 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Steering of Large Language Models with Steering Tokens
Jan 08, 2026Deploying LLMs in real-world applications requires controllable output that satisfies multiple desiderata at the same time. While existing work extensively addresses LLM steering for a single behavior, \textit{compositional steering} -- i.e., steering LLMs simultaneously towards multiple behaviors -- remains an underexplored problem. In this work, we propose \emph{compositional steering tokens} for multi-behavior steering. We first embed individual behaviors, expressed as natural language instructions, into dedicated tokens via self-distillation. Contrary to most prior work, which operates in the activation space, our behavior steers live in the space of input tokens, enabling more effective zero-shot composition. We then train a dedicated \textit{composition token} on pairs of behaviors and show that it successfully captures the notion of composition: it generalizes well to \textit{unseen} compositions, including those with unseen behaviors as well as those with an unseen \textit{number} of behaviors. Our experiments across different LLM architectures show that steering tokens lead to superior multi-behavior control compared to competing approaches (instructions, activation steering, and LoRA merging). Moreover, we show that steering tokens complement natural language instructions, with their combination resulting in further gains.
Bridging Modalities and Transferring Knowledge: Enhanced Multimodal Understanding and Recognition
Dec 23, 2025This manuscript explores multimodal alignment, translation, fusion, and transference to enhance machine understanding of complex inputs. We organize the work into five chapters, each addressing unique challenges in multimodal machine learning. Chapter 3 introduces Spatial-Reasoning Bert for translating text-based spatial relations into 2D arrangements between clip-arts. This enables effective decoding of spatial language into visual representations, paving the way for automated scene generation aligned with human spatial understanding. Chapter 4 presents a method for translating medical texts into specific 3D locations within an anatomical atlas. We introduce a loss function leveraging spatial co-occurrences of medical terms to create interpretable mappings, significantly enhancing medical text navigability. Chapter 5 tackles translating structured text into canonical facts within knowledge graphs. We develop a benchmark for linking natural language to entities and predicates, addressing ambiguities in text extraction to provide clearer, actionable insights. Chapter 6 explores multimodal fusion methods for compositional action recognition. We propose a method fusing video frames and object detection representations, improving recognition robustness and accuracy. Chapter 7 investigates multimodal knowledge transference for egocentric action recognition. We demonstrate how multimodal knowledge distillation enables RGB-only models to mimic multimodal fusion-based capabilities, reducing computational requirements while maintaining performance. These contributions advance methodologies for spatial language understanding, medical text interpretation, knowledge graph enrichment, and action recognition, enhancing computational systems' ability to process complex, multimodal inputs across diverse applications.
Eff-GRot: Efficient and Generalizable Rotation Estimation with Transformers
Dec 21, 2025We introduce Eff-GRot, an approach for efficient and generalizable rotation estimation from RGB images. Given a query image and a set of reference images with known orientations, our method directly predicts the object's rotation in a single forward pass, without requiring object- or category-specific training. At the core of our framework is a transformer that performs a comparison in the latent space, jointly processing rotation-aware representations from multiple references alongside a query. This design enables a favorable balance between accuracy and computational efficiency while remaining simple, scalable, and fully end-to-end. Experimental results show that Eff-GRot offers a promising direction toward more efficient rotation estimation, particularly in latency-sensitive applications.
