profoundly transformed the digital contact landscape, creating realistic Deepfake that poses substantial challenges to public trust and digital media integrity. This paper introduces a novel Deepfake detention framework, Volume of Differences (VoD), designed to enhance detection accuracy by exploiting temporal and spatial inconsistencies between consecutive video frames. VoD employs a progressive learning approach that captures differences across multiple axes through the use of consecutive frame differences (CFD) and a network with stepwise expansions. We evaluate our approach with intra-dataset and cross-dataset testing scenarios on various well-known Deepfake datasets. Our findings demonstrate that VoD excels with the data it has been trained on and shows strong adaptability to novel, unseen data. Additionally, comprehensive ablation studies examine various configurations of segment length, sampling steps, and intervals, offering valuable insights for optimizing the framework. The code for our VoD framework is available at https://github.com/xuyingzhongguo/VoD.
Adaptive Multi-Objective Bayesian Optimization for Capacity Planning of Hybrid Heat Sources in Electric-Heat Coupling Systems of Cold Regions
Feb 13, 2025The traditional heat-load generation pattern of combined heat and power generators has become a problem leading to renewable energy source (RES) power curtailment in cold regions, motivating the proposal of a planning model for alternative heat sources. The model aims to identify non-dominant capacity allocation schemes for heat pumps, thermal energy storage, electric boilers, and combined storage heaters to construct a Pareto front, considering both economic and sustainable objectives. The integration of various heat sources from both generation and consumption sides enhances flexibility in utilization. The study introduces a novel optimization algorithm, the adaptive multi-objective Bayesian optimization (AMBO). Compared to other widely used multi-objective optimization algorithms, AMBO eliminates predefined parameters that may introduce subjectivity from planners. Beyond the algorithm, the proposed model incorporates a noise term to account for inevitable simulation deviations, enabling the identification of better-performing planning results that meet the unique requirements of cold regions. What's more, the characteristics of electric-thermal coupling scenarios are captured and reflected in the operation simulation model to make sure the simulation is close to reality. Numerical simulation verifies the superiority of the proposed approach in generating a more diverse and evenly distributed Pareto front in a sample-efficient manner, providing comprehensive and objective planning choices.
Noise-Aware Bayesian Optimization Approach for Capacity Planning of the Distributed Energy Resources in an Active Distribution Network
Dec 11, 2024The growing penetration of renewable energy sources (RESs) in active distribution networks (ADNs) leads to complex and uncertain operation scenarios, resulting in significant deviations and risks for the ADN operation. In this study, a collaborative capacity planning of the distributed energy resources in an ADN is proposed to enhance the RES accommodation capability. The variability of RESs, characteristics of adjustable demand response resources, ADN bi-directional power flow, and security operation limitations are considered in the proposed model. To address the noise term caused by the inevitable deviation between the operation simulation and real-world environments, an improved noise-aware Bayesian optimization algorithm with the probabilistic surrogate model is proposed to overcome the interference from the environmental noise and sample-efficiently optimize the capacity planning model under noisy circumstances. Numerical simulation results verify the superiority of the proposed approach in coping with environmental noise and achieving lower annual cost and higher computation efficiency.