 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models
Dec 08, 2025Recent reinforcement learning (RL) techniques have yielded impressive reasoning improvements in language models, yet it remains unclear whether post-training truly extends a model's reasoning ability beyond what it acquires during pre-training. A central challenge is the lack of control in modern training pipelines: large-scale pre-training corpora are opaque, mid-training is often underexamined, and RL objectives interact with unknown prior knowledge in complex ways. To resolve this ambiguity, we develop a fully controlled experimental framework that isolates the causal contributions of pre-training, mid-training, and RL-based post-training. Our approach employs synthetic reasoning tasks with explicit atomic operations, parseable step-by-step reasoning traces, and systematic manipulation of training distributions. We evaluate models along two axes: extrapolative generalization to more complex compositions and contextual generalization across surface contexts. Using this framework, we reconcile competing views on RL's effectiveness. We show that: 1) RL produces true capability gains (pass@128) only when pre-training leaves sufficient headroom and when RL data target the model's edge of competence, tasks at the boundary that are difficult but not yet out of reach. 2) Contextual generalization requires minimal yet sufficient pre-training exposure, after which RL can reliably transfer. 3) Mid-training significantly enhances performance under fixed compute compared with RL only, demonstrating its central but underexplored role in training pipelines. 4) Process-level rewards reduce reward hacking and improve reasoning fidelity. Together, these results clarify the interplay between pre-training, mid-training, and RL, offering a foundation for understanding and improving reasoning LM training strategies.
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Oct 29, 2025Real-world language agents must handle complex, multi-step workflows across diverse Apps. For instance, an agent may manage emails by coordinating with calendars and file systems, or monitor a production database to detect anomalies and generate reports following an operating manual. However, existing language agent benchmarks often focus on narrow domains or simplified tasks that lack the diversity, realism, and long-horizon complexity required to evaluate agents' real-world performance. To address this gap, we introduce the Tool Decathlon (dubbed as Toolathlon), a benchmark for language agents offering diverse Apps and tools, realistic environment setup, and reliable execution-based evaluation. Toolathlon spans 32 software applications and 604 tools, ranging from everyday platforms such as Google Calendar and Notion to professional ones like WooCommerce, Kubernetes, and BigQuery. Most of the tools are based on a high-quality set of Model Context Protocol (MCP) servers that we may have revised or implemented ourselves. Unlike prior works, which primarily ensure functional realism but offer limited environment state diversity, we provide realistic initial environment states from real software, such as Canvas courses with dozens of students or real financial spreadsheets. This benchmark includes 108 manually sourced or crafted tasks in total, requiring interacting with multiple Apps over around 20 turns on average to complete. Each task is strictly verifiable through dedicated evaluation scripts. Comprehensive evaluation of SOTA models highlights their significant shortcomings: the best-performing model, Claude-4.5-Sonnet, achieves only a 38.6% success rate with 20.2 tool calling turns on average, while the top open-weights model DeepSeek-V3.2-Exp reaches 20.1%. We expect Toolathlon to drive the development of more capable language agents for real-world, long-horizon task execution.
VisCoder: Fine-Tuning LLMs for Executable Python Visualization Code Generation
Jun 04, 2025Large language models (LLMs) often struggle with visualization tasks like plotting diagrams, charts, where success depends on both code correctness and visual semantics. Existing instruction-tuning datasets lack execution-grounded supervision and offer limited support for iterative code correction, resulting in fragile and unreliable plot generation. We present VisCode-200K, a large-scale instruction tuning dataset for Python-based visualization and self-correction. It contains over 200K examples from two sources: (1) validated plotting code from open-source repositories, paired with natural language instructions and rendered plots; and (2) 45K multi-turn correction dialogues from Code-Feedback, enabling models to revise faulty code using runtime feedback. We fine-tune Qwen2.5-Coder-Instruct on VisCode-200K to create VisCoder, and evaluate it on PandasPlotBench. VisCoder significantly outperforms strong open-source baselines and approaches the performance of proprietary models like GPT-4o-mini. We further adopt a self-debug evaluation protocol to assess iterative repair, demonstrating the benefits of feedback-driven learning for executable, visually accurate code generation.
