 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgeons vs. Computer Vision: A comparative analysis on surgical phase recognition capabilities
Apr 26, 2025Purpose: Automated Surgical Phase Recognition (SPR) uses Artificial Intelligence (AI) to segment the surgical workflow into its key events, functioning as a building block for efficient video review, surgical education as well as skill assessment. Previous research has focused on short and linear surgical procedures and has not explored if temporal context influences experts' ability to better classify surgical phases. This research addresses these gaps, focusing on Robot-Assisted Partial Nephrectomy (RAPN) as a highly non-linear procedure. Methods: Urologists of varying expertise were grouped and tasked to indicate the surgical phase for RAPN on both single frames and video snippets using a custom-made web platform. Participants reported their confidence levels and the visual landmarks used in their decision-making. AI architectures without and with temporal context as trained and benchmarked on the Cholec80 dataset were subsequently trained on this RAPN dataset. Results: Video snippets and presence of specific visual landmarks improved phase classification accuracy across all groups. Surgeons displayed high confidence in their classifications and outperformed novices, who struggled discriminating phases. The performance of the AI models is comparable to the surgeons in the survey, with improvements when temporal context was incorporated in both cases. Conclusion: SPR is an inherently complex task for expert surgeons and computer vision, where both perform equally well when given the same context. Performance increases when temporal information is provided. Surgical tools and organs form the key landmarks for human interpretation and are expected to shape the future of automated SPR.
Multimodal Fusion Balancing Through Game-Theoretic Regularization
Nov 11, 2024



Multimodal learning can complete the picture of information extraction by uncovering key dependencies between data sources. However, current systems fail to fully leverage multiple modalities for optimal performance. This has been attributed to modality competition, where modalities strive for training resources, leaving some underoptimized. We show that current balancing methods struggle to train multimodal models that surpass even simple baselines, such as ensembles. This raises the question: how can we ensure that all modalities in multimodal training are sufficiently trained, and that learning from new modalities consistently improves performance? This paper proposes the Multimodal Competition Regularizer (MCR), a new loss component inspired by mutual information (MI) decomposition designed to prevent the adverse effects of competition in multimodal training. Our key contributions are: 1) Introducing game-theoretic principles in multimodal learning, where each modality acts as a player competing to maximize its influence on the final outcome, enabling automatic balancing of the MI terms. 2) Refining lower and upper bounds for each MI term to enhance the extraction of task-relevant unique and shared information across modalities. 3) Suggesting latent space permutations for conditional MI estimation, significantly improving computational efficiency. MCR outperforms all previously suggested training strategies and is the first to consistently improve multimodal learning beyond the ensemble baseline, clearly demonstrating that combining modalities leads to significant performance gains on both synthetic and large real-world datasets.
DistilDoc: Knowledge Distillation for Visually-Rich Document Applications
Jun 12, 2024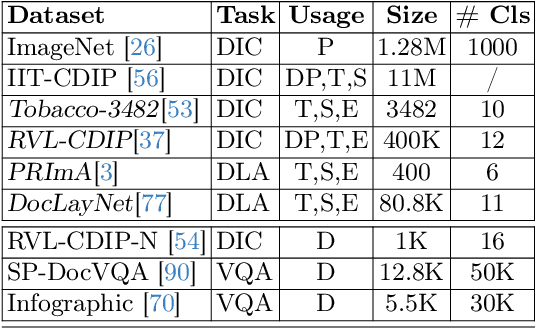
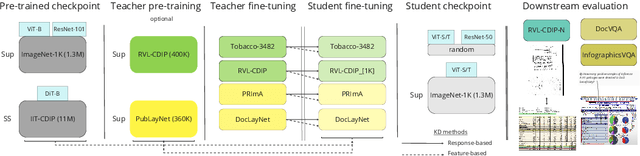
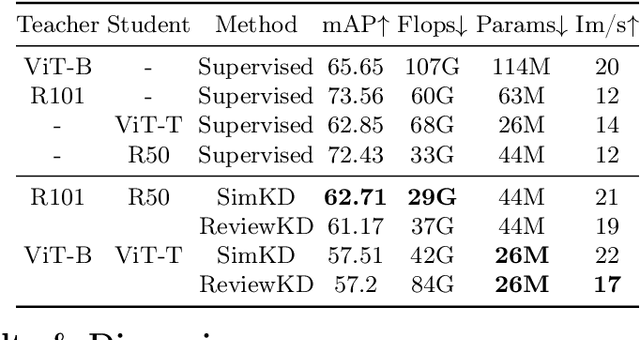
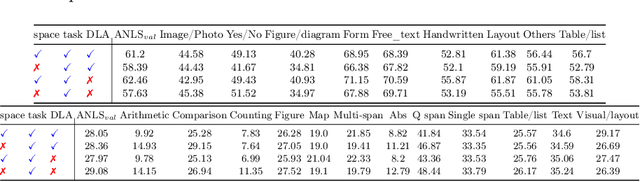
This work explores knowledge distillation (KD) for visually-rich document (VRD) applications such as document layout analysis (DLA) and document image classification (DIC). While VRD research is dependent on increasingly sophisticated and cumbersome models, the field has neglected to study efficiency via model compression. Here, we design a KD experimentation methodology for more lean, performant models on document understanding (DU) tasks that are integral within larger task pipelines. We carefully selected KD strategies (response-based, feature-based) for distilling knowledge to and from backbones with different architectures (ResNet, ViT, DiT) and capacities (base, small, tiny). We study what affects the teacher-student knowledge gap and find that some methods (tuned vanilla KD, MSE, SimKD with an apt projector) can consistently outperform supervised student training. Furthermore, we design downstream task setups to evaluate covariate shift and the robustness of distilled DLA models on zero-shot layout-aware document visual question answering (DocVQA). DLA-KD experiments result in a large mAP knowledge gap, which unpredictably translates to downstream robustness, accentuating the need to further explore how to efficiently obtain more semantic document layout awareness.
Multimodal Adaptive Inference for Document Image Classification with Anytime Early Exiting
May 21, 2024This work addresses the need for a balanced approach between performance and efficiency in scalable production environments for visually-rich document understanding (VDU) tasks. Currently, there is a reliance on large document foundation models that offer advanced capabilities but come with a heavy computational burden. In this paper, we propose a multimodal early exit (EE) model design that incorporates various training strategies, exit layer types and placements. Our goal is to achieve a Pareto-optimal balance between predictive performance and efficiency for multimodal document image classification. Through a comprehensive set of experiments, we compare our approach with traditional exit policies and showcase an improved performance-efficiency trade-off. Our multimodal EE design preserves the model's predictive capabilities, enhancing both speed and latency. This is achieved through a reduction of over 20% in latency, while fully retaining the baseline accuracy. This research represents the first exploration of multimodal EE design within the VDU community, highlighting as well the effectiveness of calibration in improving confidence scores for exiting at different layers. Overall, our findings contribute to practical VDU applications by enhancing both performance and efficiency.
Improving Multimodal Learning with Multi-Loss Gradient Modulation
May 13, 2024



