 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Font Impression Word Tags Based on Co-occurrence
Aug 26, 2025Different font styles (i.e., font shapes) convey distinct impressions, indicating a close relationship between font shapes and word tags describing those impressions. This paper proposes a novel embedding method for impression tags that leverages these shape-impression relationships. For instance, our method assigns similar vectors to impression tags that frequently co-occur in order to represent impressions of fonts, whereas standard word embedding methods (e.g., BERT and CLIP) yield very different vectors. This property is particularly useful for impression-based font generation and font retrieval. Technically, we construct a graph whose nodes represent impression tags and whose edges encode co-occurrence relationships. Then, we apply spectral embedding to obtain the impression vectors for each tag. We compare our method with BERT and CLIP in qualitative and quantitative evaluations, demonstrating that our approach performs better in impression-guided font generation.
Enhancing Reliability of Medical Image Diagnosis through Top-rank Learning with Rejection Module
Aug 11, 2025In medical image processing, accurate diagnosis is of paramount importance. Leveraging machine learning techniques, particularly top-rank learning, shows significant promise by focusing on the most crucial instances. However, challenges arise from noisy labels and class-ambiguous instances, which can severely hinder the top-rank objective, as they may be erroneously placed among the top-ranked instances. To address these, we propose a novel approach that enhances toprank learning by integrating a rejection module. Cooptimized with the top-rank loss, this module identifies and mitigates the impact of outliers that hinder training effectiveness. The rejection module functions as an additional branch, assessing instances based on a rejection function that measures their deviation from the norm. Through experimental validation on a medical dataset, our methodology demonstrates its efficacy in detecting and mitigating outliers, improving the reliability and accuracy of medical image diagnoses.
Inverse Scene Text Removal
Jun 26, 2025Scene text removal (STR) aims to erase textual elements from images. It was originally intended for removing privacy-sensitiveor undesired texts from natural scene images, but is now also appliedto typographic images. STR typically detects text regions and theninpaints them. Although STR has advanced through neural networksand synthetic data, misuse risks have increased. This paper investi-gates Inverse STR (ISTR), which analyzes STR-processed images andfocuses on binary classification (detecting whether an image has un-dergone STR) and localizing removed text regions. We demonstrate inexperiments that these tasks are achievable with high accuracies, en-abling detection of potential misuse and improving STR. We also at-tempt to recover the removed text content by training a text recognizerto understand its difficulty.
Instance-wise Supervision-level Optimization in Active Learning
Mar 09, 2025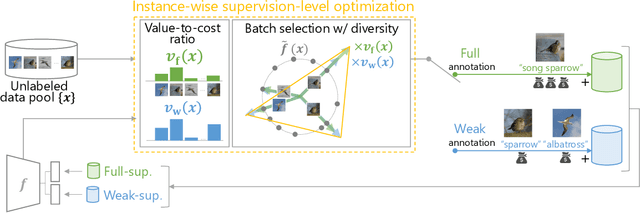

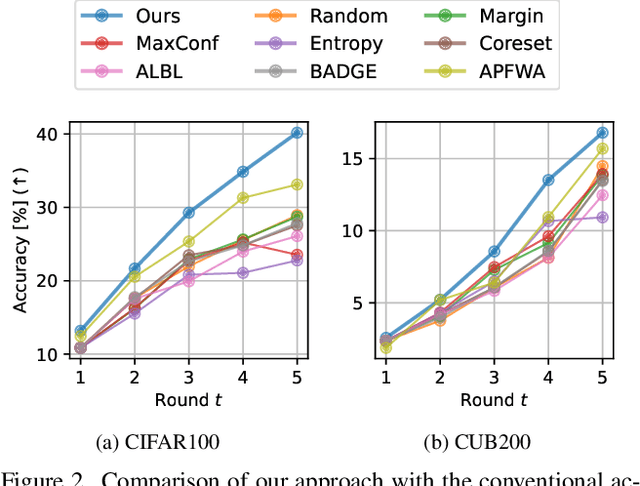
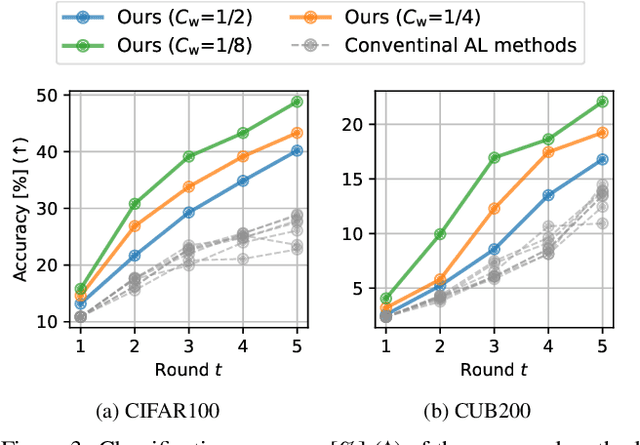
Active learning (AL) is a label-efficient machine learning paradigm that focuses on selectively annotating high-value instances to maximize learning efficiency. Its effectiveness can be further enhanced by incorporating weak supervision, which uses rough yet cost-effective annotations instead of exact (i.e., full) but expensive annotations. We introduce a novel AL framework, Instance-wise Supervision-Level Optimization (ISO), which not only selects the instances to annotate but also determines their optimal annotation level within a fixed annotation budget. Its optimization criterion leverages the value-to-cost ratio (VCR) of each instance while ensuring diversity among the selected instances. In classification experiments, ISO consistently outperforms traditional AL methods and surpasses a state-of-the-art AL approach that combines full and weak supervision, achieving higher accuracy at a lower overall cost. This code is available at https://github.com/matsuo-shinnosuke/ISOAL.
