 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModified TSception for Analyzing Driver Drowsiness and Mental Workload from EEG
Dec 25, 2025Driver drowsiness remains a primary cause of traffic accidents, necessitating the development of real-time, reliable detection systems to ensure road safety. This study presents a Modified TSception architecture designed for the robust assessment of driver fatigue using Electroencephalography (EEG). The model introduces a novel hierarchical architecture that surpasses the original TSception by implementing a five-layer temporal refinement strategy to capture multi-scale brain dynamics. A key innovation is the use of Adaptive Average Pooling, which provides the structural flexibility to handle varying EEG input dimensions, and a two - stage fusion mechanism that optimizes the integration of spatiotemporal features for improved stability. When evaluated on the SEED-VIG dataset and compared against established methods - including SVM, Transformer, EEGNet, ConvNeXt, LMDA-Net, and the original TSception - the Modified TSception achieves a comparable accuracy of 83.46% (vs. 83.15% for the original). Critically, the proposed model exhibits a substantially reduced confidence interval (0.24 vs. 0.36), signifying a marked improvement in performance stability. Furthermore, the architecture's generalizability is validated on the STEW mental workload dataset, where it achieves state-of-the-art results with 95.93% and 95.35% accuracy for 2-class and 3-class classification, respectively. These improvements in consistency and cross-task generalizability underscore the effectiveness of the proposed modifications for reliable EEG-based monitoring of drowsiness and mental workload.
Meta-Sparsity: Learning Optimal Sparse Structures in Multi-task Networks through Meta-learning
Jan 21, 2025This paper presents meta-sparsity, a framework for learning model sparsity, basically learning the parameter that controls the degree of sparsity, that allows deep neural networks (DNNs) to inherently generate optimal sparse shared structures in multi-task learning (MTL) setting. This proposed approach enables the dynamic learning of sparsity patterns across a variety of tasks, unlike traditional sparsity methods that rely heavily on manual hyperparameter tuning. Inspired by Model Agnostic Meta-Learning (MAML), the emphasis is on learning shared and optimally sparse parameters in multi-task scenarios by implementing a penalty-based, channel-wise structured sparsity during the meta-training phase. This method improves the model's efficacy by removing unnecessary parameters and enhances its ability to handle both seen and previously unseen tasks. The effectiveness of meta-sparsity is rigorously evaluated by extensive experiments on two datasets, NYU-v2 and CelebAMask-HQ, covering a broad spectrum of tasks ranging from pixel-level to image-level predictions. The results show that the proposed approach performs well across many tasks, indicating its potential as a versatile tool for creating efficient and adaptable sparse neural networks. This work, therefore, presents an approach towards learning sparsity, contributing to the efforts in the field of sparse neural networks and suggesting new directions for research towards parsimonious models.
Giving each task what it needs -- leveraging structured sparsity for tailored multi-task learning
Jun 05, 2024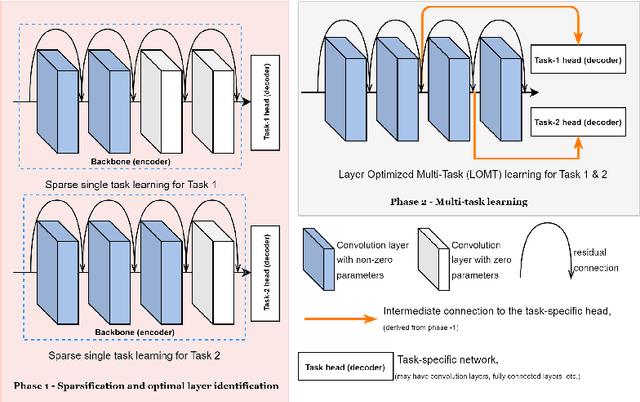
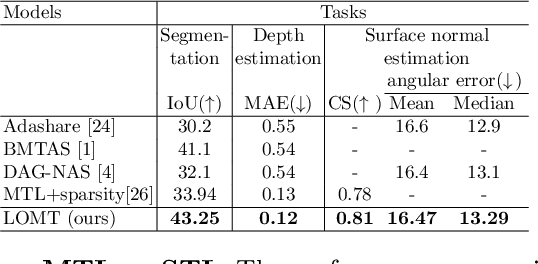


Every task demands distinct feature representations, ranging from low-level to high-level attributes, so it is vital to address the specific needs of each task, especially in the Multi-task Learning (MTL) framework. This work, therefore, introduces Layer-Optimized Multi-Task (LOMT) models that utilize structured sparsity to refine feature selection for individual tasks and enhance the performance of all tasks in a multi-task scenario. Structured or group sparsity systematically eliminates parameters from trivial channels and, eventually, entire layers within a convolution neural network during training. Consequently, the remaining layers provide the most optimal features for a given task. In this two-step approach, we subsequently leverage this sparsity-induced optimal layer information to build the LOMT models by connecting task-specific decoders to these strategically identified layers, deviating from conventional approaches that uniformly connect decoders at the end of the network. This tailored architecture optimizes the network, focusing on essential features while reducing redundancy. We validate the efficacy of the proposed approach on two datasets, ie NYU-v2 and CelebAMask-HD datasets, for multiple heterogeneous tasks. A detailed performance analysis of the LOMT models, in contrast to the conventional MTL models, reveals that the LOMT models outperform for most task combinations. The excellent qualitative and quantitative outcomes highlight the effectiveness of employing structured sparsity for optimal layer (or feature) selection.