Temporal Sampling for Forgotten Reasoning in LLMs
May 26, 2025Fine-tuning large language models (LLMs) is intended to improve their reasoning capabilities, yet we uncover a counterintuitive effect: models often forget how to solve problems they previously answered correctly during training. We term this phenomenon temporal forgetting and show that it is widespread across model sizes, fine-tuning methods (both Reinforcement Learning and Supervised Fine-Tuning), and multiple reasoning benchmarks. To address this gap, we introduce Temporal Sampling, a simple decoding strategy that draws outputs from multiple checkpoints along the training trajectory. This approach recovers forgotten solutions without retraining or ensembling, and leads to substantial improvements in reasoning performance, gains from 4 to 19 points in Pass@k and consistent gains in Majority@k across several benchmarks. We further extend our method to LoRA-adapted models, demonstrating that storing only adapter weights across checkpoints achieves similar benefits with minimal storage cost. By leveraging the temporal diversity inherent in training, Temporal Sampling offers a practical, compute-efficient way to surface hidden reasoning ability and rethink how we evaluate LLMs.
Unlearning Isn't Deletion: Investigating Reversibility of Machine Unlearning in LLMs
May 22, 2025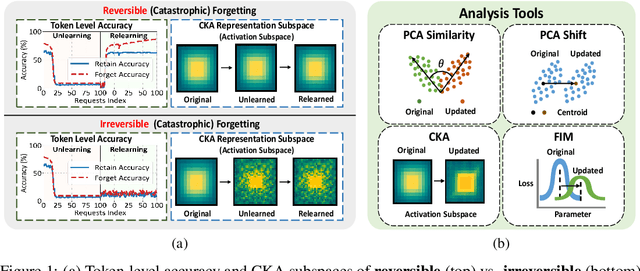
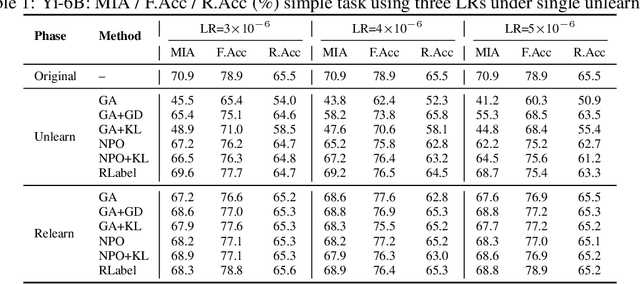
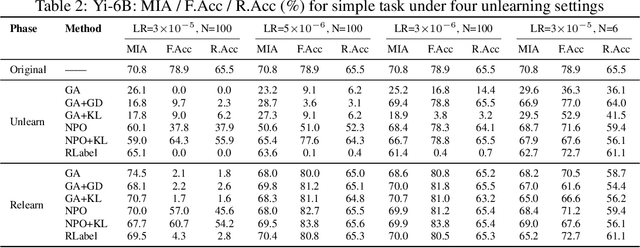
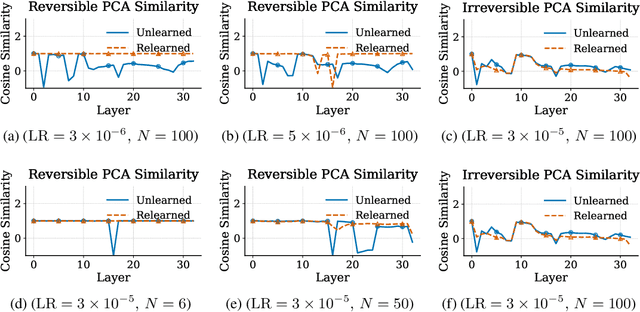
Unlearning in large language models (LLMs) is intended to remove the influence of specific data, yet current evaluations rely heavily on token-level metrics such as accuracy and perplexity. We show that these metrics can be misleading: models often appear to forget, but their original behavior can be rapidly restored with minimal fine-tuning, revealing that unlearning may obscure information rather than erase it. To diagnose this phenomenon, we introduce a representation-level evaluation framework using PCA-based similarity and shift, centered kernel alignment, and Fisher information. Applying this toolkit across six unlearning methods, three domains (text, code, math), and two open-source LLMs, we uncover a critical distinction between reversible and irreversible forgetting. In reversible cases, models suffer token-level collapse yet retain latent features; in irreversible cases, deeper representational damage occurs. We further provide a theoretical account linking shallow weight perturbations near output layers to misleading unlearning signals, and show that reversibility is modulated by task type and hyperparameters. Our findings reveal a fundamental gap in current evaluation practices and establish a new diagnostic foundation for trustworthy unlearning in LLMs. We provide a unified toolkit for analyzing LLM representation changes under unlearning and relearning: https://github.com/XiaoyuXU1/Representational_Analysis_Tools.git.
