 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoodLogAthl-218: Constructing a Real-World Food Image Dataset Using Dietary Management Applications
Dec 16, 2025Food image classification models are crucial for dietary management applications because they reduce the burden of manual meal logging. However, most publicly available datasets for training such models rely on web-crawled images, which often differ from users' real-world meal photos. In this work, we present FoodLogAthl-218, a food image dataset constructed from real-world meal records collected through the dietary management application FoodLog Athl. The dataset contains 6,925 images across 218 food categories, with a total of 14,349 bounding boxes. Rich metadata, including meal date and time, anonymized user IDs, and meal-level context, accompany each image. Unlike conventional datasets-where a predefined class set guides web-based image collection-our data begins with user-submitted photos, and labels are applied afterward. This yields greater intra-class diversity, a natural frequency distribution of meal types, and casual, unfiltered images intended for personal use rather than public sharing. In addition to (1) a standard classification benchmark, we introduce two FoodLog-specific tasks: (2) an incremental fine-tuning protocol that follows the temporal stream of users' logs, and (3) a context-aware classification task where each image contains multiple dishes, and the model must classify each dish by leveraging the overall meal context. We evaluate these tasks using large multimodal models (LMMs). The dataset is publicly available at https://huggingface.co/datasets/FoodLog/FoodLogAthl-218.
JMMMU-Pro: Image-based Japanese Multi-discipline Multimodal Understanding Benchmark via Vibe Benchmark Construction
Dec 16, 2025This paper introduces JMMMU-Pro, an image-based Japanese Multi-discipline Multimodal Understanding Benchmark, and Vibe Benchmark Construction, a scalable construction method. Following the evolution from MMMU to MMMU-Pro, JMMMU-Pro extends JMMMU by composing the question image and question text into a single image, thereby creating a benchmark that requires integrated visual-textual understanding through visual perception. To build JMMMU-Pro, we propose Vibe Benchmark Construction, a methodology in which an image generative model (e.g., Nano Banana Pro) produces candidate visual questions, and humans verify the outputs and, when necessary, regenerate with adjusted prompts to ensure quality. By leveraging Nano Banana Pro's highly realistic image generation capabilities and its ability to embed clean Japanese text, we construct a high-quality benchmark at low cost, covering a wide range of background and layout designs. Experimental results show that all open-source LMMs struggle substantially with JMMMU-Pro, underscoring JMMMU-Pro as an important benchmark for guiding future efforts in the open-source community. We believe that JMMMU-Pro provides a more rigorous evaluation tool for assessing the Japanese capabilities of LMMs and that our Vibe Benchmark Construction also offers an efficient guideline for future development of image-based VQA benchmarks.
Jr. AI Scientist and Its Risk Report: Autonomous Scientific Exploration from a Baseline Paper
Nov 06, 2025Understanding the current capabilities and risks of AI Scientist systems is essential for ensuring trustworthy and sustainable AI-driven scientific progress while preserving the integrity of the academic ecosystem. To this end, we develop Jr. AI Scientist, a state-of-the-art autonomous AI scientist system that mimics the core research workflow of a novice student researcher: Given the baseline paper from the human mentor, it analyzes its limitations, formulates novel hypotheses for improvement, validates them through rigorous experimentation, and writes a paper with the results. Unlike previous approaches that assume full automation or operate on small-scale code, Jr. AI Scientist follows a well-defined research workflow and leverages modern coding agents to handle complex, multi-file implementations, leading to scientifically valuable contributions. For evaluation, we conducted automated assessments using AI Reviewers, author-led evaluations, and submissions to Agents4Science, a venue dedicated to AI-driven scientific contributions. The findings demonstrate that Jr. AI Scientist generates papers receiving higher review scores than existing fully automated systems. Nevertheless, we identify important limitations from both the author evaluation and the Agents4Science reviews, indicating the potential risks of directly applying current AI Scientist systems and key challenges for future research. Finally, we comprehensively report various risks identified during development. We hope these insights will deepen understanding of current progress and risks in AI Scientist development.