Vehicle Detection Performance in Nordic Region
Mar 22, 2024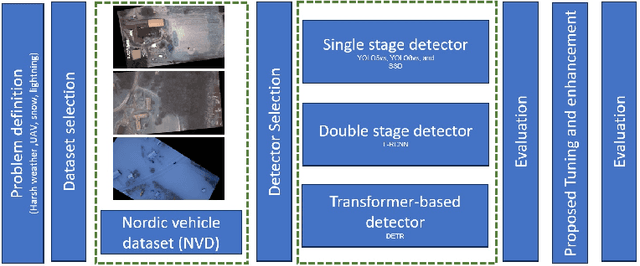



This paper addresses the critical challenge of vehicle detection in the harsh winter conditions in the Nordic regions, characterized by heavy snowfall, reduced visibility, and low lighting. Due to their susceptibility to environmental distortions and occlusions, traditional vehicle detection methods have struggled in these adverse conditions. The advanced proposed deep learning architectures brought promise, yet the unique difficulties of detecting vehicles in Nordic winters remain inadequately addressed. This study uses the Nordic Vehicle Dataset (NVD), which has UAV images from northern Sweden, to evaluate the performance of state-of-the-art vehicle detection algorithms under challenging weather conditions. Our methodology includes a comprehensive evaluation of single-stage, two-stage, and transformer-based detectors against the NVD. We propose a series of enhancements tailored to each detection framework, including data augmentation, hyperparameter tuning, transfer learning, and novel strategies designed explicitly for the DETR model. Our findings not only highlight the limitations of current detection systems in the Nordic environment but also offer promising directions for enhancing these algorithms for improved robustness and accuracy in vehicle detection amidst the complexities of winter landscapes. The code and the dataset are available at https://nvd.ltu-ai.dev
Less is More -- Towards parsimonious multi-task models using structured sparsity
Aug 31, 2023Model sparsification in deep learning promotes simpler, more interpretable models with fewer parameters. This not only reduces the model's memory footprint and computational needs but also shortens inference time. This work focuses on creating sparse models optimized for multiple tasks with fewer parameters. These parsimonious models also possess the potential to match or outperform dense models in terms of performance. In this work, we introduce channel-wise l1/l2 group sparsity in the shared convolutional layers parameters (or weights) of the multi-task learning model. This approach facilitates the removal of extraneous groups i.e., channels (due to l1 regularization) and also imposes a penalty on the weights, further enhancing the learning efficiency for all tasks (due to l2 regularization). We analyzed the results of group sparsity in both single-task and multi-task settings on two widely-used Multi-Task Learning (MTL) datasets: NYU-v2 and CelebAMask-HQ. On both datasets, which consist of three different computer vision tasks each, multi-task models with approximately 70% sparsity outperform their dense equivalents. We also investigate how changing the degree of sparsification influences the model's performance, the overall sparsity percentage, the patterns of sparsity, and the inference time.
Can Self-Supervised Representation Learning Methods Withstand Distribution Shifts and Corruptions?
Aug 11, 2023Self-supervised learning in computer vision aims to leverage the inherent structure and relationships within data to learn meaningful representations without explicit human annotation, enabling a holistic understanding of visual scenes. Robustness in vision machine learning ensures reliable and consistent performance, enhancing generalization, adaptability, and resistance to noise, variations, and adversarial attacks. Self-supervised paradigms, namely contrastive learning, knowledge distillation, mutual information maximization, and clustering, have been considered to have shown advances in invariant learning representations. This work investigates the robustness of learned representations of self-supervised learning approaches focusing on distribution shifts and image corruptions in computer vision. Detailed experiments have been conducted to study the robustness of self-supervised learning methods on distribution shifts and image corruptions. The empirical analysis demonstrates a clear relationship between the performance of learned representations within self-supervised paradigms and the severity of distribution shifts and corruptions. Notably, higher levels of shifts and corruptions are found to significantly diminish the robustness of the learned representations. These findings highlight the critical impact of distribution shifts and image corruptions on the performance and resilience of self-supervised learning methods, emphasizing the need for effective strategies to mitigate their adverse effects. The study strongly advocates for future research in the field of self-supervised representation learning to prioritize the key aspects of safety and robustness in order to ensure practical applicability. The source code and results are available on GitHub.