Self-Relaxed Joint Training: Sample Selection for Severity Estimation with Ordinal Noisy Labels
Oct 29, 2024



Severity level estimation is a crucial task in medical image diagnosis. However, accurately assigning severity class labels to individual images is very costly and challenging. Consequently, the attached labels tend to be noisy. In this paper, we propose a new framework for training with ``ordinal'' noisy labels. Since severity levels have an ordinal relationship, we can leverage this to train a classifier while mitigating the negative effects of noisy labels. Our framework uses two techniques: clean sample selection and dual-network architecture. A technical highlight of our approach is the use of soft labels derived from noisy hard labels. By appropriately using the soft and hard labels in the two techniques, we achieve more accurate sample selection and robust network training. The proposed method outperforms various state-of-the-art methods in experiments using two endoscopic ulcerative colitis (UC) datasets and a retinal Diabetic Retinopathy (DR) dataset. Our codes are available at https://github.com/shumpei-takezaki/Self-Relaxed-Joint-Training.
Can GPTs Evaluate Graphic Design Based on Design Principles?
Oct 11, 2024Recent advancements in foundation models show promising capability in graphic design generation. Several studies have started employing Large Multimodal Models (LMMs) to evaluate graphic designs, assuming that LMMs can properly assess their quality, but it is unclear if the evaluation is reliable. One way to evaluate the quality of graphic design is to assess whether the design adheres to fundamental graphic design principles, which are the designer's common practice. In this paper, we compare the behavior of GPT-based evaluation and heuristic evaluation based on design principles using human annotations collected from 60 subjects. Our experiments reveal that, while GPTs cannot distinguish small details, they have a reasonably good correlation with human annotation and exhibit a similar tendency to heuristic metrics based on design principles, suggesting that they are indeed capable of assessing the quality of graphic design. Our dataset is available at https://cyberagentailab.github.io/Graphic-design-evaluation .
Deep Bayesian Active Learning-to-Rank with Relative Annotation for Estimation of Ulcerative Colitis Severity
Sep 10, 2024



Automatic image-based severity estimation is an important task in computer-aided diagnosis. Severity estimation by deep learning requires a large amount of training data to achieve a high performance. In general, severity estimation uses training data annotated with discrete (i.e., quantized) severity labels. Annotating discrete labels is often difficult in images with ambiguous severity, and the annotation cost is high. In contrast, relative annotation, in which the severity between a pair of images is compared, can avoid quantizing severity and thus makes it easier. We can estimate relative disease severity using a learning-to-rank framework with relative annotations, but relative annotation has the problem of the enormous number of pairs that can be annotated. Therefore, the selection of appropriate pairs is essential for relative annotation. In this paper, we propose a deep Bayesian active learning-to-rank that automatically selects appropriate pairs for relative annotation. Our method preferentially annotates unlabeled pairs with high learning efficiency from the model uncertainty of the samples. We prove the theoretical basis for adapting Bayesian neural networks to pairwise learning-to-rank and demonstrate the efficiency of our method through experiments on endoscopic images of ulcerative colitis on both private and public datasets. We also show that our method achieves a high performance under conditions of significant class imbalance because it automatically selects samples from the minority classes.
