 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists
May 20, 2026With the advancement of AI capabilities, AI reviewers are beginning to be deployed in scientific peer review, yet their capability and credibility remain in question: many scientists simply view them as probabilistic systems without the expertise to evaluate research, while other researchers are more optimistic about their readiness without concrete evidence. Understanding what AI reviewers do well, where they fall short, and what challenges remain is essential. However, existing evaluations of AI reviewers have focused on whether their verdicts match human verdicts (e.g., score alignment, acceptance prediction), which is insufficient to characterize their capabilities and limits. In this paper, we close this gap through a large-scale expert annotation study, in which 45 domain scientists in Physical, Biological, and Health Sciences spent 469 hours rating 2,960 individual criticisms (each targeting one specific aspect of a paper) from human-written and AI-generated reviews of 82 Nature-family papers on correctness, significance, and sufficiency of evidence. On a composite of all three dimensions, a reviewing agent powered by GPT-5.2 scores above each paper's top-rated human reviewer (60.0% vs. 48.2%, p = 0.009), while all three AI reviewers (including Gemini 3.0 Pro and Claude Opus 4.5) exceed the lowest-rated human across every dimension. AI reviewers' accurate criticisms are also more often rated significant and well-evidenced, and surface a distinct 26% of issues no human raises. However, AI reviewers overlap far more than humans do (21% vs. 3% for cross-reviewer pairs), and exhibit 16 recurring weaknesses humans do not share, such as limited subfield knowledge, lack of long context management over multiple files, and overly critical stance on minor issues. Overall, our results position current AI reviewers as complements to, not substitutes for, human reviewers.
Compositional Steering of Large Language Models with Steering Tokens
Jan 08, 2026Deploying LLMs in real-world applications requires controllable output that satisfies multiple desiderata at the same time. While existing work extensively addresses LLM steering for a single behavior, \textit{compositional steering} -- i.e., steering LLMs simultaneously towards multiple behaviors -- remains an underexplored problem. In this work, we propose \emph{compositional steering tokens} for multi-behavior steering. We first embed individual behaviors, expressed as natural language instructions, into dedicated tokens via self-distillation. Contrary to most prior work, which operates in the activation space, our behavior steers live in the space of input tokens, enabling more effective zero-shot composition. We then train a dedicated \textit{composition token} on pairs of behaviors and show that it successfully captures the notion of composition: it generalizes well to \textit{unseen} compositions, including those with unseen behaviors as well as those with an unseen \textit{number} of behaviors. Our experiments across different LLM architectures show that steering tokens lead to superior multi-behavior control compared to competing approaches (instructions, activation steering, and LoRA merging). Moreover, we show that steering tokens complement natural language instructions, with their combination resulting in further gains.
TextMine: LLM-Powered Knowledge Extraction for Humanitarian Mine Action
Sep 18, 2025Humanitarian Mine Action has generated extensive best-practice knowledge, but much remains locked in unstructured reports. We introduce TextMine, an ontology-guided pipeline that uses Large Language Models to extract knowledge triples from HMA texts. TextMine integrates document chunking, domain-aware prompting, triple extraction, and both reference-based and LLM-as-a-Judge evaluation. We also create the first HMA ontology and a curated dataset of real-world demining reports. Experiments show ontology-aligned prompts boost extraction accuracy by 44.2%, cut hallucinations by 22.5%, and improve format conformance by 20.9% over baselines. While validated on Cambodian reports, TextMine can adapt to global demining efforts or other domains, transforming unstructured data into structured knowledge.
