 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Source Speaker Leakage in One-to-One Voice Conversion
Apr 22, 2025
Using a multi-accented corpus of parallel utterances for use with commercial speech devices, we present a case study to show that it is possible to quantify a degree of confidence about a source speaker's identity in the case of one-to-one voice conversion. Following voice conversion using a HiFi-GAN vocoder, we compare information leakage for a range speaker characteristics; assuming a "worst-case" white-box scenario, we quantify our confidence to perform inference and narrow the pool of likely source speakers, reinforcing the regulatory obligation and moral duty that providers of synthetic voices have to ensure the privacy of their speakers' data.
Performance of data-driven inner speech decoding with same-task EEG-fMRI data fusion and bimodal models
Jun 19, 2023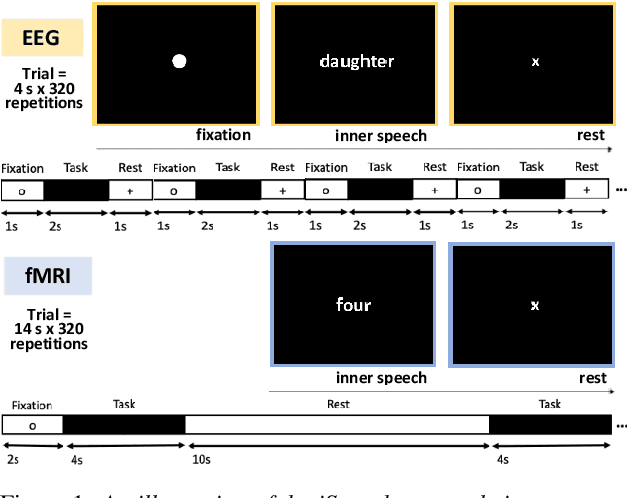
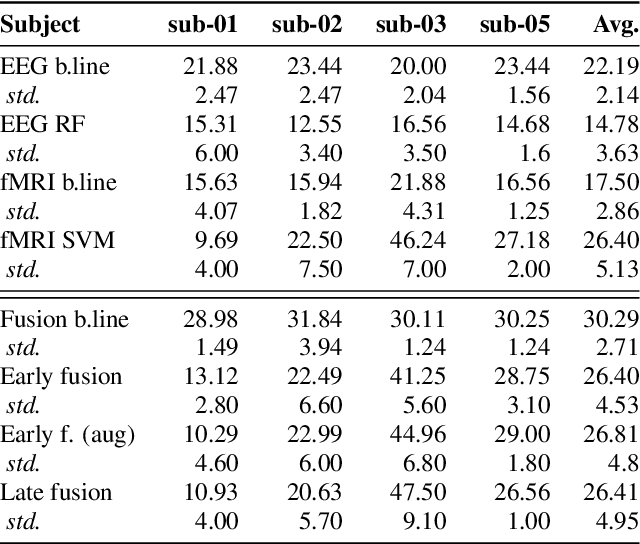
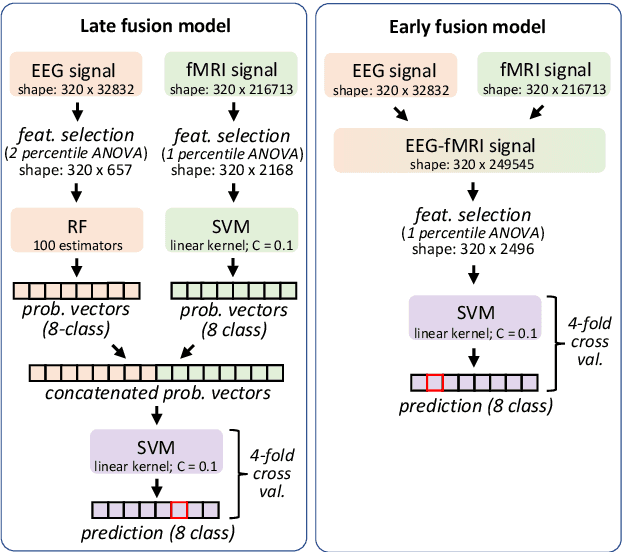
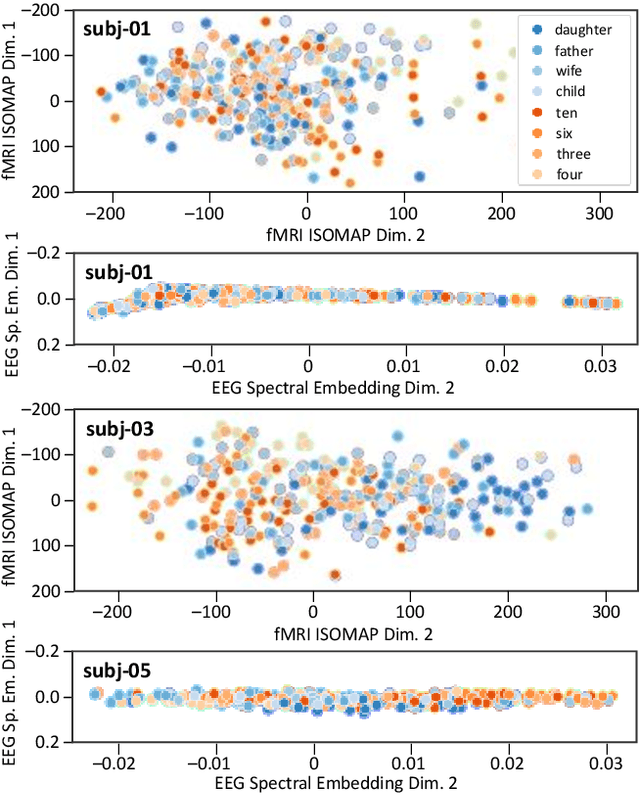
Decoding inner speech from the brain signal via hybridisation of fMRI and EEG data is explored to investigate the performance benefits over unimodal models. Two different bimodal fusion approaches are examined: concatenation of probability vectors output from unimodal fMRI and EEG machine learning models, and data fusion with feature engineering. Same task inner speech data are recorded from four participants, and different processing strategies are compared and contrasted to previously-employed hybridisation methods. Data across participants are discovered to encode different underlying structures, which results in varying decoding performances between subject-dependent fusion models. Decoding performance is demonstrated as improved when pursuing bimodal fMRI-EEG fusion strategies, if the data show underlying structure.