 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR Challenge 2026: Robust Audio Deepfake Recognition under Media Transformations
May 10, 2026RADAR Challenge 2026 is an APSIPA Grand Challenge on Robust Audio Deepfake Recognition under Media Transformations, designed to simulate realistic media conditions in real-world audio distribution pipelines, including compression, resampling, noise, and reverberation. It consists of two phases: an English development phase with labeled data for analysis and paper writing, and a multilingual evaluation phase containing more than 100,000 utterances in English, Singapore English, Mandarin Chinese, Taiwanese Mandarin, Japanese, and Vietnamese. Systems are evaluated using equal error rate (EER) for binary real/fake classification. This paper describes the challenge task, the construction of the data set, the evaluation protocol, and the overall results. During the challenge, 33 teams submitted to the development phase and 22 teams submitted to the final evaluation phase. The reported results highlight the remaining challenges of robust audio deepfake detection under multilingual and media-transformed conditions.
Evaluating Time Awareness and Cross-modal Active Perception of Large Models via 4D Escape Room Task
Mar 16, 2026Multimodal Large Language Models (MLLMs) have recently made rapid progress toward unified Omni models that integrate vision, language, and audio. However, existing environments largely focus on 2D or 3D visual context and vision-language tasks, offering limited support for temporally dependent auditory signals and selective cross-modal integration, where different modalities may provide complementary or interfering information, which are essential capabilities for realistic multimodal reasoning. As a result, whether models can actively coordinate modalities and reason under time-varying, irreversible conditions remains underexplored. To this end, we introduce \textbf{EscapeCraft-4D}, a customizable 4D environment for assessing selective cross-modal perception and time awareness in Omni models. It incorporates trigger-based auditory sources, temporally transient evidence, and location-dependent cues, requiring agents to perform spatio-temporal reasoning and proactive multimodal integration under time constraints. Building on this environment, we curate a benchmark to evaluate corresponding abilities across powerful models. Evaluation results suggest that models struggle with modality bias, and reveal significant gaps in current model's ability to integrate multiple modalities under time constraints. Further in-depth analysis uncovers how multiple modalities interact and jointly influence model decisions in complex multimodal reasoning environments.
Deepfake Word Detection by Next-token Prediction using Fine-tuned Whisper
Feb 26, 2026Deepfake speech utterances can be forged by replacing one or more words in a bona fide utterance with semantically different words synthesized by speech generative models. While a dedicated synthetic word detector could be developed, we investigate a cost-effective method that fine-tunes a pre-trained Whisper model to detect synthetic words while transcribing the input utterance via next-token prediction. We further investigate using partially vocoded utterances as the fine-tuning data, thereby reducing the cost of data collection. Our experiments demonstrate that, on in-domain test data, the fine-tuned Whisper yields low synthetic-word detection error rates and transcription error rates. On out-of-domain test data with synthetic words produced by unseen speech generative models, the fine-tuned Whisper remains on par with a dedicated ResNet-based detection model; however, the overall performance degradation calls for strategies to improve its generalization capability.
ASVspoof 5: Evaluation of Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Jan 07, 2026ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake detection solutions. A significant change from previous challenge editions is a new crowdsourced database collected from a substantially greater number of speakers under diverse recording conditions, and a mix of cutting-edge and legacy generative speech technology. With the new database described elsewhere, we provide in this paper an overview of the ASVspoof 5 challenge results for the submissions of 53 participating teams. While many solutions perform well, performance degrades under adversarial attacks and the application of neural encoding/compression schemes. Together with a review of post-challenge results, we also report a study of calibration in addition to other principal challenges and outline a road-map for the future of ASVspoof.
Enabling MoE on the Edge via Importance-Driven Expert Scheduling
Aug 26, 2025



The Mixture of Experts (MoE) architecture has emerged as a key technique for scaling Large Language Models by activating only a subset of experts per query. Deploying MoE on consumer-grade edge hardware, however, is constrained by limited device memory, making dynamic expert offloading essential. Unlike prior work that treats offloading purely as a scheduling problem, we leverage expert importance to guide decisions, substituting low-importance activated experts with functionally similar ones already cached in GPU memory, thereby preserving accuracy. As a result, this design reduces memory usage and data transfer, while largely eliminating PCIe overhead. In addition, we introduce a scheduling policy that maximizes the reuse ratio of GPU-cached experts, further boosting efficiency. Extensive evaluations show that our approach delivers 48% lower decoding latency with over 60% expert cache hit rate, while maintaining nearly lossless accuracy.
From Sharpness to Better Generalization for Speech Deepfake Detection
Jun 13, 2025Generalization remains a critical challenge in speech deepfake detection (SDD). While various approaches aim to improve robustness, generalization is typically assessed through performance metrics like equal error rate without a theoretical framework to explain model performance. This work investigates sharpness as a theoretical proxy for generalization in SDD. We analyze how sharpness responds to domain shifts and find it increases in unseen conditions, indicating higher model sensitivity. Based on this, we apply Sharpness-Aware Minimization (SAM) to reduce sharpness explicitly, leading to better and more stable performance across diverse unseen test sets. Furthermore, correlation analysis confirms a statistically significant relationship between sharpness and generalization in most test settings. These findings suggest that sharpness can serve as a theoretical indicator for generalization in SDD and that sharpness-aware training offers a promising strategy for improving robustness.
A Hierarchical Probabilistic Framework for Incremental Knowledge Tracing in Classroom Settings
Jun 11, 2025Knowledge tracing (KT) aims to estimate a student's evolving knowledge state and predict their performance on new exercises based on performance history. Many realistic classroom settings for KT are typically low-resource in data and require online updates as students' exercise history grows, which creates significant challenges for existing KT approaches. To restore strong performance under low-resource conditions, we revisit the hierarchical knowledge concept (KC) information, which is typically available in many classroom settings and can provide strong prior when data are sparse. We therefore propose Knowledge-Tree-based Knowledge Tracing (KT$^2$), a probabilistic KT framework that models student understanding over a tree-structured hierarchy of knowledge concepts using a Hidden Markov Tree Model. KT$^2$ estimates student mastery via an EM algorithm and supports personalized prediction through an incremental update mechanism as new responses arrive. Our experiments show that KT$^2$ consistently outperforms strong baselines in realistic online, low-resource settings.
Quantifying Source Speaker Leakage in One-to-One Voice Conversion
Apr 22, 2025
Using a multi-accented corpus of parallel utterances for use with commercial speech devices, we present a case study to show that it is possible to quantify a degree of confidence about a source speaker's identity in the case of one-to-one voice conversion. Following voice conversion using a HiFi-GAN vocoder, we compare information leakage for a range speaker characteristics; assuming a "worst-case" white-box scenario, we quantify our confidence to perform inference and narrow the pool of likely source speakers, reinforcing the regulatory obligation and moral duty that providers of synthetic voices have to ensure the privacy of their speakers' data.
ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Feb 13, 2025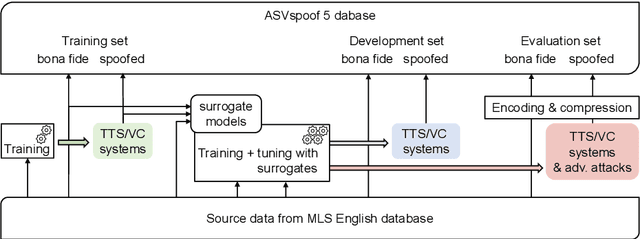

