 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidTAG: Temporally Aligned Video to GPS Geolocalization with Denoising Sequence Prediction at a Global Scale
Apr 14, 2026The task of video geolocalization aims to determine the precise GPS coordinates of a video's origin and map its trajectory; with applications in forensics, social media, and exploration. Existing classification-based approaches operate at a coarse city-level granularity and fail to capture fine-grained details, while image retrieval methods are impractical on a global scale due to the need for extensive image galleries which are infeasible to compile. Comparatively, constructing a gallery of GPS coordinates is straightforward and inexpensive. We propose VidTAG, a dual-encoder framework that performs frame-to-GPS retrieval using both self-supervised and language-aligned features. To address temporal inconsistencies in video predictions, we introduce the TempGeo module, which aligns frame embeddings, and the GeoRefiner module, an encoder-decoder architecture that refines GPS features using the aligned frame embeddings. Evaluations on Mapillary (MSLS) and GAMa datasets demonstrate our model's ability to generate temporally consistent trajectories and outperform baselines, achieving a 20% improvement at the 1 km threshold over GeoCLIP. We also beat current State-of-the-Art by 25% on global coarse grained video geolocalization (CityGuessr68k). Our approach enables fine-grained video geolocalization and lays a strong foundation for future research. More details on the project webpage: https://parthpk.github.io/vidtag_webpage/
Can Self-Supervised Representation Learning Methods Withstand Distribution Shifts and Corruptions?
Aug 11, 2023Self-supervised learning in computer vision aims to leverage the inherent structure and relationships within data to learn meaningful representations without explicit human annotation, enabling a holistic understanding of visual scenes. Robustness in vision machine learning ensures reliable and consistent performance, enhancing generalization, adaptability, and resistance to noise, variations, and adversarial attacks. Self-supervised paradigms, namely contrastive learning, knowledge distillation, mutual information maximization, and clustering, have been considered to have shown advances in invariant learning representations. This work investigates the robustness of learned representations of self-supervised learning approaches focusing on distribution shifts and image corruptions in computer vision. Detailed experiments have been conducted to study the robustness of self-supervised learning methods on distribution shifts and image corruptions. The empirical analysis demonstrates a clear relationship between the performance of learned representations within self-supervised paradigms and the severity of distribution shifts and corruptions. Notably, higher levels of shifts and corruptions are found to significantly diminish the robustness of the learned representations. These findings highlight the critical impact of distribution shifts and image corruptions on the performance and resilience of self-supervised learning methods, emphasizing the need for effective strategies to mitigate their adverse effects. The study strongly advocates for future research in the field of self-supervised representation learning to prioritize the key aspects of safety and robustness in order to ensure practical applicability. The source code and results are available on GitHub.
Learning Self-Supervised Representations for Label Efficient Cross-Domain Knowledge Transfer on Diabetic Retinopathy Fundus Images
Apr 20, 2023



This work presents a novel label-efficient selfsupervised representation learning-based approach for classifying diabetic retinopathy (DR) images in cross-domain settings. Most of the existing DR image classification methods are based on supervised learning which requires a lot of time-consuming and expensive medical domain experts-annotated data for training. The proposed approach uses the prior learning from the source DR image dataset to classify images drawn from the target datasets. The image representations learned from the unlabeled source domain dataset through contrastive learning are used to classify DR images from the target domain dataset. Moreover, the proposed approach requires a few labeled images to perform successfully on DR image classification tasks in cross-domain settings. The proposed work experiments with four publicly available datasets: EyePACS, APTOS 2019, MESSIDOR-I, and Fundus Images for self-supervised representation learning-based DR image classification in cross-domain settings. The proposed method achieves state-of-the-art results on binary and multiclassification of DR images, even in cross-domain settings. The proposed method outperforms the existing DR image binary and multi-class classification methods proposed in the literature. The proposed method is also validated qualitatively using class activation maps, revealing that the method can learn explainable image representations. The source code and trained models are published on GitHub.