The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think
May 15, 2025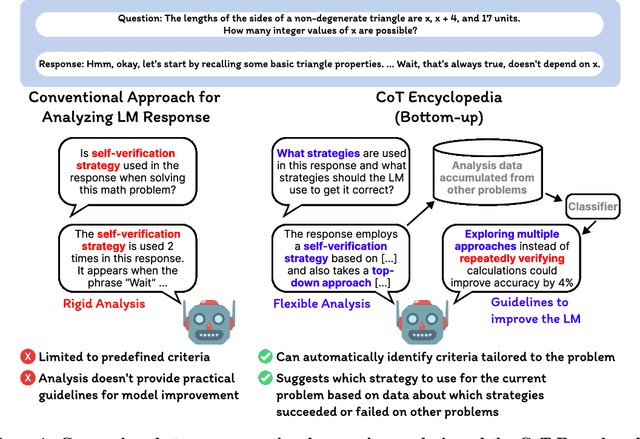
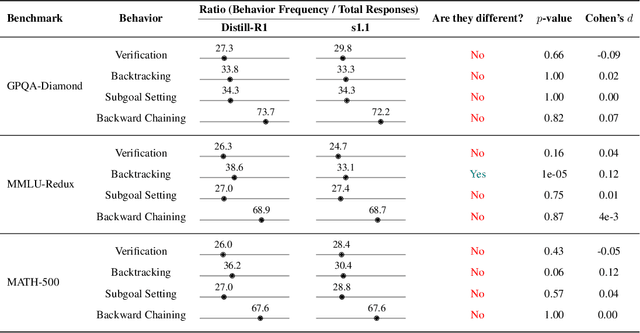
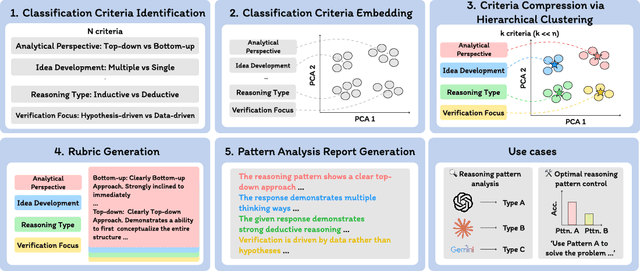
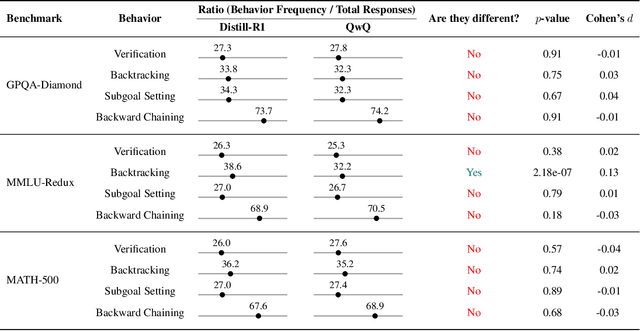
Long chain-of-thought (CoT) is an essential ingredient in effective usage of modern large language models, but our understanding of the reasoning strategies underlying these capabilities remains limited. While some prior works have attempted to categorize CoTs using predefined strategy types, such approaches are constrained by human intuition and fail to capture the full diversity of model behaviors. In this work, we introduce the CoT Encyclopedia, a bottom-up framework for analyzing and steering model reasoning. Our method automatically extracts diverse reasoning criteria from model-generated CoTs, embeds them into a semantic space, clusters them into representative categories, and derives contrastive rubrics to interpret reasoning behavior. Human evaluations show that this framework produces more interpretable and comprehensive analyses than existing methods. Moreover, we demonstrate that this understanding enables performance gains: we can predict which strategy a model is likely to use and guide it toward more effective alternatives. Finally, we provide practical insights, such as that training data format (e.g., free-form vs. multiple-choice) has a far greater impact on reasoning behavior than data domain, underscoring the importance of format-aware model design.
VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge
Apr 15, 2025Current multimodal benchmarks often conflate reasoning with domain-specific knowledge, making it difficult to isolate and evaluate general reasoning abilities in non-expert settings. To address this, we introduce VisualPuzzles, a benchmark that targets visual reasoning while deliberately minimizing reliance on specialized knowledge. VisualPuzzles consists of diverse questions spanning five categories: algorithmic, analogical, deductive, inductive, and spatial reasoning. One major source of our questions is manually translated logical reasoning questions from the Chinese Civil Service Examination. Experiments show that VisualPuzzles requires significantly less intensive domain-specific knowledge and more complex reasoning compared to benchmarks like MMMU, enabling us to better evaluate genuine multimodal reasoning. Evaluations show that state-of-the-art multimodal large language models consistently lag behind human performance on VisualPuzzles, and that strong performance on knowledge-intensive benchmarks does not necessarily translate to success on reasoning-focused, knowledge-light tasks. Additionally, reasoning enhancements such as scaling up inference compute (with "thinking" modes) yield inconsistent gains across models and task types, and we observe no clear correlation between model size and performance. We also found that models exhibit different reasoning and answering patterns on VisualPuzzles compared to benchmarks with heavier emphasis on knowledge. VisualPuzzles offers a clearer lens through which to evaluate reasoning capabilities beyond factual recall and domain knowledge.
Speculative Thinking: Enhancing Small-Model Reasoning with Large Model Guidance at Inference Time
Apr 12, 2025



Recent advances leverage post-training to enhance model reasoning performance, which typically requires costly training pipelines and still suffers from inefficient, overly lengthy outputs. We introduce Speculative Thinking, a training-free framework that enables large reasoning models to guide smaller ones during inference at the reasoning level, distinct from speculative decoding, which operates at the token level. Our approach is based on two observations: (1) reasoning-supportive tokens such as "wait" frequently appear after structural delimiters like "\n\n", serving as signals for reflection or continuation; and (2) larger models exhibit stronger control over reflective behavior, reducing unnecessary backtracking while improving reasoning quality. By strategically delegating reflective steps to a more capable model, our method significantly boosts the reasoning accuracy of reasoning models while shortening their output. With the assistance of the 32B reasoning model, the 1.5B model's accuracy on MATH500 increases from 83.2% to 89.4%, marking a substantial improvement of 6.2%. Simultaneously, the average output length is reduced from 5439 tokens to 4583 tokens, representing a 15.7% decrease. Moreover, when applied to a non-reasoning model (Qwen-2.5-7B-Instruct), our framework boosts its accuracy from 74.0% to 81.8% on the same benchmark, achieving a relative improvement of 7.8%.
ScholarCopilot: Training Large Language Models for Academic Writing with Accurate Citations
Apr 03, 2025Academic writing requires both coherent text generation and precise citation of relevant literature. Although recent Retrieval-Augmented Generation (RAG) systems have significantly improved factual accuracy in general-purpose text generation, their ability to support professional academic writing remains limited. In this work, we introduce ScholarCopilot, a unified framework designed to enhance existing large language models for generating professional academic articles with accurate and contextually relevant citations. ScholarCopilot dynamically determines when to retrieve scholarly references by generating a retrieval token [RET], which is then used to query a citation database. The retrieved references are fed into the model to augment the generation process. We jointly optimize both the generation and citation tasks within a single framework to improve efficiency. Our model is built upon Qwen-2.5-7B and trained on 500K papers from arXiv. It achieves a top-1 retrieval accuracy of 40.1% on our evaluation dataset, outperforming baselines such as E5-Mistral-7B-Instruct (15.0%) and BM25 (9.8%). On a dataset of 1,000 academic writing samples, ScholarCopilot scores 16.2/25 in generation quality -- measured across relevance, coherence, academic rigor, completeness, and innovation -- significantly surpassing all existing models, including much larger ones like the Retrieval-Augmented Qwen2.5-72B-Instruct. Human studies further demonstrate that ScholarCopilot, despite being a 7B model, significantly outperforms ChatGPT, achieving 100% preference in citation quality and over 70% in overall usefulness.
Scaling Evaluation-time Compute with Reasoning Models as Process Evaluators
Mar 25, 2025As language model (LM) outputs get more and more natural, it is becoming more difficult than ever to evaluate their quality. Simultaneously, increasing LMs' "thinking" time through scaling test-time compute has proven an effective technique to solve challenging problems in domains such as math and code. This raises a natural question: can an LM's evaluation capability also be improved by spending more test-time compute? To answer this, we investigate employing reasoning models-LMs that natively generate long chain-of-thought reasoning-as evaluators. Specifically, we examine methods to leverage more test-time compute by (1) using reasoning models, and (2) prompting these models to evaluate not only the response as a whole (i.e., outcome evaluation) but also assess each step in the response separately (i.e., process evaluation). In experiments, we observe that the evaluator's performance improves monotonically when generating more reasoning tokens, similar to the trends observed in LM-based generation. Furthermore, we use these more accurate evaluators to rerank multiple generations, and demonstrate that spending more compute at evaluation time can be as effective as using more compute at generation time in improving an LM's problem-solving capability.