A Highly Clean Recipe Dataset with Ingredient States Annotation for State Probing Task
Jul 23, 2025Large Language Models (LLMs) are trained on a vast amount of procedural texts, but they do not directly observe real-world phenomena. In the context of cooking recipes, this poses a challenge, as intermediate states of ingredients are often omitted, making it difficult for models to track ingredient states and understand recipes accurately. In this paper, we apply state probing, a method for evaluating a language model's understanding of the world, to the domain of cooking. We propose a new task and dataset for evaluating how well LLMs can recognize intermediate ingredient states during cooking procedures. We first construct a new Japanese recipe dataset with clear and accurate annotations of ingredient state changes, collected from well-structured and controlled recipe texts. Using this dataset, we design three novel tasks to evaluate whether LLMs can track ingredient state transitions and identify ingredients present at intermediate steps. Our experiments with widely used LLMs, such as Llama3.1-70B and Qwen2.5-72B, show that learning ingredient state knowledge improves their understanding of cooking processes, achieving performance comparable to commercial LLMs.
PULSE: Practical Evaluation Scenarios for Large Multimodal Model Unlearning
Jul 02, 2025In recent years, unlearning techniques, which are methods for inducing a model to "forget" previously learned information, have attracted attention as a way to address privacy and copyright concerns in large language models (LLMs) and large multimodal models (LMMs). While several unlearning benchmarks have been established for LLMs, a practical evaluation framework for unlearning in LMMs has been less explored. Specifically, existing unlearning benchmark for LMMs considers only scenarios in which the model is required to unlearn fine-tuned knowledge through a single unlearning operation. In this study, we introduce PULSE protocol for realistic unlearning scenarios for LMMs by introducing two critical perspectives: (i) Pre-trained knowledge Unlearning for analyzing the effect across different knowledge acquisition phases and (ii) Long-term Sustainability Evaluation to address sequential requests. We then evaluate existing unlearning methods along these dimensions. Our results reveal that, although some techniques can successfully unlearn knowledge acquired through fine-tuning, they struggle to eliminate information learned during pre-training. Moreover, methods that effectively unlearn a batch of target data in a single operation exhibit substantial performance degradation when the same data are split and unlearned sequentially.
MangaVQA and MangaLMM: A Benchmark and Specialized Model for Multimodal Manga Understanding
May 26, 2025Manga, or Japanese comics, is a richly multimodal narrative form that blends images and text in complex ways. Teaching large multimodal models (LMMs) to understand such narratives at a human-like level could help manga creators reflect on and refine their stories. To this end, we introduce two benchmarks for multimodal manga understanding: MangaOCR, which targets in-page text recognition, and MangaVQA, a novel benchmark designed to evaluate contextual understanding through visual question answering. MangaVQA consists of 526 high-quality, manually constructed question-answer pairs, enabling reliable evaluation across diverse narrative and visual scenarios. Building on these benchmarks, we develop MangaLMM, a manga-specialized model finetuned from the open-source LMM Qwen2.5-VL to jointly handle both tasks. Through extensive experiments, including comparisons with proprietary models such as GPT-4o and Gemini 2.5, we assess how well LMMs understand manga. Our benchmark and model provide a comprehensive foundation for evaluating and advancing LMMs in the richly narrative domain of manga.
Harnessing PDF Data for Improving Japanese Large Multimodal Models
Feb 20, 2025