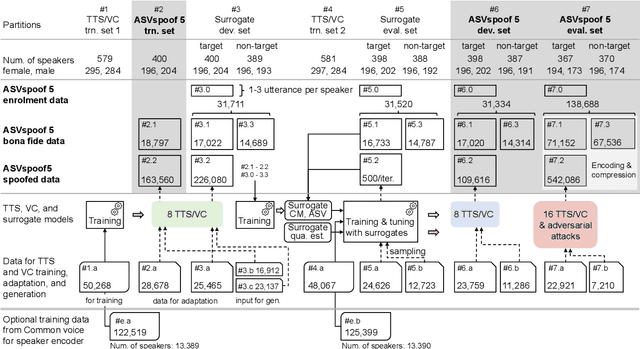
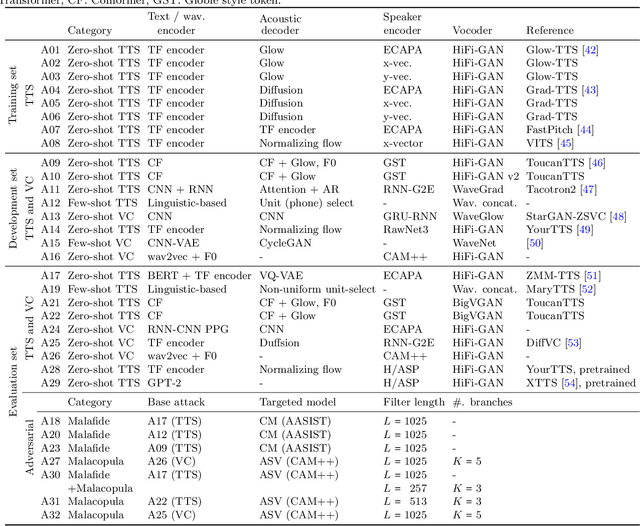
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake attacks as well as the design of detection solutions. We introduce the ASVspoof 5 database which is generated in crowdsourced fashion from data collected in diverse acoustic conditions (cf. studio-quality data for earlier ASVspoof databases) and from ~2,000 speakers (cf. ~100 earlier). The database contains attacks generated with 32 different algorithms, also crowdsourced, and optimised to varying degrees using new surrogate detection models. Among them are attacks generated with a mix of legacy and contemporary text-to-speech synthesis and voice conversion models, in addition to adversarial attacks which are incorporated for the first time. ASVspoof 5 protocols comprise seven speaker-disjoint partitions. They include two distinct partitions for the training of different sets of attack models, two more for the development and evaluation of surrogate detection models, and then three additional partitions which comprise the ASVspoof 5 training, development and evaluation sets. An auxiliary set of data collected from an additional 30k speakers can also be used to train speaker encoders for the implementation of attack algorithms. Also described herein is an experimental validation of the new ASVspoof 5 database using a set of automatic speaker verification and spoof/deepfake baseline detectors. With the exception of protocols and tools for the generation of spoofed/deepfake speech, the resources described in this paper, already used by participants of the ASVspoof 5 challenge in 2024, are now all freely available to the community.
Explaining Speaker and Spoof Embeddings via Probing
Dec 24, 2024



This study investigates the explainability of embedding representations, specifically those used in modern audio spoofing detection systems based on deep neural networks, known as spoof embeddings. Building on established work in speaker embedding explainability, we examine how well these spoof embeddings capture speaker-related information. We train simple neural classifiers using either speaker or spoof embeddings as input, with speaker-related attributes as target labels. These attributes are categorized into two groups: metadata-based traits (e.g., gender, age) and acoustic traits (e.g., fundamental frequency, speaking rate). Our experiments on the ASVspoof 2019 LA evaluation set demonstrate that spoof embeddings preserve several key traits, including gender, speaking rate, F0, and duration. Further analysis of gender and speaking rate indicates that the spoofing detector partially preserves these traits, potentially to ensure the decision process remains robust against them.