Scaling Evaluation-time Compute with Reasoning Models as Process Evaluators
Mar 25, 2025As language model (LM) outputs get more and more natural, it is becoming more difficult than ever to evaluate their quality. Simultaneously, increasing LMs' "thinking" time through scaling test-time compute has proven an effective technique to solve challenging problems in domains such as math and code. This raises a natural question: can an LM's evaluation capability also be improved by spending more test-time compute? To answer this, we investigate employing reasoning models-LMs that natively generate long chain-of-thought reasoning-as evaluators. Specifically, we examine methods to leverage more test-time compute by (1) using reasoning models, and (2) prompting these models to evaluate not only the response as a whole (i.e., outcome evaluation) but also assess each step in the response separately (i.e., process evaluation). In experiments, we observe that the evaluator's performance improves monotonically when generating more reasoning tokens, similar to the trends observed in LM-based generation. Furthermore, we use these more accurate evaluators to rerank multiple generations, and demonstrate that spending more compute at evaluation time can be as effective as using more compute at generation time in improving an LM's problem-solving capability.
Not-Just-Scaling Laws: Towards a Better Understanding of the Downstream Impact of Language Model Design Decisions
Mar 05, 2025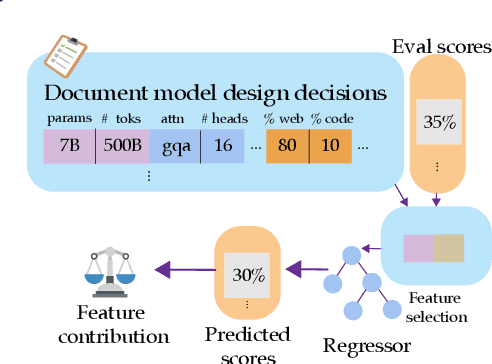
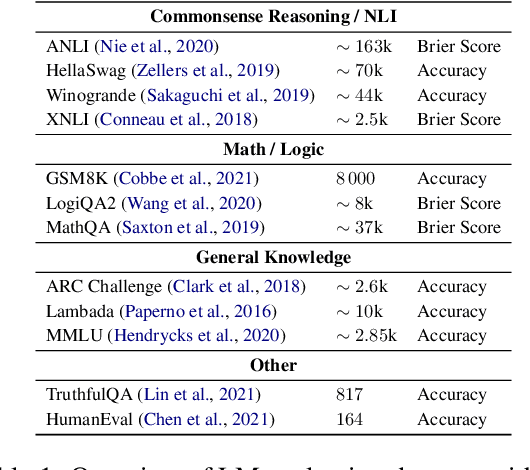
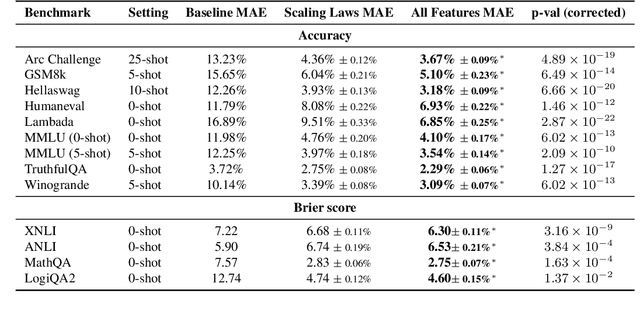
Improvements in language model capabilities are often attributed to increasing model size or training data, but in some cases smaller models trained on curated data or with different architectural decisions can outperform larger ones trained on more tokens. What accounts for this? To quantify the impact of these design choices, we meta-analyze 92 open-source pretrained models across a wide array of scales, including state-of-the-art open-weights models as well as less performant models and those with less conventional design decisions. We find that by incorporating features besides model size and number of training tokens, we can achieve a relative 3-28% increase in ability to predict downstream performance compared with using scale alone. Analysis of model design decisions reveal insights into data composition, such as the trade-off between language and code tasks at 15-25\% code, as well as the better performance of some architectural decisions such as choosing rotary over learned embeddings. Broadly, our framework lays a foundation for more systematic investigation of how model development choices shape final capabilities.