Learning from multiple modalities, such as audio and video, offers opportunities for leveraging complementary information, enhancing robustness, and improving contextual understanding and performance. However, combining such modalities presents challenges, especially when modalities differ in data structure, predictive contribution, and the complexity of their learning processes. It has been observed that one modality can potentially dominate the learning process, hindering the effective utilization of information from other modalities and leading to sub-optimal model performance. To address this issue the vast majority of previous works suggest to assess the unimodal contributions and dynamically adjust the training to equalize them. We improve upon previous work by introducing a multi-loss objective and further refining the balancing process, allowing it to dynamically adjust the learning pace of each modality in both directions, acceleration and deceleration, with the ability to phase out balancing effects upon convergence. We achieve superior results across three audio-video datasets: on CREMA-D, models with ResNet backbone encoders surpass the previous best by 1.9% to 12.4%, and Conformer backbone models deliver improvements ranging from 2.8% to 14.1% across different fusion methods. On AVE, improvements range from 2.7% to 7.7%, while on UCF101, gains reach up to 6.1%.
Multimodal Distillation for Egocentric Action Recognition
Jul 18, 2023



The focal point of egocentric video understanding is modelling hand-object interactions. Standard models, e.g. CNNs or Vision Transformers, which receive RGB frames as input perform well. However, their performance improves further by employing additional input modalities that provide complementary cues, such as object detections, optical flow, audio, etc. The added complexity of the modality-specific modules, on the other hand, makes these models impractical for deployment. The goal of this work is to retain the performance of such a multimodal approach, while using only the RGB frames as input at inference time. We demonstrate that for egocentric action recognition on the Epic-Kitchens and the Something-Something datasets, students which are taught by multimodal teachers tend to be more accurate and better calibrated than architecturally equivalent models trained on ground truth labels in a unimodal or multimodal fashion. We further adopt a principled multimodal knowledge distillation framework, allowing us to deal with issues which occur when applying multimodal knowledge distillation in a naive manner. Lastly, we demonstrate the achieved reduction in computational complexity, and show that our approach maintains higher performance with the reduction of the number of input views. We release our code at https://github.com/gorjanradevski/multimodal-distillation.
Document Understanding Dataset and Evaluation (DUDE)
May 15, 2023
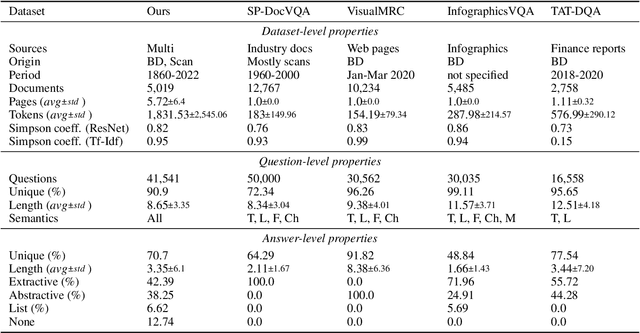
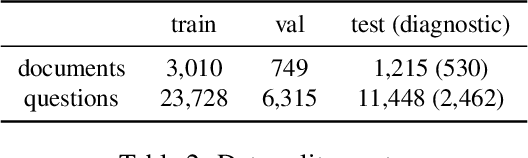
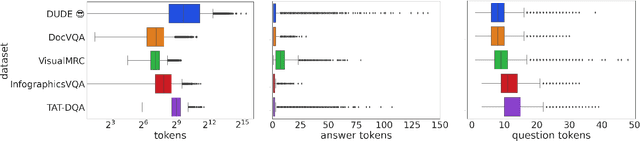
We call on the Document AI (DocAI) community to reevaluate current methodologies and embrace the challenge of creating more practically-oriented benchmarks. Document Understanding Dataset and Evaluation (DUDE) seeks to remediate the halted research progress in understanding visually-rich documents (VRDs). We present a new dataset with novelties related to types of questions, answers, and document layouts based on multi-industry, multi-domain, and multi-page VRDs of various origins, and dates. Moreover, we are pushing the boundaries of current methods by creating multi-task and multi-domain evaluation setups that more accurately simulate real-world situations where powerful generalization and adaptation under low-resource settings are desired. DUDE aims to set a new standard as a more practical, long-standing benchmark for the community, and we hope that it will lead to future extensions and contributions that address real-world challenges. Finally, our work illustrates the importance of finding more efficient ways to model language, images, and layout in DocAI.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Students taught by multimodal teachers are superior action recognizers
Oct 09, 2022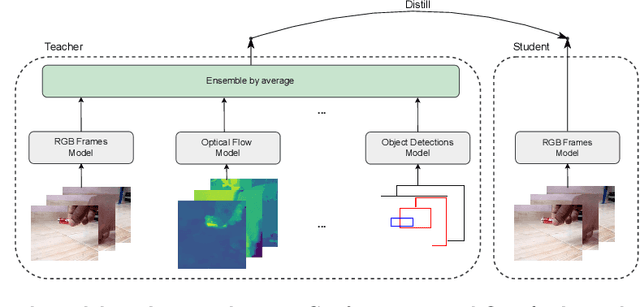

