 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudents taught by multimodal teachers are superior action recognizers
Paper and Code
Oct 09, 2022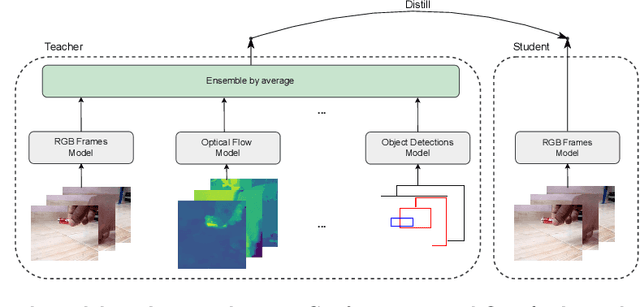

The focal point of egocentric video understanding is modelling hand-object interactions. Standard models -- CNNs, Vision Transformers, etc. -- which receive RGB frames as input perform well, however, their performance improves further by employing additional modalities such as object detections, optical flow, audio, etc. as input. The added complexity of the required modality-specific modules, on the other hand, makes these models impractical for deployment. The goal of this work is to retain the performance of such multimodal approaches, while using only the RGB images as input at inference time. Our approach is based on multimodal knowledge distillation, featuring a multimodal teacher (in the current experiments trained only using object detections, optical flow and RGB frames) and a unimodal student (using only RGB frames as input). We present preliminary results which demonstrate that the resulting model -- distilled from a multimodal teacher -- significantly outperforms the baseline RGB model (trained without knowledge distillation), as well as an omnivorous version of itself (trained on all modalities jointly), in both standard and compositional action recognition.