 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChromaFormer: A Scalable and Accurate Transformer Architecture for Land Cover Classification
Mar 11, 2025Remote sensing imagery from systems such as Sentinel provides full coverage of the Earth's surface at around 10-meter resolution. The remote sensing community has transitioned to extensive use of deep learning models due to their high performance on benchmarks such as the UCMerced and ISPRS Vaihingen datasets. Convolutional models such as UNet and ResNet variations are commonly employed for remote sensing but typically only accept three channels, as they were developed for RGB imagery, while satellite systems provide more than ten. Recently, several transformer architectures have been proposed for remote sensing, but they have not been extensively benchmarked and are typically used on small datasets such as Salinas Valley. Meanwhile, it is becoming feasible to obtain dense spatial land-use labels for entire first-level administrative divisions of some countries. Scaling law observations suggest that substantially larger multi-spectral transformer models could provide a significant leap in remote sensing performance in these settings. In this work, we propose ChromaFormer, a family of multi-spectral transformer models, which we evaluate across orders of magnitude differences in model parameters to assess their performance and scaling effectiveness on a densely labeled imagery dataset of Flanders, Belgium, covering more than 13,500 km^2 and containing 15 classes. We propose a novel multi-spectral attention strategy and demonstrate its effectiveness through ablations. Furthermore, we show that models many orders of magnitude larger than conventional architectures, such as UNet, lead to substantial accuracy improvements: a UNet++ model with 23M parameters achieves less than 65% accuracy, while a multi-spectral transformer with 655M parameters achieves over 95% accuracy on the Biological Valuation Map of Flanders.
Biological Valuation Map of Flanders: A Sentinel-2 Imagery Analysis
Jan 26, 2024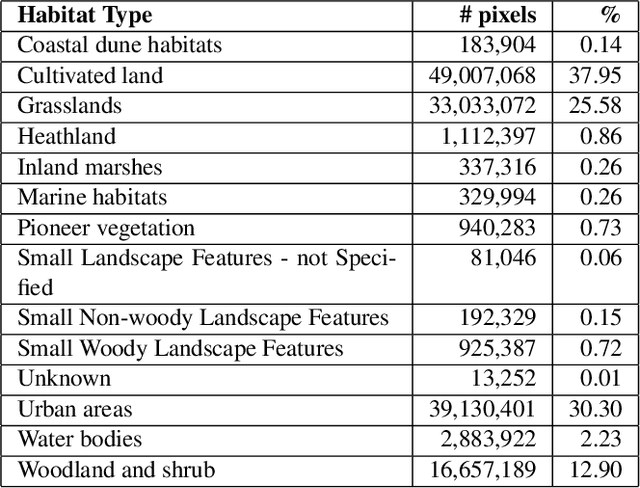

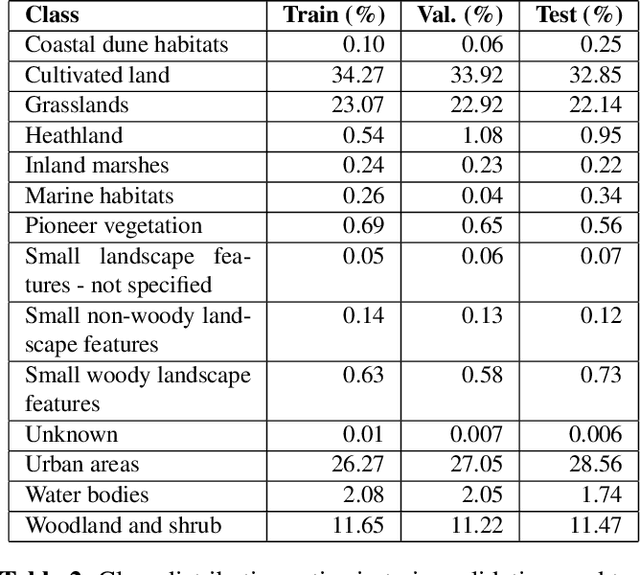

In recent years, machine learning has become crucial in remote sensing analysis, particularly in the domain of Land-use/Land-cover (LULC). The synergy of machine learning and satellite imagery analysis has demonstrated significant productivity in this field, as evidenced by several studies. A notable challenge within this area is the semantic segmentation mapping of land usage over extensive territories, where the accessibility of accurate land-use data and the reliability of ground truth land-use labels pose significant difficulties. For example, providing a detailed and accurate pixel-wise labeled dataset of the Flanders region, a first-level administrative division of Belgium, can be particularly insightful. Yet there is a notable lack of regulated, formalized datasets and workflows for such studies in many regions globally. This paper introduces a comprehensive approach to addressing these gaps. We present a densely labeled ground truth map of Flanders paired with Sentinel-2 satellite imagery. Our methodology includes a formalized dataset division and sampling method, utilizing the topographic map layout 'Kaartbladversnijdingen,' and a detailed semantic segmentation model training pipeline. Preliminary benchmarking results are also provided to demonstrate the efficacy of our approach.
Multimodal Distillation for Egocentric Action Recognition
Jul 18, 2023