* 14 pages, 8 figures, accepted in Medical Image Analysis 2024
Learning from Partial Label Proportions for Whole Slide Image Segmentation
May 15, 2024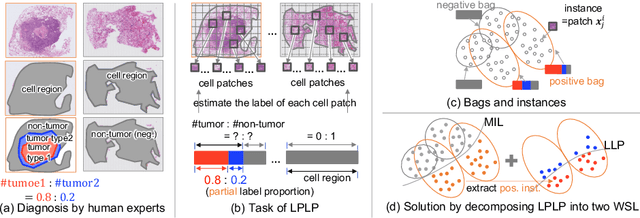

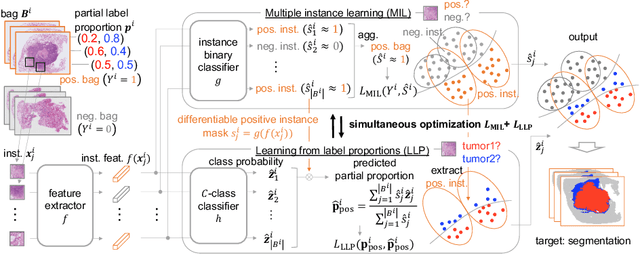
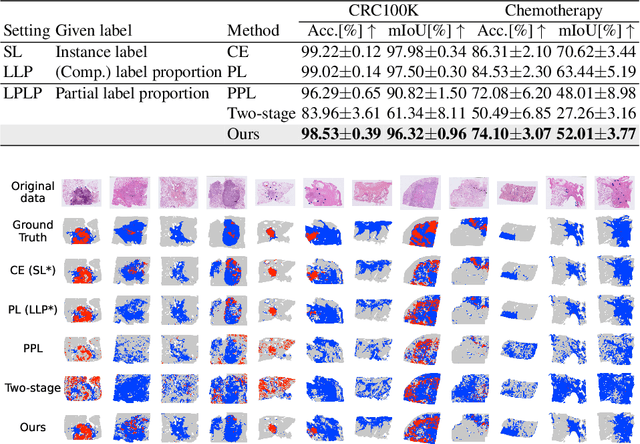
In this paper, we address the segmentation of tumor subtypes in whole slide images (WSI) by utilizing incomplete label proportions. Specifically, we utilize `partial' label proportions, which give the proportions among tumor subtypes but do not give the proportion between tumor and non-tumor. Partial label proportions are recorded as the standard diagnostic information by pathologists, and we, therefore, want to use them for realizing the segmentation model that can classify each WSI patch into one of the tumor subtypes or non-tumor. We call this problem ``learning from partial label proportions (LPLP)'' and formulate the problem as a weakly supervised learning problem. Then, we propose an efficient algorithm for this challenging problem by decomposing it into two weakly supervised learning subproblems: multiple instance learning (MIL) and learning from label proportions (LLP). These subproblems are optimized efficiently in the end-to-end manner. The effectiveness of our algorithm is demonstrated through experiments conducted on two WSI datasets.
Test-Time Augmentation for Traveling Salesperson Problem
May 08, 2024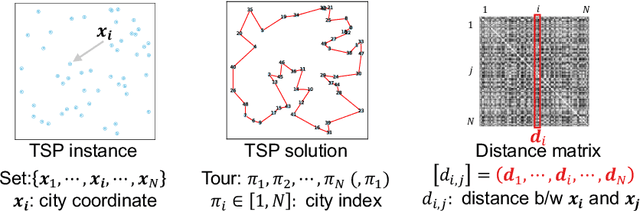
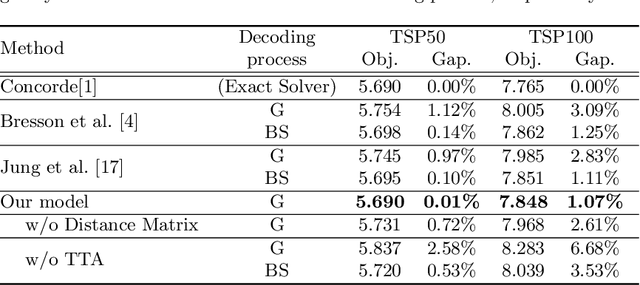
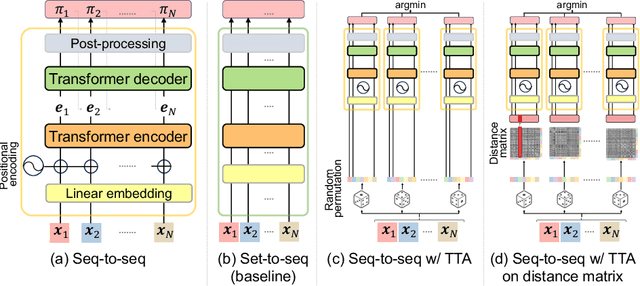
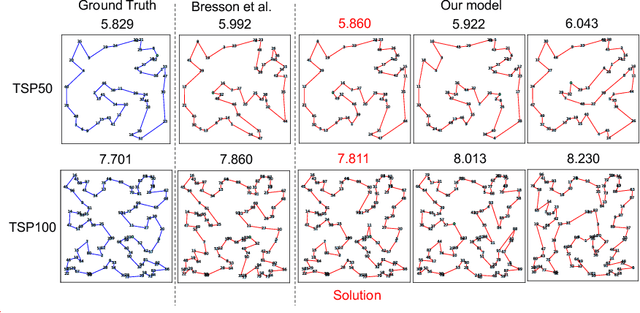