DAVE: Diagnostic benchmark for Audio Visual Evaluation
Mar 12, 2025Audio-visual understanding is a rapidly evolving field that seeks to integrate and interpret information from both auditory and visual modalities. Despite recent advances in multi-modal learning, existing benchmarks often suffer from strong visual bias -- where answers can be inferred from visual data alone -- and provide only aggregate scores that conflate multiple sources of error. This makes it difficult to determine whether models struggle with visual understanding, audio interpretation, or audio-visual alignment. In this work, we introduce DAVE (Diagnostic Audio Visual Evaluation), a novel benchmark dataset designed to systematically evaluate audio-visual models across controlled challenges. DAVE alleviates existing limitations by (i) ensuring both modalities are necessary to answer correctly and (ii) decoupling evaluation into atomic subcategories. Our detailed analysis of state-of-the-art models reveals specific failure modes and provides targeted insights for improvement. By offering this standardized diagnostic framework, we aim to facilitate more robust development of audio-visual models. The dataset is released: https://github.com/gorjanradevski/dave
Estimating calibration error under label shift without labels
Dec 14, 2023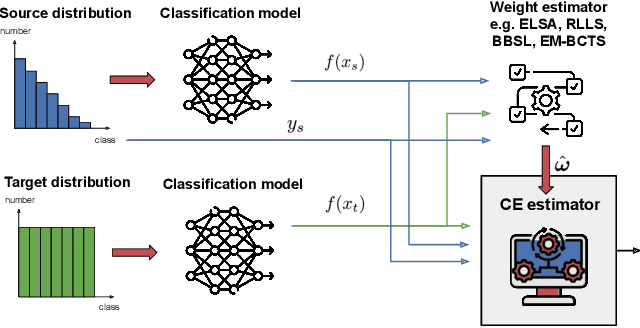



In the face of dataset shift, model calibration plays a pivotal role in ensuring the reliability of machine learning systems. Calibration error (CE) is an indicator of the alignment between the predicted probabilities and the classifier accuracy. While prior works have delved into the implications of dataset shift on calibration, existing CE estimators assume access to labels from the target domain, which are often unavailable in practice, i.e., when the model is deployed and used. This work addresses such challenging scenario, and proposes a novel CE estimator under label shift, which is characterized by changes in the marginal label distribution $p(Y)$, while keeping the conditional $p(X|Y)$ constant between the source and target distributions. Our contribution is an approach, which, by leveraging importance re-weighting of the labeled source distribution, provides consistent and asymptotically unbiased CE estimation with respect to the shifted target distribution. Empirical results across diverse real-world datasets, under various conditions and label-shift intensities, demonstrate the effectiveness and reliability of the proposed estimator.
Linking Surface Facts to Large-Scale Knowledge Graphs
Oct 23, 2023



Open Information Extraction (OIE) methods extract facts from natural language text in the form of ("subject"; "relation"; "object") triples. These facts are, however, merely surface forms, the ambiguity of which impedes their downstream usage; e.g., the surface phrase "Michael Jordan" may refer to either the former basketball player or the university professor. Knowledge Graphs (KGs), on the other hand, contain facts in a canonical (i.e., unambiguous) form, but their coverage is limited by a static schema (i.e., a fixed set of entities and predicates). To bridge this gap, we need the best of both worlds: (i) high coverage of free-text OIEs, and (ii) semantic precision (i.e., monosemy) of KGs. In order to achieve this goal, we propose a new benchmark with novel evaluation protocols that can, for example, measure fact linking performance on a granular triple slot level, while also measuring if a system has the ability to recognize that a surface form has no match in the existing KG. Our extensive evaluation of several baselines show that detection of out-of-KG entities and predicates is more difficult than accurate linking to existing ones, thus calling for more research efforts on this difficult task. We publicly release all resources (data, benchmark and code) on https://github.com/nec-research/fact-linking.
Multimodal Distillation for Egocentric Action Recognition
Jul 18, 2023



The focal point of egocentric video understanding is modelling hand-object interactions. Standard models, e.g. CNNs or Vision Transformers, which receive RGB frames as input perform well. However, their performance improves further by employing additional input modalities that provide complementary cues, such as object detections, optical flow, audio, etc. The added complexity of the modality-specific modules, on the other hand, makes these models impractical for deployment. The goal of this work is to retain the performance of such a multimodal approach, while using only the RGB frames as input at inference time. We demonstrate that for egocentric action recognition on the Epic-Kitchens and the Something-Something datasets, students which are taught by multimodal teachers tend to be more accurate and better calibrated than architecturally equivalent models trained on ground truth labels in a unimodal or multimodal fashion. We further adopt a principled multimodal knowledge distillation framework, allowing us to deal with issues which occur when applying multimodal knowledge distillation in a naive manner. Lastly, we demonstrate the achieved reduction in computational complexity, and show that our approach maintains higher performance with the reduction of the number of input views. We release our code at https://github.com/gorjanradevski/multimodal-distillation.
