 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic Information Extraction from Transactional Documents
Dec 10, 2025This paper presents a neurosymbolic framework for information extraction from documents, evaluated on transactional documents. We introduce a schema-based approach that integrates symbolic validation methods to enable more effective zero-shot output and knowledge distillation. The methodology uses language models to generate candidate extractions, which are then filtered through syntactic-, task-, and domain-level validation to ensure adherence to domain-specific arithmetic constraints. Our contributions include a comprehensive schema for transactional documents, relabeled datasets, and an approach for generating high-quality labels for knowledge distillation. Experimental results demonstrate significant improvements in $F_1$-scores and accuracy, highlighting the effectiveness of neurosymbolic validation in transactional document processing.
* 20 pages, 2 figures, accepted to IJDAR (ICDAR 2025)
KhmerST: A Low-Resource Khmer Scene Text Detection and Recognition Benchmark
Oct 23, 2024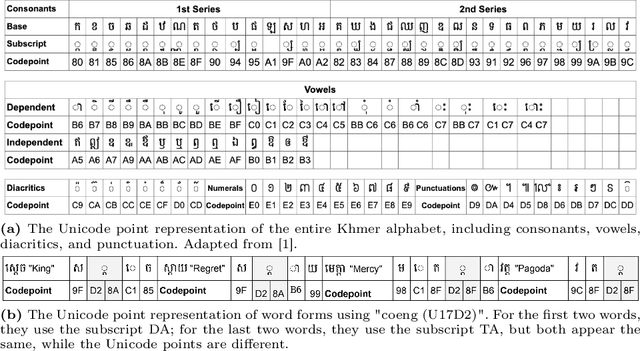
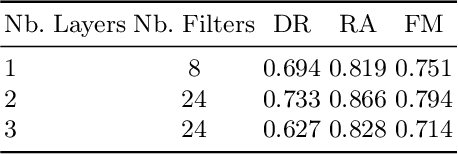

Developing effective scene text detection and recognition models hinges on extensive training data, which can be both laborious and costly to obtain, especially for low-resourced languages. Conventional methods tailored for Latin characters often falter with non-Latin scripts due to challenges like character stacking, diacritics, and variable character widths without clear word boundaries. In this paper, we introduce the first Khmer scene-text dataset, featuring 1,544 expert-annotated images, including 997 indoor and 547 outdoor scenes. This diverse dataset includes flat text, raised text, poorly illuminated text, distant and partially obscured text. Annotations provide line-level text and polygonal bounding box coordinates for each scene. The benchmark includes baseline models for scene-text detection and recognition tasks, providing a robust starting point for future research endeavors. The KhmerST dataset is publicly accessible at https://gitlab.com/vannkinhnom123/khmerst.
Confidence-Aware Document OCR Error Detection
Sep 06, 2024Optical Character Recognition (OCR) continues to face accuracy challenges that impact subsequent applications. To address these errors, we explore the utility of OCR confidence scores for enhancing post-OCR error detection. Our study involves analyzing the correlation between confidence scores and error rates across different OCR systems. We develop ConfBERT, a BERT-based model that incorporates OCR confidence scores into token embeddings and offers an optional pre-training phase for noise adjustment. Our experimental results demonstrate that integrating OCR confidence scores can enhance error detection capabilities. This work underscores the importance of OCR confidence scores in improving detection accuracy and reveals substantial disparities in performance between commercial and open-source OCR technologies.
IDTrust: Deep Identity Document Quality Detection with Bandpass Filtering
Mar 01, 2024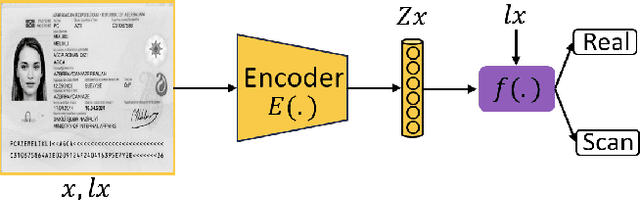
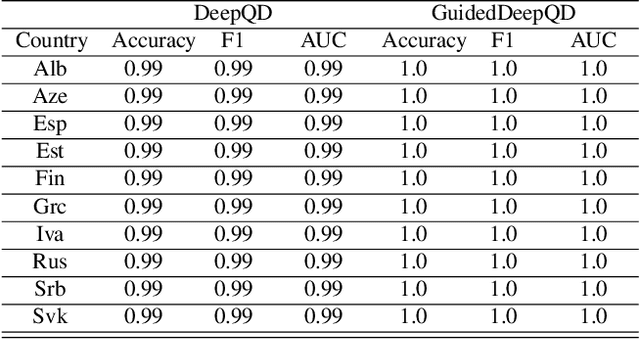
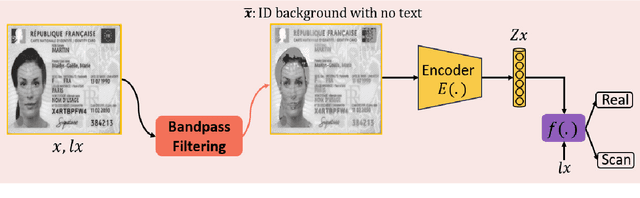
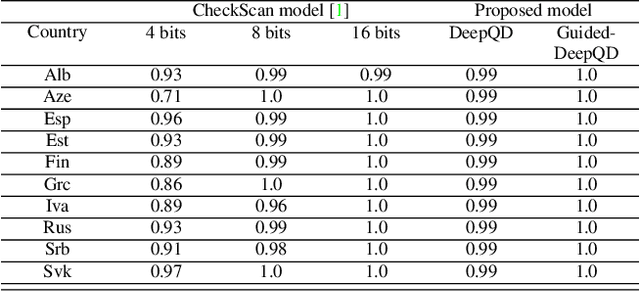
