 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying several dialectal Nawatl varieties
Jan 05, 2026Mexico is a country with a large number of indigenous languages, among which the most widely spoken is Nawatl, with more than two million people currently speaking it (mainly in North and Central America). Despite its rich cultural heritage, which dates back to the 15th century, Nawatl is a language with few computer resources. The problem is compounded when it comes to its dialectal varieties, with approximately 30 varieties recognised, not counting the different spellings in the written forms of the language. In this research work, we addressed the problem of classifying Nawatl varieties using Machine Learning and Neural Networks.
$π$-yalli: un nouveau corpus pour le nahuatl
Dec 20, 2024



The NAHU$^2$ project is a Franco-Mexican collaboration aimed at building the $\pi$-YALLI corpus adapted to machine learning, which will subsequently be used to develop computer resources for the Nahuatl language. Nahuatl is a language with few computational resources, even though it is a living language spoken by around 2 million people. We have decided to build $\pi$-YALLI, a corpus that will enable to carry out research on Nahuatl in order to develop Language Models (LM), whether dynamic or not, which will make it possible to in turn enable the development of Natural Language Processing (NLP) tools such as: a) a grapheme unifier, b) a word segmenter, c) a POS grammatical analyser, d) a content-based Automatic Text Summarization; and possibly, e) a translator translator (probabilistic or learning-based).
L3iTC at the FinLLM Challenge Task: Quantization for Financial Text Classification & Summarization
Aug 06, 2024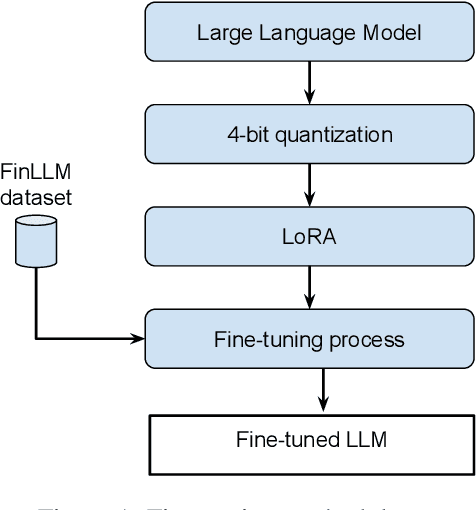


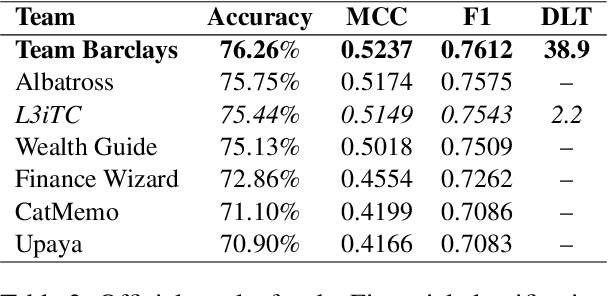
This article details our participation (L3iTC) in the FinLLM Challenge Task 2024, focusing on two key areas: Task 1, financial text classification, and Task 2, financial text summarization. To address these challenges, we fine-tuned several large language models (LLMs) to optimize performance for each task. Specifically, we used 4-bit quantization and LoRA to determine which layers of the LLMs should be trained at a lower precision. This approach not only accelerated the fine-tuning process on the training data provided by the organizers but also enabled us to run the models on low GPU memory. Our fine-tuned models achieved third place for the financial classification task with an F1-score of 0.7543 and secured sixth place in the financial summarization task on the official test datasets.
CoastTerm: a Corpus for Multidisciplinary Term Extraction in Coastal Scientific Literature
Jun 13, 2024



The growing impact of climate change on coastal areas, particularly active but fragile regions, necessitates collaboration among diverse stakeholders and disciplines to formulate effective environmental protection policies. We introduce a novel specialized corpus comprising 2,491 sentences from 410 scientific abstracts concerning coastal areas, for the Automatic Term Extraction (ATE) and Classification (ATC) tasks. Inspired by the ARDI framework, focused on the identification of Actors, Resources, Dynamics and Interactions, we automatically extract domain terms and their distinct roles in the functioning of coastal systems by leveraging monolingual and multilingual transformer models. The evaluation demonstrates consistent results, achieving an F1 score of approximately 80\% for automated term extraction and F1 of 70\% for extracting terms and their labels. These findings are promising and signify an initial step towards the development of a specialized Knowledge Base dedicated to coastal areas.
A Comprehensive Survey of Document-level Relation Extraction (2016-2023)
Oct 12, 2023