Students taught by multimodal teachers are superior action recognizers
Oct 09, 2022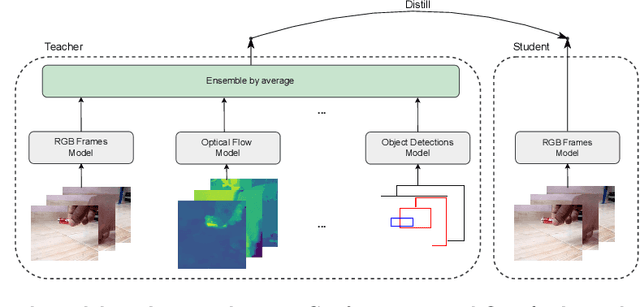

The focal point of egocentric video understanding is modelling hand-object interactions. Standard models -- CNNs, Vision Transformers, etc. -- which receive RGB frames as input perform well, however, their performance improves further by employing additional modalities such as object detections, optical flow, audio, etc. as input. The added complexity of the required modality-specific modules, on the other hand, makes these models impractical for deployment. The goal of this work is to retain the performance of such multimodal approaches, while using only the RGB images as input at inference time. Our approach is based on multimodal knowledge distillation, featuring a multimodal teacher (in the current experiments trained only using object detections, optical flow and RGB frames) and a unimodal student (using only RGB frames as input). We present preliminary results which demonstrate that the resulting model -- distilled from a multimodal teacher -- significantly outperforms the baseline RGB model (trained without knowledge distillation), as well as an omnivorous version of itself (trained on all modalities jointly), in both standard and compositional action recognition.
Revisiting spatio-temporal layouts for compositional action recognition
Nov 02, 2021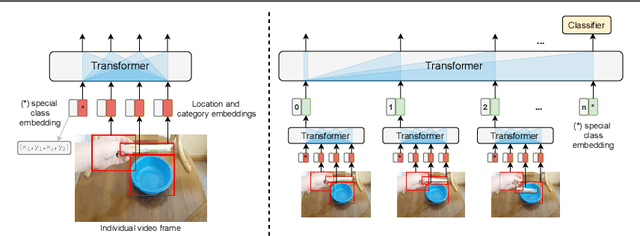
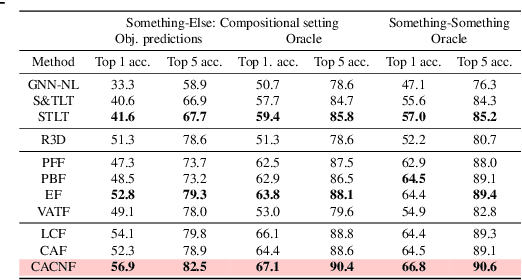
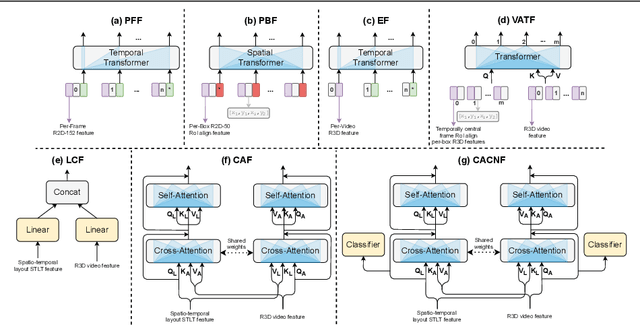
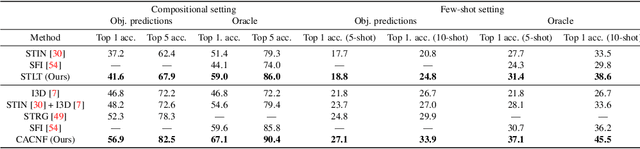
Recognizing human actions is fundamentally a spatio-temporal reasoning problem, and should be, at least to some extent, invariant to the appearance of the human and the objects involved. Motivated by this hypothesis, in this work, we take an object-centric approach to action recognition. Multiple works have studied this setting before, yet it remains unclear (i) how well a carefully crafted, spatio-temporal layout-based method can recognize human actions, and (ii) how, and when, to fuse the information from layout and appearance-based models. The main focus of this paper is compositional/few-shot action recognition, where we advocate the usage of multi-head attention (proven to be effective for spatial reasoning) over spatio-temporal layouts, i.e., configurations of object bounding boxes. We evaluate different schemes to inject video appearance information to the system, and benchmark our approach on background cluttered action recognition. On the Something-Else and Action Genome datasets, we demonstrate (i) how to extend multi-head attention for spatio-temporal layout-based action recognition, (ii) how to improve the performance of appearance-based models by fusion with layout-based models, (iii) that even on non-compositional background-cluttered video datasets, a fusion between layout- and appearance-based models improves the performance.