The focal point of egocentric video understanding is modelling hand-object interactions. Standard models, e.g. CNNs or Vision Transformers, which receive RGB frames as input perform well. However, their performance improves further by employing additional input modalities that provide complementary cues, such as object detections, optical flow, audio, etc. The added complexity of the modality-specific modules, on the other hand, makes these models impractical for deployment. The goal of this work is to retain the performance of such a multimodal approach, while using only the RGB frames as input at inference time. We demonstrate that for egocentric action recognition on the Epic-Kitchens and the Something-Something datasets, students which are taught by multimodal teachers tend to be more accurate and better calibrated than architecturally equivalent models trained on ground truth labels in a unimodal or multimodal fashion. We further adopt a principled multimodal knowledge distillation framework, allowing us to deal with issues which occur when applying multimodal knowledge distillation in a naive manner. Lastly, we demonstrate the achieved reduction in computational complexity, and show that our approach maintains higher performance with the reduction of the number of input views. We release our code at https://github.com/gorjanradevski/multimodal-distillation.
Students taught by multimodal teachers are superior action recognizers
Oct 09, 2022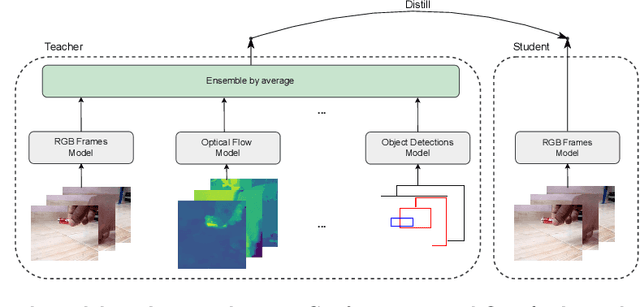

The focal point of egocentric video understanding is modelling hand-object interactions. Standard models -- CNNs, Vision Transformers, etc. -- which receive RGB frames as input perform well, however, their performance improves further by employing additional modalities such as object detections, optical flow, audio, etc. as input. The added complexity of the required modality-specific modules, on the other hand, makes these models impractical for deployment. The goal of this work is to retain the performance of such multimodal approaches, while using only the RGB images as input at inference time. Our approach is based on multimodal knowledge distillation, featuring a multimodal teacher (in the current experiments trained only using object detections, optical flow and RGB frames) and a unimodal student (using only RGB frames as input). We present preliminary results which demonstrate that the resulting model -- distilled from a multimodal teacher -- significantly outperforms the baseline RGB model (trained without knowledge distillation), as well as an omnivorous version of itself (trained on all modalities jointly), in both standard and compositional action recognition.
Predicting Physical World Destinations for Commands Given to Self-Driving Cars
Dec 10, 2021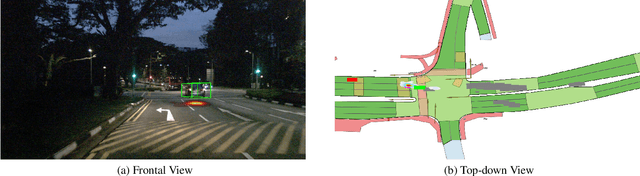
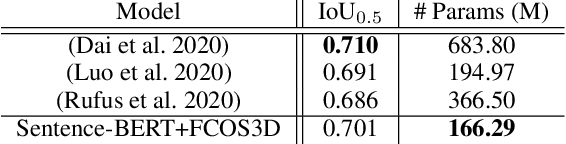

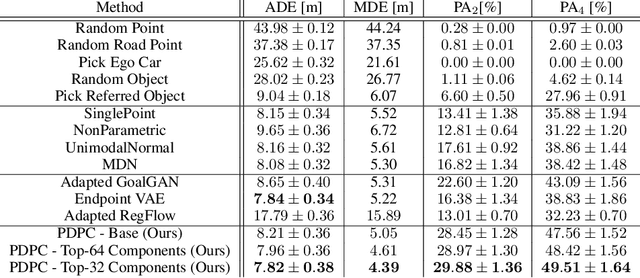
In recent years, we have seen significant steps taken in the development of self-driving cars. Multiple companies are starting to roll out impressive systems that work in a variety of settings. These systems can sometimes give the impression that full self-driving is just around the corner and that we would soon build cars without even a steering wheel. The increase in the level of autonomy and control given to an AI provides an opportunity for new modes of human-vehicle interaction. However, surveys have shown that giving more control to an AI in self-driving cars is accompanied by a degree of uneasiness by passengers. In an attempt to alleviate this issue, recent works have taken a natural language-oriented approach by allowing the passenger to give commands that refer to specific objects in the visual scene. Nevertheless, this is only half the task as the car should also understand the physical destination of the command, which is what we focus on in this paper. We propose an extension in which we annotate the 3D destination that the car needs to reach after executing the given command and evaluate multiple different baselines on predicting this destination location. Additionally, we introduce a model that outperforms the prior works adapted for this particular setting.
Commands 4 Autonomous Vehicles (C4AV) Workshop Summary
Sep 18, 2020
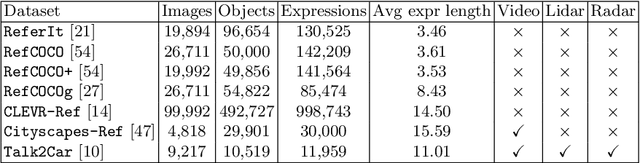