Document-level relation extraction (DocRE) is an active area of research in natural language processing (NLP) concerned with identifying and extracting relationships between entities beyond sentence boundaries. Compared to the more traditional sentence-level relation extraction, DocRE provides a broader context for analysis and is more challenging because it involves identifying relationships that may span multiple sentences or paragraphs. This task has gained increased interest as a viable solution to build and populate knowledge bases automatically from unstructured large-scale documents (e.g., scientific papers, legal contracts, or news articles), in order to have a better understanding of relationships between entities. This paper aims to provide a comprehensive overview of recent advances in this field, highlighting its different applications in comparison to sentence-level relation extraction.
Yes but.. Can ChatGPT Identify Entities in Historical Documents?
Mar 30, 2023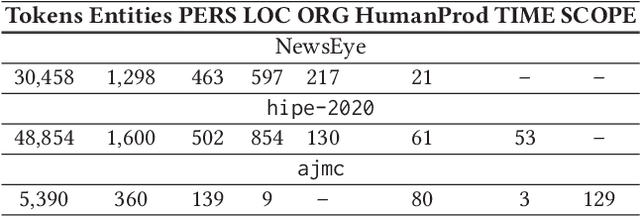


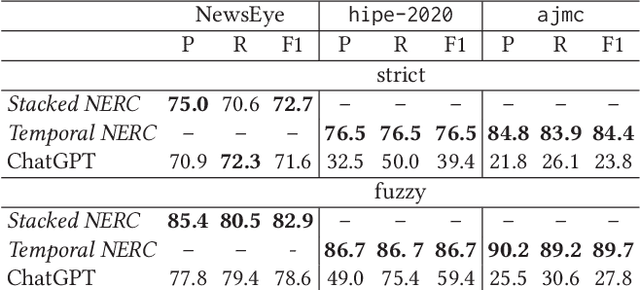
Large language models (LLMs) have been leveraged for several years now, obtaining state-of-the-art performance in recognizing entities from modern documents. For the last few months, the conversational agent ChatGPT has "prompted" a lot of interest in the scientific community and public due to its capacity of generating plausible-sounding answers. In this paper, we explore this ability by probing it in the named entity recognition and classification (NERC) task in primary sources (e.g., historical newspapers and classical commentaries) in a zero-shot manner and by comparing it with state-of-the-art LM-based systems. Our findings indicate several shortcomings in identifying entities in historical text that range from the consistency of entity annotation guidelines, entity complexity, and code-switching, to the specificity of prompting. Moreover, as expected, the inaccessibility of historical archives to the public (and thus on the Internet) also impacts its performance.
Extending Text Informativeness Measures to Passage Interestingness Evaluation (Language Model vs. Word Embedding)
Apr 14, 2020
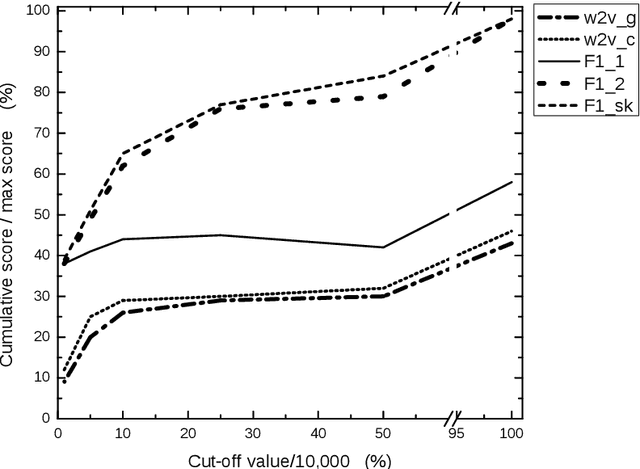