We propose Test-Time Augmentation (TTA) as an effective technique for addressing combinatorial optimization problems, including the Traveling Salesperson Problem. In general, deep learning models possessing the property of invariance, where the output is uniquely determined regardless of the node indices, have been proposed to learn graph structures efficiently. In contrast, we interpret the permutation of node indices, which exchanges the elements of the distance matrix, as a TTA scheme. The results demonstrate that our method is capable of obtaining shorter solutions than the latest models. Furthermore, we show that the probability of finding a solution closer to an exact solution increases depending on the augmentation size.
Pseudo-label Learning with Calibrated Confidence Using an Energy-based Model
Apr 15, 2024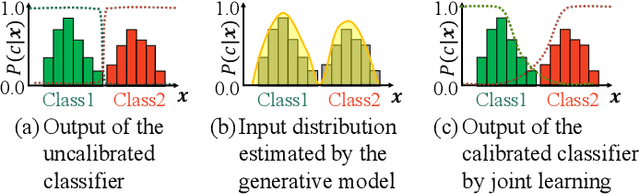
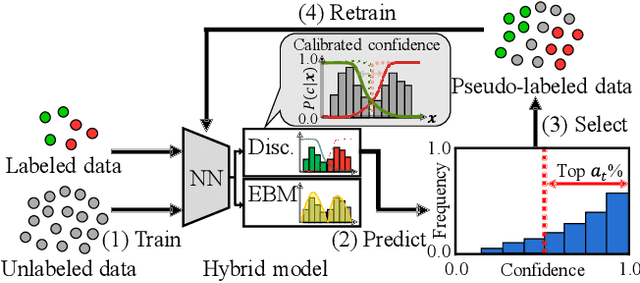
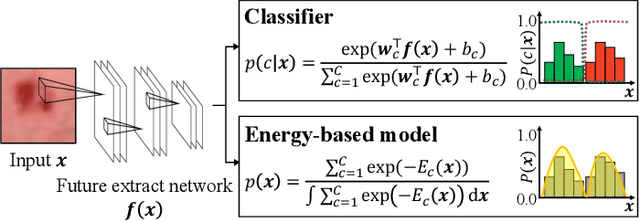
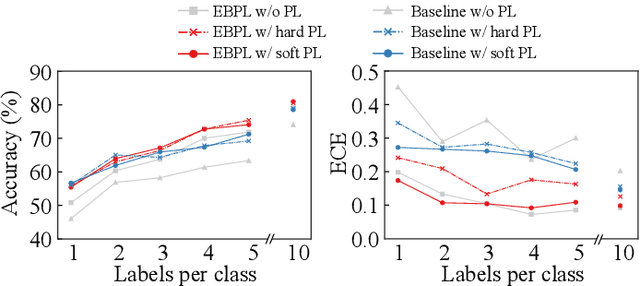
In pseudo-labeling (PL), which is a type of semi-supervised learning, pseudo-labels are assigned based on the confidence scores provided by the classifier; therefore, accurate confidence is important for successful PL. In this study, we propose a PL algorithm based on an energy-based model (EBM), which is referred to as the energy-based PL (EBPL). In EBPL, a neural network-based classifier and an EBM are jointly trained by sharing their feature extraction parts. This approach enables the model to learn both the class decision boundary and input data distribution, enhancing confidence calibration during network training. The experimental results demonstrate that EBPL outperforms the existing PL method in semi-supervised image classification tasks, with superior confidence calibration error and recognition accuracy.