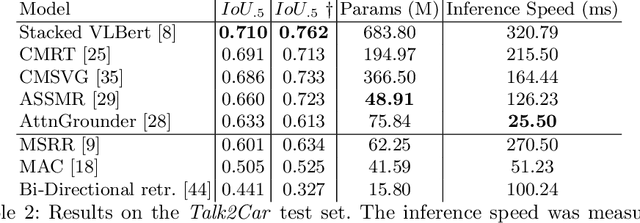
The task of visual grounding requires locating the most relevant region or object in an image, given a natural language query. So far, progress on this task was mostly measured on curated datasets, which are not always representative of human spoken language. In this work, we deviate from recent, popular task settings and consider the problem under an autonomous vehicle scenario. In particular, we consider a situation where passengers can give free-form natural language commands to a vehicle which can be associated with an object in the street scene. To stimulate research on this topic, we have organized the \emph{Commands for Autonomous Vehicles} (C4AV) challenge based on the recent \emph{Talk2Car} dataset (URL: https://www.aicrowd.com/challenges/eccv-2020-commands-4-autonomous-vehicles). This paper presents the results of the challenge. First, we compare the used benchmark against existing datasets for visual grounding. Second, we identify the aspects that render top-performing models successful, and relate them to existing state-of-the-art models for visual grounding, in addition to detecting potential failure cases by evaluating on carefully selected subsets. Finally, we discuss several possibilities for future work.
A Baseline for the Commands For Autonomous Vehicles Challenge
Apr 20, 2020
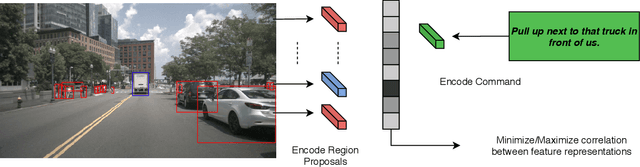
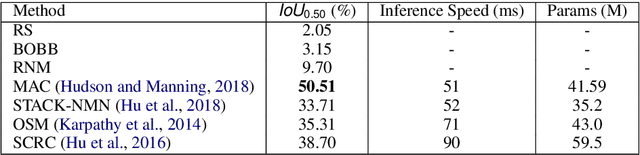
The Commands For Autonomous Vehicles (C4AV) challenge requires participants to solve an object referral task in a real-world setting. More specifically, we consider a scenario where a passenger can pass free-form natural language commands to a self-driving car. This problem is particularly challenging, as the language is much less constrained compared to existing benchmarks, and object references are often implicit. The challenge is based on the recent \texttt{Talk2Car} dataset. This document provides a technical overview of a model that we released to help participants get started in the competition. The code can be found at https://github.com/talk2car/Talk2Car.
Talk2Car: Taking Control of Your Self-Driving Car
Sep 24, 2019

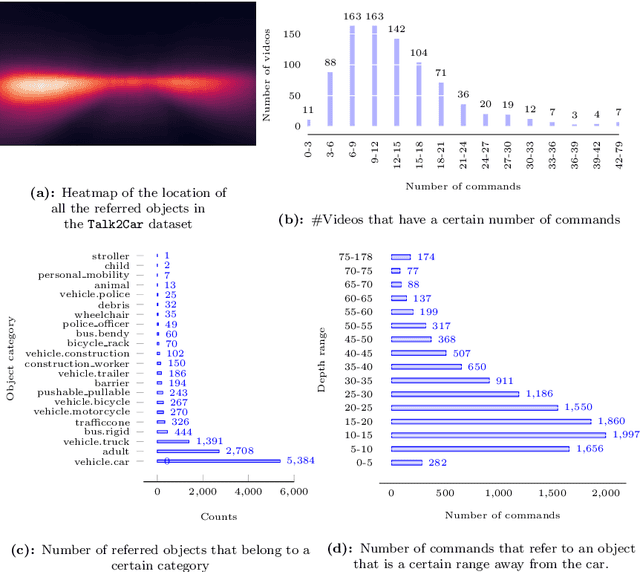
A long-term goal of artificial intelligence is to have an agent execute commands communicated through natural language. In many cases the commands are grounded in a visual environment shared by the human who gives the command and the agent. Execution of the command then requires mapping the command into the physical visual space, after which the appropriate action can be taken. In this paper we consider the former. Or more specifically, we consider the problem in an autonomous driving setting, where a passenger requests an action that can be associated with an object found in a street scene. Our work presents the Talk2Car dataset, which is the first object referral dataset that contains commands written in natural language for self-driving cars. We provide a detailed comparison with related datasets such as ReferIt, RefCOCO, RefCOCO+, RefCOCOg, Cityscape-Ref and CLEVR-Ref. Additionally, we include a performance analysis using strong state-of-the-art models. The results show that the proposed object referral task is a challenging one for which the models show promising results but still require additional research in natural language processing, computer vision and the intersection of these fields. The dataset can be found on our website: http://macchina-ai.eu/