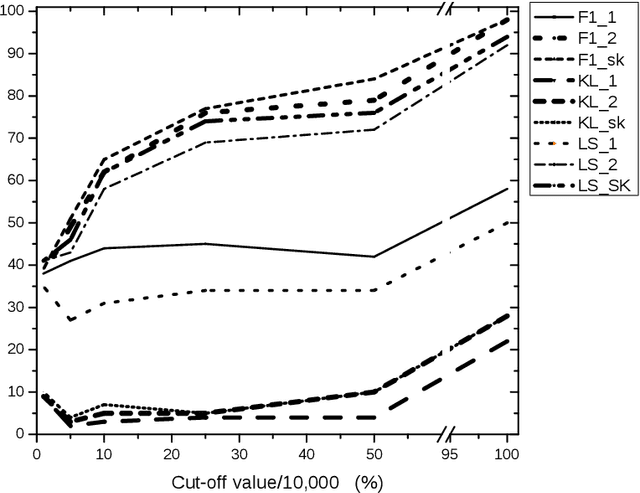
Standard informativeness measures used to evaluate Automatic Text Summarization mostly rely on n-gram overlapping between the automatic summary and the reference summaries. These measures differ from the metric they use (cosine, ROUGE, Kullback-Leibler, Logarithm Similarity, etc.) and the bag of terms they consider (single words, word n-grams, entities, nuggets, etc.). Recent word embedding approaches offer a continuous alternative to discrete approaches based on the presence/absence of a text unit. Informativeness measures have been extended to Focus Information Retrieval evaluation involving a user's information need represented by short queries. In particular for the task of CLEF-INEX Tweet Contextualization, tweet contents have been considered as queries. In this paper we define the concept of Interestingness as a generalization of Informativeness, whereby the information need is diverse and formalized as an unknown set of implicit queries. We then study the ability of state of the art Informativeness measures to cope with this generalization. Lately we show that with this new framework, standard word embeddings outperforms discrete measures only on uni-grams, however bi-grams seems to be a key point of interestingness evaluation. Lastly we prove that the CLEF-INEX Tweet Contextualization 2012 Logarithm Similarity measure provides best results.
Audio Summarization with Audio Features and Probability Distribution Divergence
Jan 20, 2020
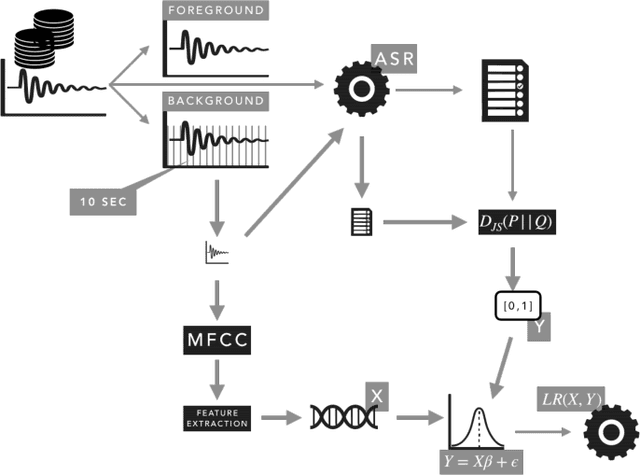
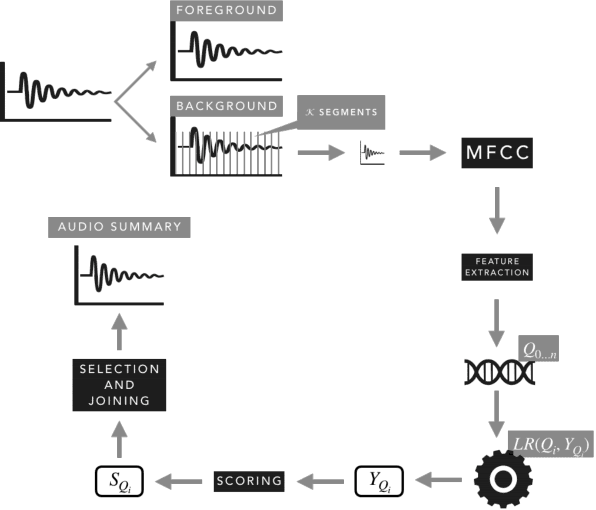

