 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYes but.. Can ChatGPT Identify Entities in Historical Documents?
Mar 30, 2023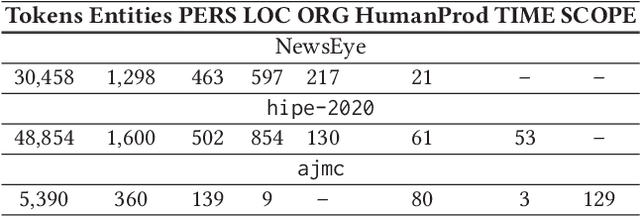


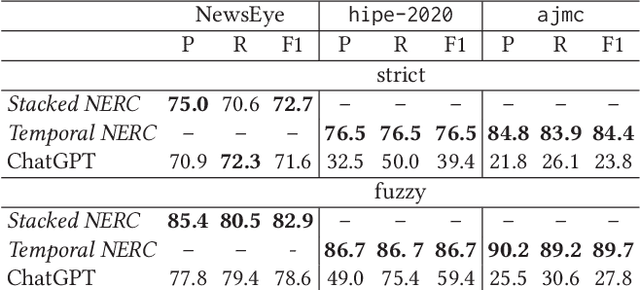
Large language models (LLMs) have been leveraged for several years now, obtaining state-of-the-art performance in recognizing entities from modern documents. For the last few months, the conversational agent ChatGPT has "prompted" a lot of interest in the scientific community and public due to its capacity of generating plausible-sounding answers. In this paper, we explore this ability by probing it in the named entity recognition and classification (NERC) task in primary sources (e.g., historical newspapers and classical commentaries) in a zero-shot manner and by comparing it with state-of-the-art LM-based systems. Our findings indicate several shortcomings in identifying entities in historical text that range from the consistency of entity annotation guidelines, entity complexity, and code-switching, to the specificity of prompting. Moreover, as expected, the inaccessibility of historical archives to the public (and thus on the Internet) also impacts its performance.
DocILE Benchmark for Document Information Localization and Extraction
Feb 11, 2023


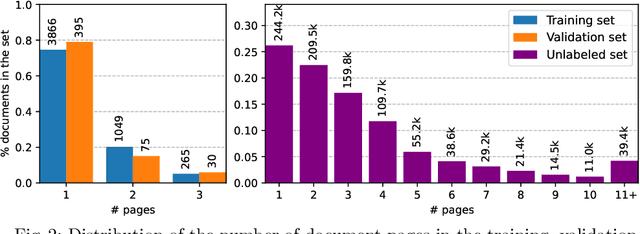
This paper introduces the DocILE benchmark with the largest dataset of business documents for the tasks of Key Information Localization and Extraction and Line Item Recognition. It contains 6.7k annotated business documents, 100k synthetically generated documents, and nearly~1M unlabeled documents for unsupervised pre-training. The dataset has been built with knowledge of domain- and task-specific aspects, resulting in the following key features: (i) annotations in 55 classes, which surpasses the granularity of previously published key information extraction datasets by a large margin; (ii) Line Item Recognition represents a highly practical information extraction task, where key information has to be assigned to items in a table; (iii) documents come from numerous layouts and the test set includes zero- and few-shot cases as well as layouts commonly seen in the training set. The benchmark comes with several baselines, including RoBERTa, LayoutLMv3 and DETR-based Table Transformer. These baseline models were applied to both tasks of the DocILE benchmark, with results shared in this paper, offering a quick starting point for future work. The dataset and baselines are available at https://github.com/rossumai/docile.
DocILE 2023 Teaser: Document Information Localization and Extraction
Jan 29, 2023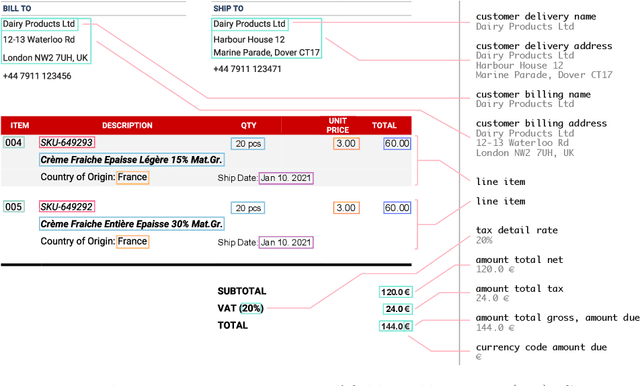
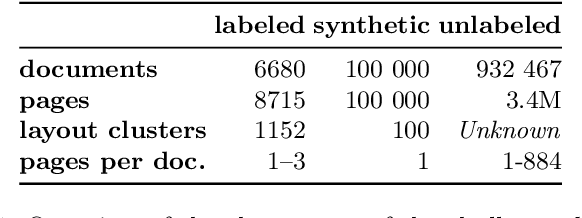


The lack of data for information extraction (IE) from semi-structured business documents is a real problem for the IE community. Publications relying on large-scale datasets use only proprietary, unpublished data due to the sensitive nature of such documents. Publicly available datasets are mostly small and domain-specific. The absence of a large-scale public dataset or benchmark hinders the reproducibility and cross-evaluation of published methods. The DocILE 2023 competition, hosted as a lab at the CLEF 2023 conference and as an ICDAR 2023 competition, will run the first major benchmark for the tasks of Key Information Localization and Extraction (KILE) and Line Item Recognition (LIR) from business documents. With thousands of annotated real documents from open sources, a hundred thousand of generated synthetic documents, and nearly a million unlabeled documents, the DocILE lab comes with the largest publicly available dataset for KILE and LIR. We are looking forward to contributions from the Computer Vision, Natural Language Processing, Information Retrieval, and other communities. The data, baselines, code and up-to-date information about the lab and competition are available at https://docile.rossum.ai/.
Named Entity Recognition and Classification on Historical Documents: A Survey
Sep 23, 2021

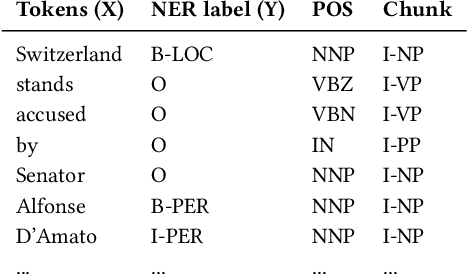

After decades of massive digitisation, an unprecedented amount of historical documents is available in digital format, along with their machine-readable texts. While this represents a major step forward with respect to preservation and accessibility, it also opens up new opportunities in terms of content mining and the next fundamental challenge is to develop appropriate technologies to efficiently search, retrieve and explore information from this 'big data of the past'. Among semantic indexing opportunities, the recognition and classification of named entities are in great demand among humanities scholars. Yet, named entity recognition (NER) systems are heavily challenged with diverse, historical and noisy inputs. In this survey, we present the array of challenges posed by historical documents to NER, inventory existing resources, describe the main approaches deployed so far, and identify key priorities for future developments.