Domain Adaptable Self-supervised Representation Learning on Remote Sensing Satellite Imagery
Apr 19, 2023



This work presents a novel domain adaption paradigm for studying contrastive self-supervised representation learning and knowledge transfer using remote sensing satellite data. Major state-of-the-art remote sensing visual domain efforts primarily focus on fully supervised learning approaches that rely entirely on human annotations. On the other hand, human annotations in remote sensing satellite imagery are always subject to limited quantity due to high costs and domain expertise, making transfer learning a viable alternative. The proposed approach investigates the knowledge transfer of selfsupervised representations across the distinct source and target data distributions in depth in the remote sensing data domain. In this arrangement, self-supervised contrastive learning-based pretraining is performed on the source dataset, and downstream tasks are performed on the target datasets in a round-robin fashion. Experiments are conducted on three publicly available datasets, UC Merced Landuse (UCMD), SIRI-WHU, and MLRSNet, for different downstream classification tasks versus label efficiency. In self-supervised knowledge transfer, the proposed approach achieves state-of-the-art performance with label efficiency labels and outperforms a fully supervised setting. A more in-depth qualitative examination reveals consistent evidence for explainable representation learning. The source code and trained models are published on GitHub.
Functional Knowledge Transfer with Self-supervised Representation Learning
Mar 12, 2023



This work investigates the unexplored usability of self-supervised representation learning in the direction of functional knowledge transfer. In this work, functional knowledge transfer is achieved by joint optimization of self-supervised learning pseudo task and supervised learning task, improving supervised learning task performance. Recent progress in self-supervised learning uses a large volume of data, which becomes a constraint for its applications on small-scale datasets. This work shares a simple yet effective joint training framework that reinforces human-supervised task learning by learning self-supervised representations just-in-time and vice versa. Experiments on three public datasets from different visual domains, Intel Image, CIFAR, and APTOS, reveal a consistent track of performance improvements on classification tasks during joint optimization. Qualitative analysis also supports the robustness of learnt representations. Source code and trained models are available on GitHub.
A Systematic Performance Analysis of Deep Perceptual Loss Networks Breaks Transfer Learning Conventions
Feb 08, 2023Deep perceptual loss is a type of loss function in computer vision that aims to mimic human perception by using the deep features extracted from neural networks. In recent years the method has been applied to great effect on a host of interesting computer vision tasks, especially for tasks with image or image-like outputs. Many applications of the method use pretrained networks, often convolutional networks, for loss calculation. Despite the increased interest and broader use, more effort is needed toward exploring which networks to use for calculating deep perceptual loss and from which layers to extract the features. This work aims to rectify this by systematically evaluating a host of commonly used and readily available, pretrained networks for a number of different feature extraction points on four existing use cases of deep perceptual loss. The four use cases are implementations of previous works where the selected networks and extraction points are evaluated instead of the networks and extraction points used in the original work. The experimental tasks are dimensionality reduction, image segmentation, super-resolution, and perceptual similarity. The performance on these four tasks, attributes of the networks, and extraction points are then used as a basis for an in-depth analysis. This analysis uncovers essential information regarding which architectures provide superior performance for deep perceptual loss and how to choose an appropriate extraction point for a particular task and dataset. Furthermore, the work discusses the implications of the results for deep perceptual loss and the broader field of transfer learning. The results break commonly held assumptions in transfer learning, which imply that deep perceptual loss deviates from most transfer learning settings or that these assumptions need a thorough re-evaluation.