Performance of data-driven inner speech decoding with same-task EEG-fMRI data fusion and bimodal models
Jun 19, 2023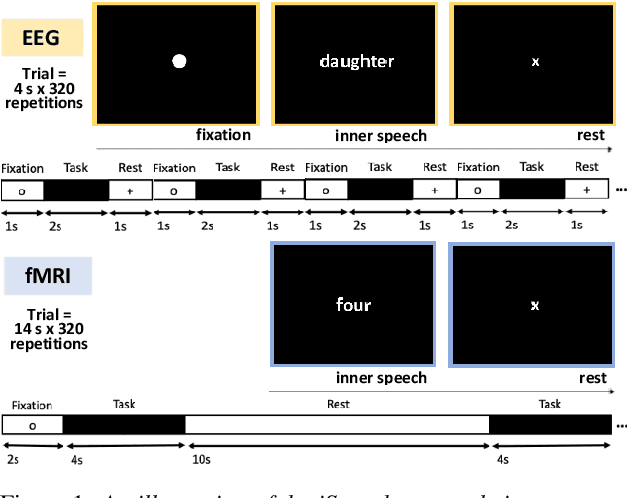
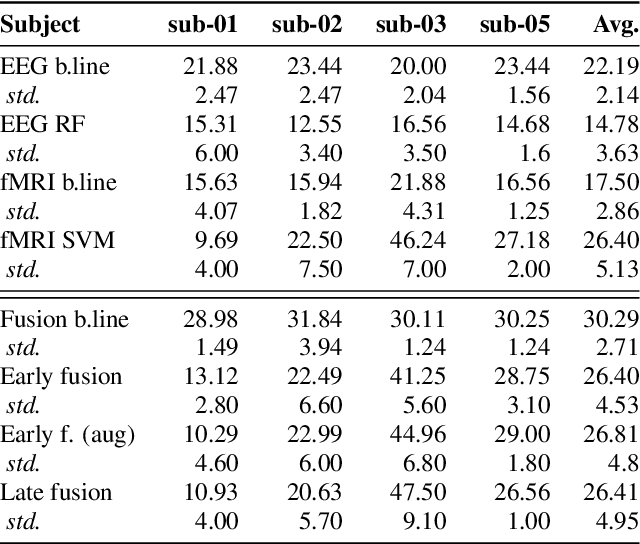
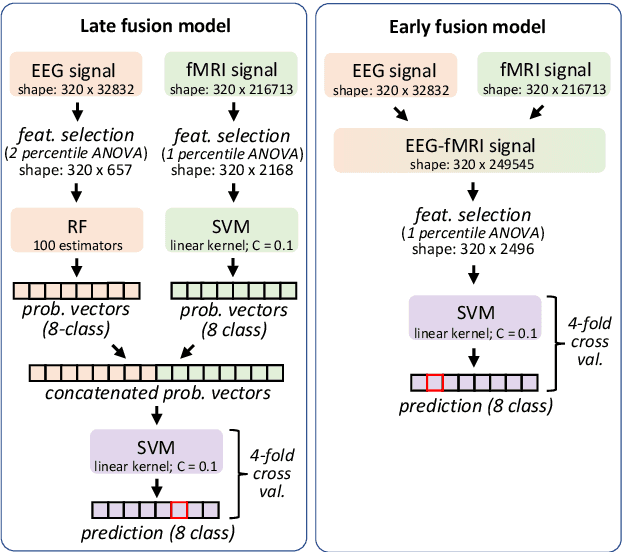
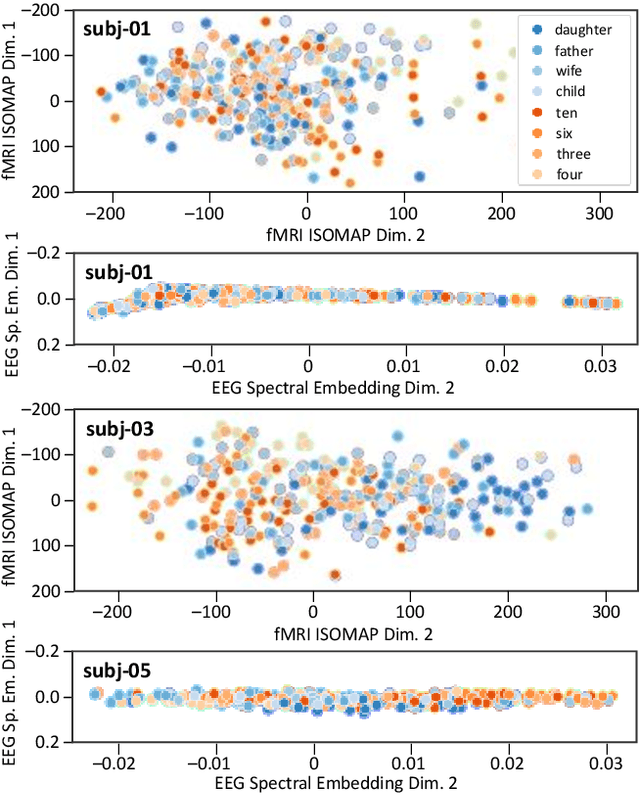
Decoding inner speech from the brain signal via hybridisation of fMRI and EEG data is explored to investigate the performance benefits over unimodal models. Two different bimodal fusion approaches are examined: concatenation of probability vectors output from unimodal fMRI and EEG machine learning models, and data fusion with feature engineering. Same task inner speech data are recorded from four participants, and different processing strategies are compared and contrasted to previously-employed hybridisation methods. Data across participants are discovered to encode different underlying structures, which results in varying decoding performances between subject-dependent fusion models. Decoding performance is demonstrated as improved when pursuing bimodal fMRI-EEG fusion strategies, if the data show underlying structure.