The automatic summarization of multimedia sources is an important task that facilitates the understanding of an individual by condensing the source while maintaining relevant information. In this paper we focus on audio summarization based on audio features and the probability of distribution divergence. Our method, based on an extractive summarization approach, aims to select the most relevant segments until a time threshold is reached. It takes into account the segment's length, position and informativeness value. Informativeness of each segment is obtained by mapping a set of audio features issued from its Mel-frequency Cepstral Coefficients and their corresponding Jensen-Shannon divergence score. Results over a multi-evaluator scheme shows that our approach provides understandable and informative summaries.
Étude de l'informativité des transcriptions : une approche basée sur le résumé automatique
Sep 04, 2018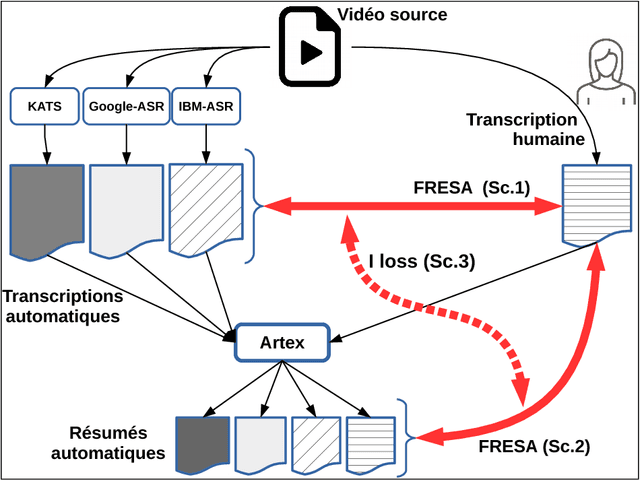
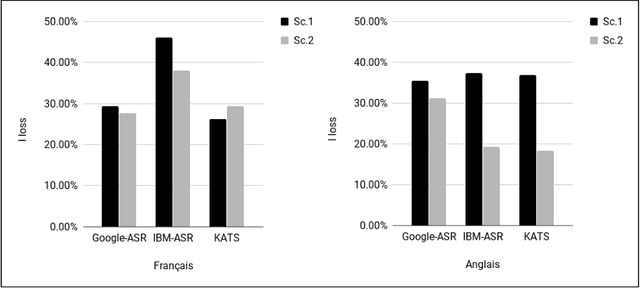
In this paper we propose a new approach to evaluate the informativeness of transcriptions coming from Automatic Speech Recognition systems. This approach, based in the notion of informativeness, is focused on the framework of Automatic Text Summarization performed over these transcriptions. At a first glance we estimate the informative content of the various automatic transcriptions, then we explore the capacity of Automatic Text Summarization to overcome the informative loss. To do this we use an automatic summary evaluation protocol without reference (based on the informative content), which computes the divergence between probability distributions of different textual representations: manual and automatic transcriptions and their summaries. After a set of evaluations this analysis allowed us to judge both the quality of the transcriptions in terms of informativeness and to assess the ability of automatic text summarization to compensate the problems raised during the transcription phase.
WiSeBE: Window-based Sentence Boundary Evaluation
Aug 27, 2018
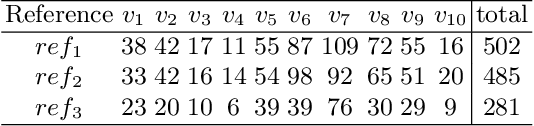

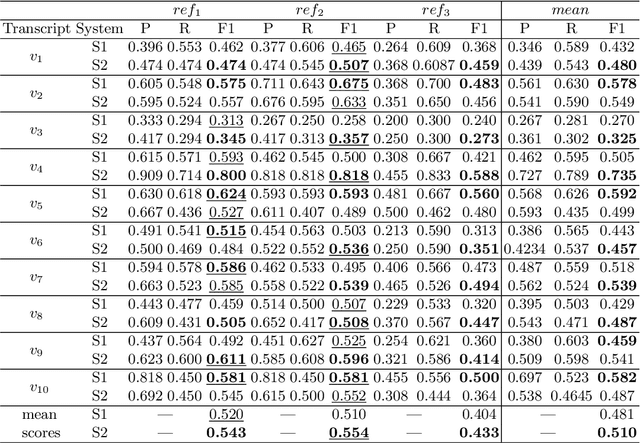
Sentence Boundary Detection (SBD) has been a major research topic since Automatic Speech Recognition transcripts have been used for further Natural Language Processing tasks like Part of Speech Tagging, Question Answering or Automatic Summarization. But what about evaluation? Do standard evaluation metrics like precision, recall, F-score or classification error; and more important, evaluating an automatic system against a unique reference is enough to conclude how well a SBD system is performing given the final application of the transcript? In this paper we propose Window-based Sentence Boundary Evaluation (WiSeBE), a semi-supervised metric for evaluating Sentence Boundary Detection systems based on multi-reference (dis)agreement. We evaluate and compare the performance of different SBD systems over a set of Youtube transcripts using WiSeBE and standard metrics. This double evaluation gives an understanding of how WiSeBE is a more reliable metric for the SBD task.