Depth Contrast: Self-Supervised Pretraining on 3DPM Images for Mining Material Classification
Oct 18, 2022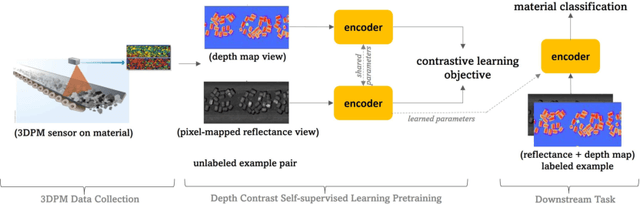
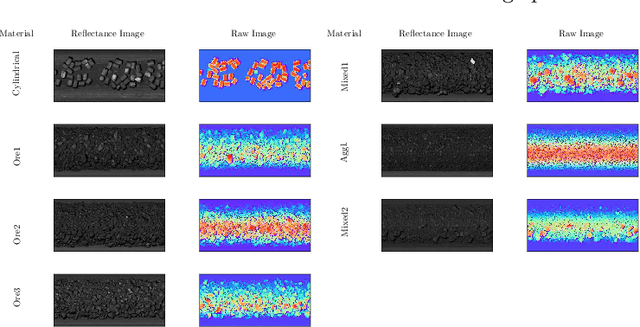
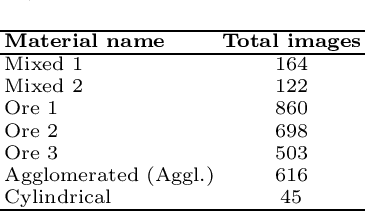
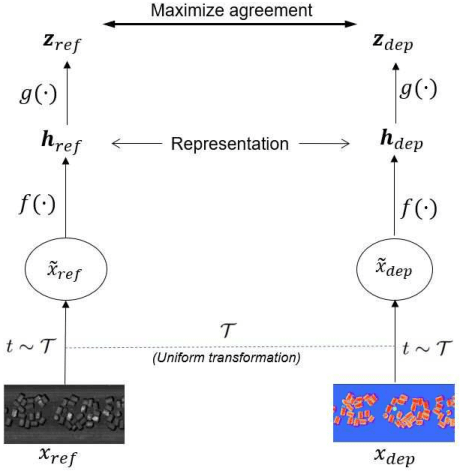
This work presents a novel self-supervised representation learning method to learn efficient representations without labels on images from a 3DPM sensor (3-Dimensional Particle Measurement; estimates the particle size distribution of material) utilizing RGB images and depth maps of mining material on the conveyor belt. Human annotations for material categories on sensor-generated data are scarce and cost-intensive. Currently, representation learning without human annotations remains unexplored for mining materials and does not leverage on utilization of sensor-generated data. The proposed method, Depth Contrast, enables self-supervised learning of representations without labels on the 3DPM dataset by exploiting depth maps and inductive transfer. The proposed method outperforms material classification over ImageNet transfer learning performance in fully supervised learning settings and achieves an F1 score of 0.73. Further, The proposed method yields an F1 score of 0.65 with an 11% improvement over ImageNet transfer learning performance in a semi-supervised setting when only 20% of labels are used in fine-tuning. Finally, the Proposed method showcases improved performance generalization on linear evaluation. The implementation of proposed method is available on GitHub.
