 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeType-R: Automatically Retouching Typos for Text-to-Image Generation
Nov 27, 2024While recent text-to-image models can generate photorealistic images from text prompts that reflect detailed instructions, they still face significant challenges in accurately rendering words in the image. In this paper, we propose to retouch erroneous text renderings in the post-processing pipeline. Our approach, called Type-R, identifies typographical errors in the generated image, erases the erroneous text, regenerates text boxes for missing words, and finally corrects typos in the rendered words. Through extensive experiments, we show that Type-R, in combination with the latest text-to-image models such as Stable Diffusion or Flux, achieves the highest text rendering accuracy while maintaining image quality and also outperforms text-focused generation baselines in terms of balancing text accuracy and image quality.
Can GPTs Evaluate Graphic Design Based on Design Principles?
Oct 11, 2024Recent advancements in foundation models show promising capability in graphic design generation. Several studies have started employing Large Multimodal Models (LMMs) to evaluate graphic designs, assuming that LMMs can properly assess their quality, but it is unclear if the evaluation is reliable. One way to evaluate the quality of graphic design is to assess whether the design adheres to fundamental graphic design principles, which are the designer's common practice. In this paper, we compare the behavior of GPT-based evaluation and heuristic evaluation based on design principles using human annotations collected from 60 subjects. Our experiments reveal that, while GPTs cannot distinguish small details, they have a reasonably good correlation with human annotation and exhibit a similar tendency to heuristic metrics based on design principles, suggesting that they are indeed capable of assessing the quality of graphic design. Our dataset is available at https://cyberagentailab.github.io/Graphic-design-evaluation .
Multimodal Markup Document Models for Graphic Design Completion
Sep 27, 2024



This paper presents multimodal markup document models (MarkupDM) that can generate both markup language and images within interleaved multimodal documents. Unlike existing vision-and-language multimodal models, our MarkupDM tackles unique challenges critical to graphic design tasks: generating partial images that contribute to the overall appearance, often involving transparency and varying sizes, and understanding the syntax and semantics of markup languages, which play a fundamental role as a representational format of graphic designs. To address these challenges, we design an image quantizer to tokenize images of diverse sizes with transparency and modify a code language model to process markup languages and incorporate image modalities. We provide in-depth evaluations of our approach on three graphic design completion tasks: generating missing attribute values, images, and texts in graphic design templates. Results corroborate the effectiveness of our MarkupDM for graphic design tasks. We also discuss the strengths and weaknesses in detail, providing insights for future research on multimodal document generation.
Fast Sprite Decomposition from Animated Graphics
Aug 07, 2024



This paper presents an approach to decomposing animated graphics into sprites, a set of basic elements or layers. Our approach builds on the optimization of sprite parameters to fit the raster video. For efficiency, we assume static textures for sprites to reduce the search space while preventing artifacts using a texture prior model. To further speed up the optimization, we introduce the initialization of the sprite parameters utilizing a pre-trained video object segmentation model and user input of single frame annotations. For our study, we construct the Crello Animation dataset from an online design service and define quantitative metrics to measure the quality of the extracted sprites. Experiments show that our method significantly outperforms baselines for similar decomposition tasks in terms of the quality/efficiency tradeoff.
OpenCOLE: Towards Reproducible Automatic Graphic Design Generation
Jun 12, 2024