The increasing use of digital technologies and mobile-based registration procedures highlights the vital role of personal identity documents (IDs) in verifying users and safeguarding sensitive information. However, the rise in counterfeit ID production poses a significant challenge, necessitating the development of reliable and efficient automated verification methods. This paper introduces IDTrust, a deep-learning framework for assessing the quality of IDs. IDTrust is a system that enhances the quality of identification documents by using a deep learning-based approach. This method eliminates the need for relying on original document patterns for quality checks and pre-processing steps for alignment. As a result, it offers significant improvements in terms of dataset applicability. By utilizing a bandpass filtering-based method, the system aims to effectively detect and differentiate ID quality. Comprehensive experiments on the MIDV-2020 and L3i-ID datasets identify optimal parameters, significantly improving discrimination performance and effectively distinguishing between original and scanned ID documents.
Lazy-k: Decoding for Constrained Token Classification
Dec 06, 2023We explore the possibility of improving probabilistic models in structured prediction. Specifically, we combine the models with constrained decoding approaches in the context of token classification for information extraction. The decoding methods search for constraint-satisfying label-assignments while maximizing the total probability. To do this, we evaluate several existing approaches, as well as propose a novel decoding method called Lazy-$k$. Our findings demonstrate that constrained decoding approaches can significantly improve the models' performances, especially when using smaller models. The Lazy-$k$ approach allows for more flexibility between decoding time and accuracy. The code for using Lazy-$k$ decoding can be found here: https://github.com/ArthurDevNL/lazyk.
Estimating Post-OCR Denoising Complexity on Numerical Texts
Jul 03, 2023Post-OCR processing has significantly improved over the past few years. However, these have been primarily beneficial for texts consisting of natural, alphabetical words, as opposed to documents of numerical nature such as invoices, payslips, medical certificates, etc. To evaluate the OCR post-processing difficulty of these datasets, we propose a method to estimate the denoising complexity of a text and evaluate it on several datasets of varying nature, and show that texts of numerical nature have a significant disadvantage. We evaluate the estimated complexity ranking with respect to the error rates of modern-day denoising approaches to show the validity of our estimator.
Document Understanding Dataset and Evaluation (DUDE)
May 15, 2023
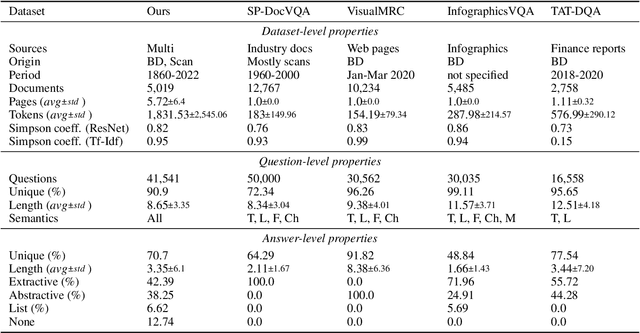
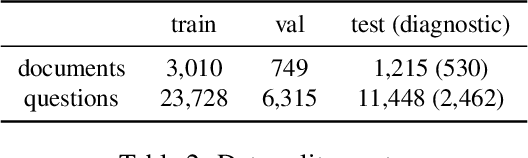
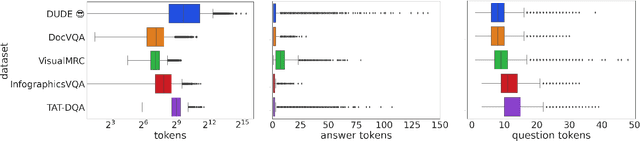
We call on the Document AI (DocAI) community to reevaluate current methodologies and embrace the challenge of creating more practically-oriented benchmarks. Document Understanding Dataset and Evaluation (DUDE) seeks to remediate the halted research progress in understanding visually-rich documents (VRDs). We present a new dataset with novelties related to types of questions, answers, and document layouts based on multi-industry, multi-domain, and multi-page VRDs of various origins, and dates. Moreover, we are pushing the boundaries of current methods by creating multi-task and multi-domain evaluation setups that more accurately simulate real-world situations where powerful generalization and adaptation under low-resource settings are desired. DUDE aims to set a new standard as a more practical, long-standing benchmark for the community, and we hope that it will lead to future extensions and contributions that address real-world challenges. Finally, our work illustrates the importance of finding more efficient ways to model language, images, and layout in DocAI.