Multi-Task Meta Learning: learn how to adapt to unseen tasks
Oct 13, 2022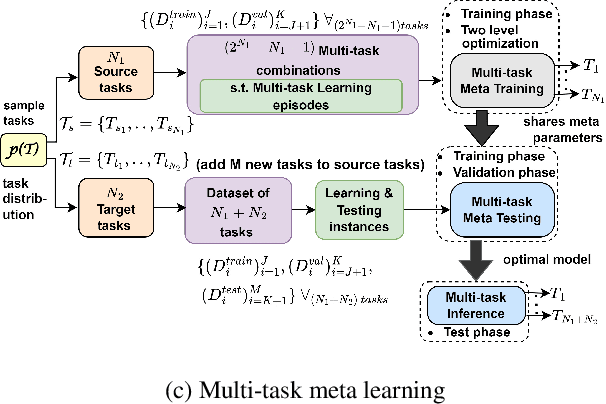
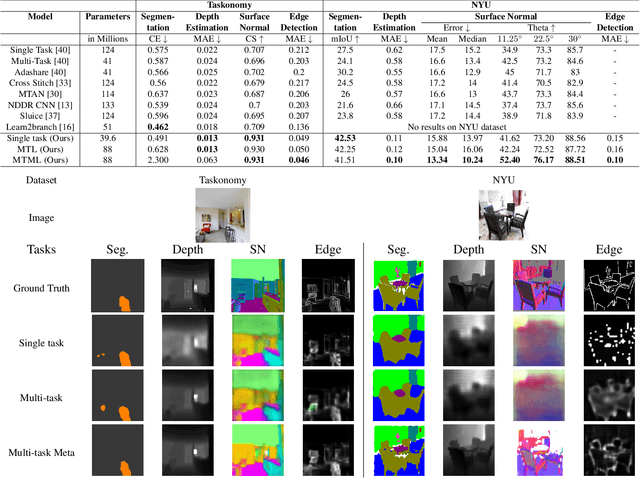
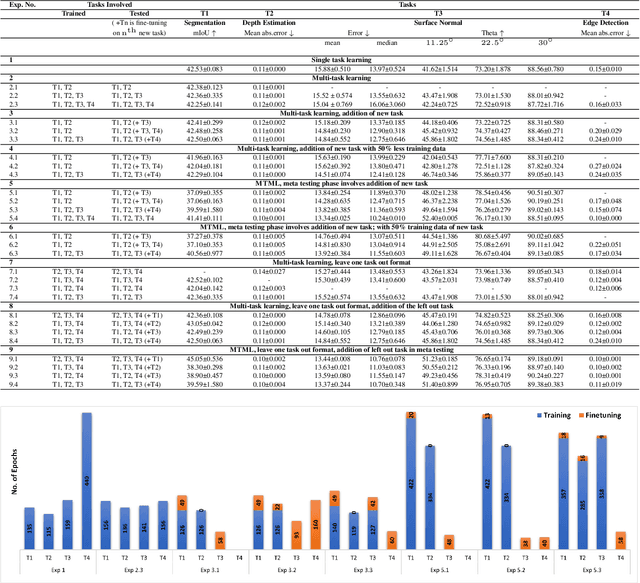
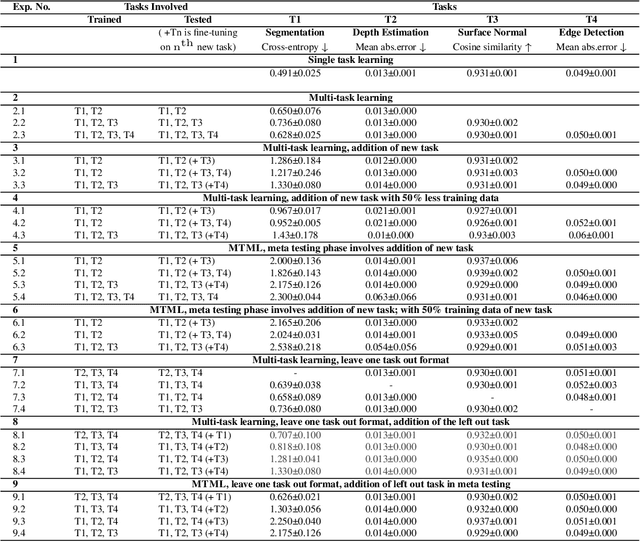
This work aims to integrate two learning paradigms Multi-Task Learning (MTL) and meta learning, to bring together the best of both worlds, i.e., simultaneous learning of multiple tasks, an element of MTL and promptly adapting to new tasks with fewer data, a quality of meta learning. We propose Multi-task Meta Learning (MTML), an approach to enhance MTL compared to single task learning by employing meta learning. The fundamental idea of this work is to train a multi-task model, such that when an unseen task is introduced, it can learn in fewer steps whilst offering a performance at least as good as conventional single task learning on the new task or inclusion within the MTL. By conducting various experiments, we demonstrate this paradigm on two datasets and four tasks: NYU-v2 and the taskonomy dataset for which we perform semantic segmentation, depth estimation, surface normal estimation, and edge detection. MTML achieves state-of-the-art results for most of the tasks, and MTL also performs reasonably well for all tasks compared to single task learning.