The focal point of egocentric video understanding is modelling hand-object interactions. Standard models -- CNNs, Vision Transformers, etc. -- which receive RGB frames as input perform well, however, their performance improves further by employing additional modalities such as object detections, optical flow, audio, etc. as input. The added complexity of the required modality-specific modules, on the other hand, makes these models impractical for deployment. The goal of this work is to retain the performance of such multimodal approaches, while using only the RGB images as input at inference time. Our approach is based on multimodal knowledge distillation, featuring a multimodal teacher (in the current experiments trained only using object detections, optical flow and RGB frames) and a unimodal student (using only RGB frames as input). We present preliminary results which demonstrate that the resulting model -- distilled from a multimodal teacher -- significantly outperforms the baseline RGB model (trained without knowledge distillation), as well as an omnivorous version of itself (trained on all modalities jointly), in both standard and compositional action recognition.
Predicting Physical World Destinations for Commands Given to Self-Driving Cars
Dec 10, 2021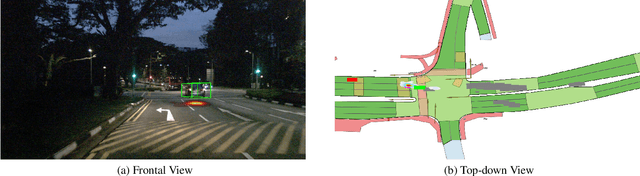
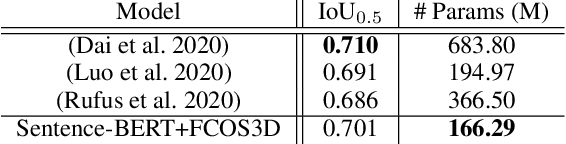

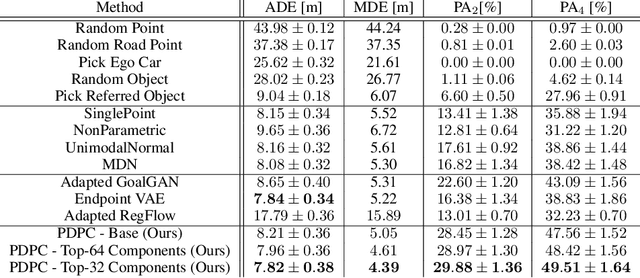
In recent years, we have seen significant steps taken in the development of self-driving cars. Multiple companies are starting to roll out impressive systems that work in a variety of settings. These systems can sometimes give the impression that full self-driving is just around the corner and that we would soon build cars without even a steering wheel. The increase in the level of autonomy and control given to an AI provides an opportunity for new modes of human-vehicle interaction. However, surveys have shown that giving more control to an AI in self-driving cars is accompanied by a degree of uneasiness by passengers. In an attempt to alleviate this issue, recent works have taken a natural language-oriented approach by allowing the passenger to give commands that refer to specific objects in the visual scene. Nevertheless, this is only half the task as the car should also understand the physical destination of the command, which is what we focus on in this paper. We propose an extension in which we annotate the 3D destination that the car needs to reach after executing the given command and evaluate multiple different baselines on predicting this destination location. Additionally, we introduce a model that outperforms the prior works adapted for this particular setting.