DocILE Benchmark for Document Information Localization and Extraction
Feb 11, 2023


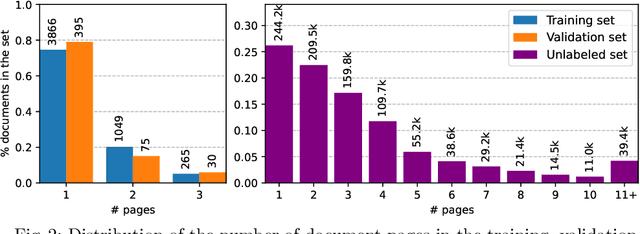
This paper introduces the DocILE benchmark with the largest dataset of business documents for the tasks of Key Information Localization and Extraction and Line Item Recognition. It contains 6.7k annotated business documents, 100k synthetically generated documents, and nearly~1M unlabeled documents for unsupervised pre-training. The dataset has been built with knowledge of domain- and task-specific aspects, resulting in the following key features: (i) annotations in 55 classes, which surpasses the granularity of previously published key information extraction datasets by a large margin; (ii) Line Item Recognition represents a highly practical information extraction task, where key information has to be assigned to items in a table; (iii) documents come from numerous layouts and the test set includes zero- and few-shot cases as well as layouts commonly seen in the training set. The benchmark comes with several baselines, including RoBERTa, LayoutLMv3 and DETR-based Table Transformer. These baseline models were applied to both tasks of the DocILE benchmark, with results shared in this paper, offering a quick starting point for future work. The dataset and baselines are available at https://github.com/rossumai/docile.
Performance Evaluation of Deep Generative Models for Generating Hand-Written Character Images
Feb 26, 2020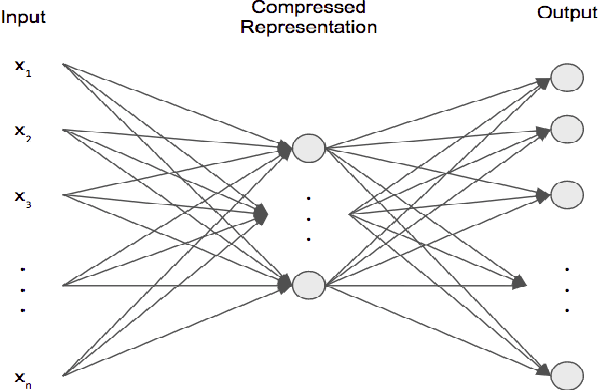
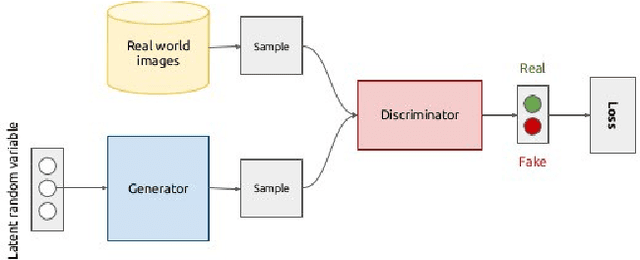
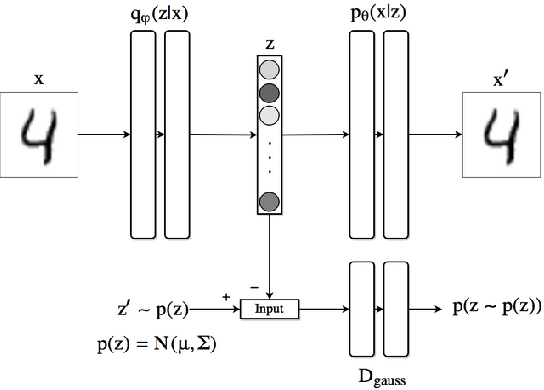
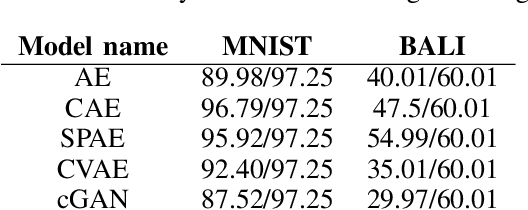
There have been many work in the literature on generation of various kinds of images such as Hand-Written characters (MNIST dataset), scene images (CIFAR-10 dataset), various objects images (ImageNet dataset), road signboard images (SVHN dataset) etc. Unfortunately, there have been very limited amount of work done in the domain of document image processing. Automatic image generation can lead to the enormous increase of labeled datasets with the help of only limited amount of labeled data. Various kinds of Deep generative models can be primarily divided into two categories. First category is auto-encoder (AE) and the second one is Generative Adversarial Networks (GANs). In this paper, we have evaluated various kinds of AE as well as GANs and have compared their performances on hand-written digits dataset (MNIST) and also on historical hand-written character dataset of Indonesian BALI language. Moreover, these generated characters are recognized by using character recognition tool for calculating the statistical performance of these generated characters with respect to original character images.