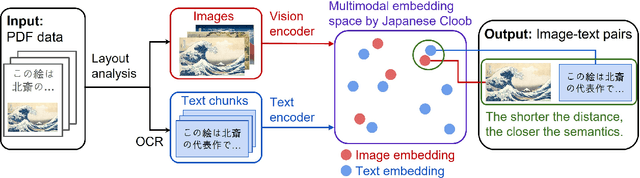

Large Multimodal Models (LMMs) have demonstrated strong performance in English, but their effectiveness in Japanese remains limited due to the lack of high-quality training data. Current Japanese LMMs often rely on translated English datasets, restricting their ability to capture Japan-specific cultural knowledge. To address this, we explore the potential of Japanese PDF data as a training resource, an area that remains largely underutilized. We introduce a fully automated pipeline that leverages pretrained models to extract image-text pairs from PDFs through layout analysis, OCR, and vision-language pairing, removing the need for manual annotation. Additionally, we construct instruction data from extracted image-text pairs to enrich the training data. To evaluate the effectiveness of PDF-derived data, we train Japanese LMMs and assess their performance on the Japanese LMM Benchmark. Our results demonstrate substantial improvements, with performance gains ranging from 3.9% to 13.8% on Heron-Bench. Further analysis highlights the impact of PDF-derived data on various factors, such as model size and language models, reinforcing its value as a multimodal resource for Japanese LMMs. We plan to make the source code and data publicly available upon acceptance.
A Benchmark and Evaluation for Real-World Out-of-Distribution Detection Using Vision-Language Models
Jan 30, 2025



Out-of-distribution (OOD) detection is a task that detects OOD samples during inference to ensure the safety of deployed models. However, conventional benchmarks have reached performance saturation, making it difficult to compare recent OOD detection methods. To address this challenge, we introduce three novel OOD detection benchmarks that enable a deeper understanding of method characteristics and reflect real-world conditions. First, we present ImageNet-X, designed to evaluate performance under challenging semantic shifts. Second, we propose ImageNet-FS-X for full-spectrum OOD detection, assessing robustness to covariate shifts (feature distribution shifts). Finally, we propose Wilds-FS-X, which extends these evaluations to real-world datasets, offering a more comprehensive testbed. Our experiments reveal that recent CLIP-based OOD detection methods struggle to varying degrees across the three proposed benchmarks, and none of them consistently outperforms the others. We hope the community goes beyond specific benchmarks and includes more challenging conditions reflecting real-world scenarios. The code is https://github.com/hoshi23/OOD-X-Banchmarks.
JMMMU: A Japanese Massive Multi-discipline Multimodal Understanding Benchmark for Culture-aware Evaluation
Oct 22, 2024



Accelerating research on Large Multimodal Models (LMMs) in non-English languages is crucial for enhancing user experiences across broader populations. In this paper, we introduce JMMMU (Japanese MMMU), the first large-scale Japanese benchmark designed to evaluate LMMs on expert-level tasks based on the Japanese cultural context. To facilitate comprehensive culture-aware evaluation, JMMMU features two complementary subsets: (i) culture-agnostic (CA) subset, where the culture-independent subjects (e.g., Math) are selected and translated into Japanese, enabling one-to-one comparison with its English counterpart MMMU; and (ii) culture-specific (CS) subset, comprising newly crafted subjects that reflect Japanese cultural context. Using the CA subset, we observe performance drop in many LMMs when evaluated in Japanese, which is purely attributable to language variation. Using the CS subset, we reveal their inadequate Japanese cultural understanding. Further, by combining both subsets, we identify that some LMMs perform well on the CA subset but not on the CS subset, exposing a shallow understanding of the Japanese language that lacks depth in cultural understanding. We hope this work will not only help advance LMM performance in Japanese but also serve as a guideline to create high-standard, culturally diverse benchmarks for multilingual LMM development. The project page is https://mmmu-japanese-benchmark.github.io/JMMMU/.
FoodMLLM-JP: Leveraging Multimodal Large Language Models for Japanese Recipe Generation
Sep 27, 2024



Research on food image understanding using recipe data has been a long-standing focus due to the diversity and complexity of the data. Moreover, food is inextricably linked to people's lives, making it a vital research area for practical applications such as dietary management. Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities, not only in their vast knowledge but also in their ability to handle languages naturally. While English is predominantly used, they can also support multiple languages including Japanese. This suggests that MLLMs are expected to significantly improve performance in food image understanding tasks. We fine-tuned open MLLMs LLaVA-1.5 and Phi-3 Vision on a Japanese recipe dataset and benchmarked their performance against the closed model GPT-4o. We then evaluated the content of generated recipes, including ingredients and cooking procedures, using 5,000 evaluation samples that comprehensively cover Japanese food culture. Our evaluation demonstrates that the open models trained on recipe data outperform GPT-4o, the current state-of-the-art model, in ingredient generation. Our model achieved F1 score of 0.531, surpassing GPT-4o's F1 score of 0.481, indicating a higher level of accuracy. Furthermore, our model exhibited comparable performance to GPT-4o in generating cooking procedure text.