Robust and Fast Vehicle Detection using Augmented Confidence Map
Apr 27, 2023



Vehicle detection in real-time scenarios is challenging because of the time constraints and the presence of multiple types of vehicles with different speeds, shapes, structures, etc. This paper presents a new method relied on generating a confidence map-for robust and faster vehicle detection. To reduce the adverse effect of different speeds, shapes, structures, and the presence of several vehicles in a single image, we introduce the concept of augmentation which highlights the region of interest containing the vehicles. The augmented map is generated by exploring the combination of multiresolution analysis and maximally stable extremal regions (MR-MSER). The output of MR-MSER is supplied to fast CNN to generate a confidence map, which results in candidate regions. Furthermore, unlike existing models that implement complicated models for vehicle detection, we explore the combination of a rough set and fuzzy-based models for robust vehicle detection. To show the effectiveness of the proposed method, we conduct experiments on our dataset captured by drones and on several vehicle detection benchmark datasets, namely, KITTI and UA-DETRAC. The results on our dataset and the benchmark datasets show that the proposed method outperforms the existing methods in terms of time efficiency and achieves a good detection rate.
Functional Knowledge Transfer with Self-supervised Representation Learning
Mar 12, 2023



This work investigates the unexplored usability of self-supervised representation learning in the direction of functional knowledge transfer. In this work, functional knowledge transfer is achieved by joint optimization of self-supervised learning pseudo task and supervised learning task, improving supervised learning task performance. Recent progress in self-supervised learning uses a large volume of data, which becomes a constraint for its applications on small-scale datasets. This work shares a simple yet effective joint training framework that reinforces human-supervised task learning by learning self-supervised representations just-in-time and vice versa. Experiments on three public datasets from different visual domains, Intel Image, CIFAR, and APTOS, reveal a consistent track of performance improvements on classification tasks during joint optimization. Qualitative analysis also supports the robustness of learnt representations. Source code and trained models are available on GitHub.
A Systematic Performance Analysis of Deep Perceptual Loss Networks Breaks Transfer Learning Conventions
Feb 08, 2023Deep perceptual loss is a type of loss function in computer vision that aims to mimic human perception by using the deep features extracted from neural networks. In recent years the method has been applied to great effect on a host of interesting computer vision tasks, especially for tasks with image or image-like outputs. Many applications of the method use pretrained networks, often convolutional networks, for loss calculation. Despite the increased interest and broader use, more effort is needed toward exploring which networks to use for calculating deep perceptual loss and from which layers to extract the features. This work aims to rectify this by systematically evaluating a host of commonly used and readily available, pretrained networks for a number of different feature extraction points on four existing use cases of deep perceptual loss. The four use cases are implementations of previous works where the selected networks and extraction points are evaluated instead of the networks and extraction points used in the original work. The experimental tasks are dimensionality reduction, image segmentation, super-resolution, and perceptual similarity. The performance on these four tasks, attributes of the networks, and extraction points are then used as a basis for an in-depth analysis. This analysis uncovers essential information regarding which architectures provide superior performance for deep perceptual loss and how to choose an appropriate extraction point for a particular task and dataset. Furthermore, the work discusses the implications of the results for deep perceptual loss and the broader field of transfer learning. The results break commonly held assumptions in transfer learning, which imply that deep perceptual loss deviates from most transfer learning settings or that these assumptions need a thorough re-evaluation.