 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmented Relevance Datasets with Fine-Tuned Small LLMs
Apr 14, 2025Building high-quality datasets and labeling query-document relevance are essential yet resource-intensive tasks, requiring detailed guidelines and substantial effort from human annotators. This paper explores the use of small, fine-tuned large language models (LLMs) to automate relevance assessment, with a focus on improving ranking models' performance by augmenting their training dataset. We fine-tuned small LLMs to enhance relevance assessments, thereby improving dataset creation quality for downstream ranking model training. Our experiments demonstrate that these fine-tuned small LLMs not only outperform certain closed source models on our dataset but also lead to substantial improvements in ranking model performance. These results highlight the potential of leveraging small LLMs for efficient and scalable dataset augmentation, providing a practical solution for search engine optimization.
* 10 pages, 3 figures, and 6 tables. Accepted and presented to LLM4EVAL at WSDM '25
LongEval-Retrieval: French-English Dynamic Test Collection for Continuous Web Search Evaluation
Mar 06, 2023


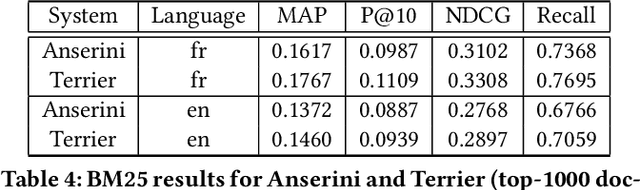
LongEval-Retrieval is a Web document retrieval benchmark that focuses on continuous retrieval evaluation. This test collection is intended to be used to study the temporal persistence of Information Retrieval systems and will be used as the test collection in the Longitudinal Evaluation of Model Performance Track (LongEval) at CLEF 2023. This benchmark simulates an evolving information system environment - such as the one a Web search engine operates in - where the document collection, the query distribution, and relevance all move continuously, while following the Cranfield paradigm for offline evaluation. To do that, we introduce the concept of a dynamic test collection that is composed of successive sub-collections each representing the state of an information system at a given time step. In LongEval-Retrieval, each sub-collection contains a set of queries, documents, and soft relevance assessments built from click models. The data comes from Qwant, a privacy-preserving Web search engine that primarily focuses on the French market. LongEval-Retrieval also provides a 'mirror' collection: it is initially constructed in the French language to benefit from the majority of Qwant's traffic, before being translated to English. This paper presents the creation process of LongEval-Retrieval and provides baseline runs and analysis.
Audio Summarization with Audio Features and Probability Distribution Divergence
Jan 20, 2020
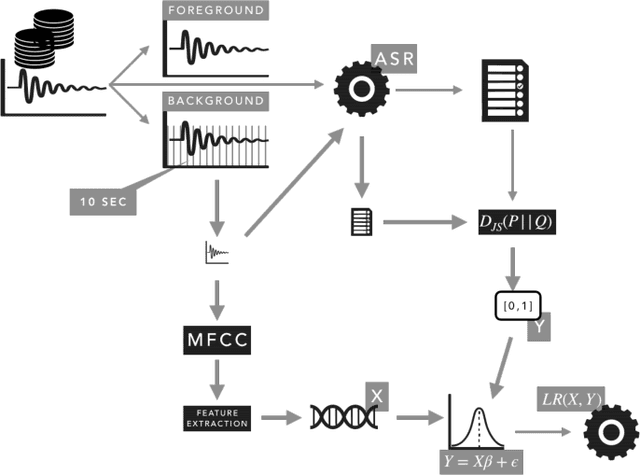
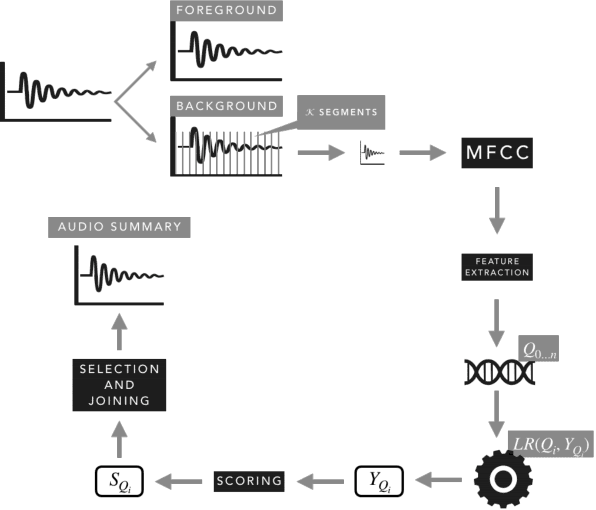

The automatic summarization of multimedia sources is an important task that facilitates the understanding of an individual by condensing the source while maintaining relevant information. In this paper we focus on audio summarization based on audio features and the probability of distribution divergence. Our method, based on an extractive summarization approach, aims to select the most relevant segments until a time threshold is reached. It takes into account the segment's length, position and informativeness value. Informativeness of each segment is obtained by mapping a set of audio features issued from its Mel-frequency Cepstral Coefficients and their corresponding Jensen-Shannon divergence score. Results over a multi-evaluator scheme shows that our approach provides understandable and informative summaries.