MEDDxAgent: A Unified Modular Agent Framework for Explainable Automatic Differential Diagnosis
Feb 26, 2025Differential Diagnosis (DDx) is a fundamental yet complex aspect of clinical decision-making, in which physicians iteratively refine a ranked list of possible diseases based on symptoms, antecedents, and medical knowledge. While recent advances in large language models have shown promise in supporting DDx, existing approaches face key limitations, including single-dataset evaluations, isolated optimization of components, unrealistic assumptions about complete patient profiles, and single-attempt diagnosis. We introduce a Modular Explainable DDx Agent (MEDDxAgent) framework designed for interactive DDx, where diagnostic reasoning evolves through iterative learning, rather than assuming a complete patient profile is accessible. MEDDxAgent integrates three modular components: (1) an orchestrator (DDxDriver), (2) a history taking simulator, and (3) two specialized agents for knowledge retrieval and diagnosis strategy. To ensure robust evaluation, we introduce a comprehensive DDx benchmark covering respiratory, skin, and rare diseases. We analyze single-turn diagnostic approaches and demonstrate the importance of iterative refinement when patient profiles are not available at the outset. Our broad evaluation demonstrates that MEDDxAgent achieves over 10% accuracy improvements in interactive DDx across both large and small LLMs, while offering critical explainability into its diagnostic reasoning process.
Evaluating Language Models as Synthetic Data Generators
Dec 04, 2024



Given the increasing use of synthetic data in language model (LM) post-training, an LM's ability to generate high-quality data has become nearly as crucial as its ability to solve problems directly. While prior works have focused on developing effective data generation methods, they lack systematic comparison of different LMs as data generators in a unified setting. To address this gap, we propose AgoraBench, a benchmark that provides standardized settings and metrics to evaluate LMs' data generation abilities. Through synthesizing 1.26 million training instances using 6 LMs and training 99 student models, we uncover key insights about LMs' data generation capabilities. First, we observe that LMs exhibit distinct strengths. For instance, GPT-4o excels at generating new problems, while Claude-3.5-Sonnet performs better at enhancing existing ones. Furthermore, our analysis reveals that an LM's data generation ability doesn't necessarily correlate with its problem-solving ability. Instead, multiple intrinsic features of data quality-including response quality, perplexity, and instruction difficulty-collectively serve as better indicators. Finally, we demonstrate that strategic choices in output format and cost-conscious model selection significantly impact data generation effectiveness.
Aligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
LightPAL: Lightweight Passage Retrieval for Open Domain Multi-Document Summarization
Jun 18, 2024



Open-Domain Multi-Document Summarization (ODMDS) is crucial for addressing diverse information needs, which aims to generate a summary as answer to user's query, synthesizing relevant content from multiple documents in a large collection. Existing approaches that first find relevant passages and then generate a summary using a language model are inadequate for ODMDS. This is because open-ended queries often require additional context for the retrieved passages to cover the topic comprehensively, making it challenging to retrieve all relevant passages initially. While iterative retrieval methods have been explored for multi-hop question answering (MQA), they are impractical for ODMDS due to high latency from repeated large language model (LLM) inference for reasoning. To address this issue, we propose LightPAL, a lightweight passage retrieval method for ODMDS that constructs a graph representing passage relationships using an LLM during indexing and employs random walk instead of iterative reasoning and retrieval at inference time. Experiments on ODMDS benchmarks show that LightPAL outperforms baseline retrievers in summary quality while being significantly more efficient than an iterative MQA approach.
AgentQuest: A Modular Benchmark Framework to Measure Progress and Improve LLM Agents
Apr 09, 2024The advances made by Large Language Models (LLMs) have led to the pursuit of LLM agents that can solve intricate, multi-step reasoning tasks. As with any research pursuit, benchmarking and evaluation are key corner stones to efficient and reliable progress. However, existing benchmarks are often narrow and simply compute overall task success. To face these issues, we propose AgentQuest -- a framework where (i) both benchmarks and metrics are modular and easily extensible through well documented and easy-to-use APIs; (ii) we offer two new evaluation metrics that can reliably track LLM agent progress while solving a task. We exemplify the utility of the metrics on two use cases wherein we identify common failure points and refine the agent architecture to obtain a significant performance increase. Together with the research community, we hope to extend AgentQuest further and therefore we make it available under https://github.com/nec-research/agentquest.