Automatic generation of graphic designs has recently received considerable attention. However, the state-of-the-art approaches are complex and rely on proprietary datasets, which creates reproducibility barriers. In this paper, we propose an open framework for automatic graphic design called OpenCOLE, where we build a modified version of the pioneering COLE and train our model exclusively on publicly available datasets. Based on GPT4V evaluations, our model shows promising performance comparable to the original COLE. We release the pipeline and training results to encourage open development.
Total Disentanglement of Font Images into Style and Character Class Features
Mar 19, 2024In this paper, we demonstrate a total disentanglement of font images. Total disentanglement is a neural network-based method for decomposing each font image nonlinearly and completely into its style and content (i.e., character class) features. It uses a simple but careful training procedure to extract the common style feature from all `A'-`Z' images in the same font and the common content feature from all `A' (or another class) images in different fonts. These disentangled features guarantee the reconstruction of the original font image. Various experiments have been conducted to understand the performance of total disentanglement. First, it is demonstrated that total disentanglement is achievable with very high accuracy; this is experimental proof of the long-standing open question, ``Does `A'-ness exist?'' Hofstadter (1985). Second, it is demonstrated that the disentangled features produced by total disentanglement apply to a variety of tasks, including font recognition, character recognition, and one-shot font image generation.
Retrieval-Augmented Layout Transformer for Content-Aware Layout Generation
Nov 22, 2023
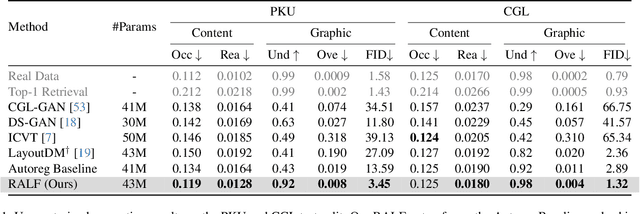

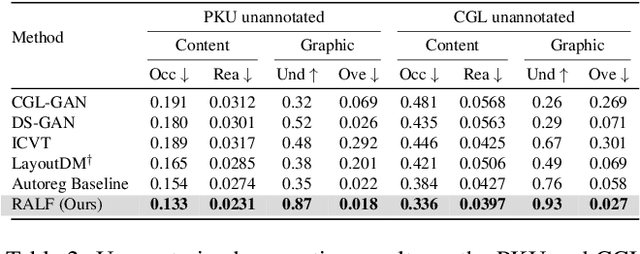
Content-aware graphic layout generation aims to automatically arrange visual elements along with a given content, such as an e-commerce product image. In this paper, we argue that the current layout generation approaches suffer from the limited training data for the high-dimensional layout structure. We show that a simple retrieval augmentation can significantly improve the generation quality. Our model, which is named Retrieval-Augmented Layout Transformer (RALF), retrieves nearest neighbor layout examples based on an input image and feeds these results into an autoregressive generator. Our model can apply retrieval augmentation to various controllable generation tasks and yield high-quality layouts within a unified architecture. Our extensive experiments show that RALF successfully generates content-aware layouts in both constrained and unconstrained settings and significantly outperforms the baselines.
Towards Diverse and Consistent Typography Generation
Sep 05, 2023



In this work, we consider the typography generation task that aims at producing diverse typographic styling for the given graphic document. We formulate typography generation as a fine-grained attribute generation for multiple text elements and build an autoregressive model to generate diverse typography that matches the input design context. We further propose a simple yet effective sampling approach that respects the consistency and distinction principle of typography so that generated examples share consistent typographic styling across text elements. Our empirical study shows that our model successfully generates diverse typographic designs while preserving a consistent typographic structure.
Towards Flexible Multi-modal Document Models
Mar 31, 2023Creative workflows for generating graphical documents involve complex inter-related tasks, such as aligning elements, choosing appropriate fonts, or employing aesthetically harmonious colors. In this work, we attempt at building a holistic model that can jointly solve many different design tasks. Our model, which we denote by FlexDM, treats vector graphic documents as a set of multi-modal elements, and learns to predict masked fields such as element type, position, styling attributes, image, or text, using a unified architecture. Through the use of explicit multi-task learning and in-domain pre-training, our model can better capture the multi-modal relationships among the different document fields. Experimental results corroborate that our single FlexDM is able to successfully solve a multitude of different design tasks, while achieving performance that is competitive with task-specific and costly baselines.
LayoutDM: Discrete Diffusion Model for Controllable Layout Generation
Mar 14, 2023



Controllable layout generation aims at synthesizing plausible arrangement of element bounding boxes with optional constraints, such as type or position of a specific element. In this work, we try to solve a broad range of layout generation tasks in a single model that is based on discrete state-space diffusion models. Our model, named LayoutDM, naturally handles the structured layout data in the discrete representation and learns to progressively infer a noiseless layout from the initial input, where we model the layout corruption process by modality-wise discrete diffusion. For conditional generation, we propose to inject layout constraints in the form of masking or logit adjustment during inference. We show in the experiments that our LayoutDM successfully generates high-quality layouts and outperforms both task-specific and task-agnostic baselines on several layout tasks.