Magnification Prior: A Self-Supervised Method for Learning Representations on Breast Cancer Histopathological Images
Mar 15, 2022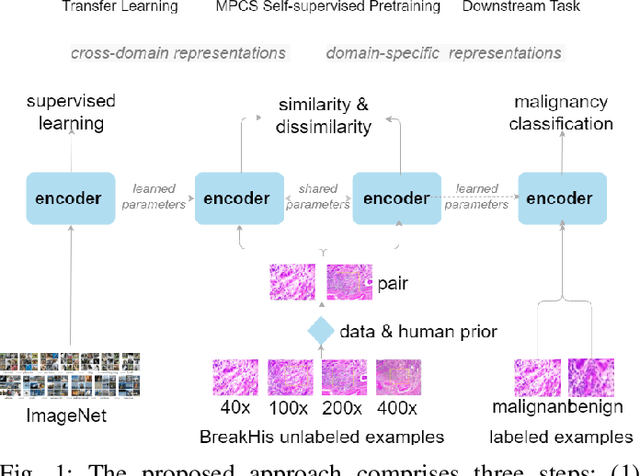
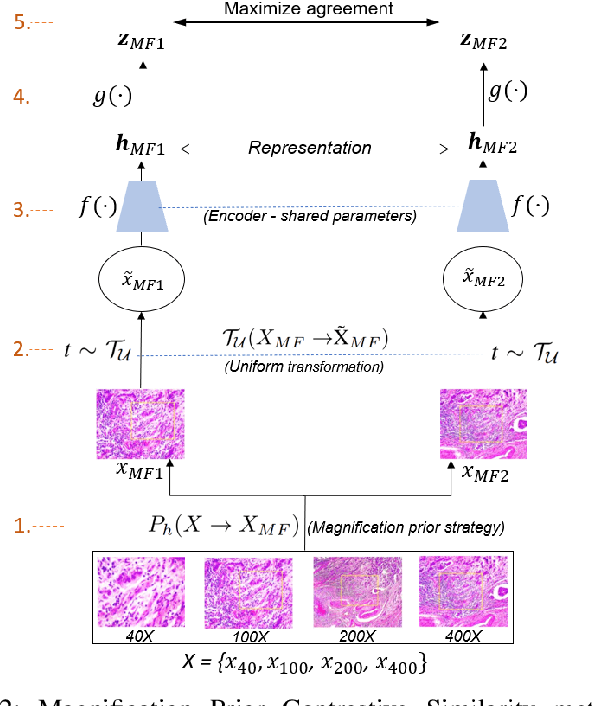
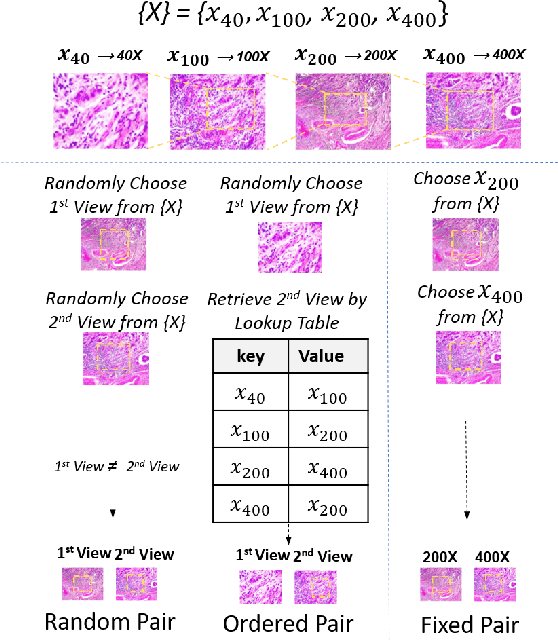
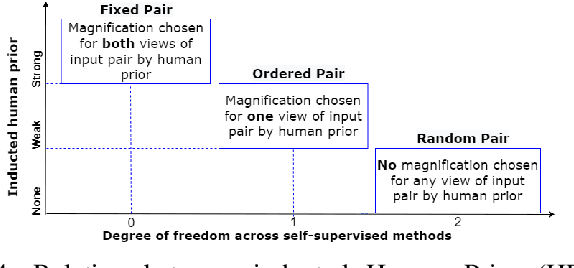
This work presents a novel self-supervised pre-training method to learn efficient representations without labels on histopathology medical images utilizing magnification factors. Other state-of-theart works mainly focus on fully supervised learning approaches that rely heavily on human annotations. However, the scarcity of labeled and unlabeled data is a long-standing challenge in histopathology. Currently, representation learning without labels remains unexplored for the histopathology domain. The proposed method, Magnification Prior Contrastive Similarity (MPCS), enables self-supervised learning of representations without labels on small-scale breast cancer dataset BreakHis by exploiting magnification factor, inductive transfer, and reducing human prior. The proposed method matches fully supervised learning state-of-the-art performance in malignancy classification when only 20% of labels are used in fine-tuning and outperform previous works in fully supervised learning settings. It formulates a hypothesis and provides empirical evidence to support that reducing human-prior leads to efficient representation learning in self-supervision. The implementation of this work is available online on GitHub - https://github.com/prakashchhipa/Magnification-Prior-Self-Supervised-Method