 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters to an LLM? Behavioral and Computational Evidences from Summarization
Jan 31, 2026Large Language Models (LLMs) are now state-of-the-art at summarization, yet the internal notion of importance that drives their information selections remains hidden. We propose to investigate this by combining behavioral and computational analyses. Behaviorally, we generate a series of length-controlled summaries for each document and derive empirical importance distributions based on how often each information unit is selected. These reveal that LLMs converge on consistent importance patterns, sharply different from pre-LLM baselines, and that LLMs cluster more by family than by size. Computationally, we identify that certain attention heads align well with empirical importance distributions, and that middle-to-late layers are strongly predictive of importance. Together, these results provide initial insights into what LLMs prioritize in summarization and how this priority is internally represented, opening a path toward interpreting and ultimately controlling information selection in these models.
LongEval at CLEF 2025: Longitudinal Evaluation of IR Model Performance
Mar 11, 2025
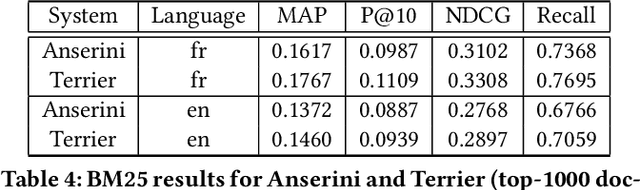
This paper presents the third edition of the LongEval Lab, part of the CLEF 2025 conference, which continues to explore the challenges of temporal persistence in Information Retrieval (IR). The lab features two tasks designed to provide researchers with test data that reflect the evolving nature of user queries and document relevance over time. By evaluating how model performance degrades as test data diverge temporally from training data, LongEval seeks to advance the understanding of temporal dynamics in IR systems. The 2025 edition aims to engage the IR and NLP communities in addressing the development of adaptive models that can maintain retrieval quality over time in the domains of web search and scientific retrieval.
LongEval-Retrieval: French-English Dynamic Test Collection for Continuous Web Search Evaluation
Mar 06, 2023


LongEval-Retrieval is a Web document retrieval benchmark that focuses on continuous retrieval evaluation. This test collection is intended to be used to study the temporal persistence of Information Retrieval systems and will be used as the test collection in the Longitudinal Evaluation of Model Performance Track (LongEval) at CLEF 2023. This benchmark simulates an evolving information system environment - such as the one a Web search engine operates in - where the document collection, the query distribution, and relevance all move continuously, while following the Cranfield paradigm for offline evaluation. To do that, we introduce the concept of a dynamic test collection that is composed of successive sub-collections each representing the state of an information system at a given time step. In LongEval-Retrieval, each sub-collection contains a set of queries, documents, and soft relevance assessments built from click models. The data comes from Qwant, a privacy-preserving Web search engine that primarily focuses on the French market. LongEval-Retrieval also provides a 'mirror' collection: it is initially constructed in the French language to benefit from the majority of Qwant's traffic, before being translated to English. This paper presents the creation process of LongEval-Retrieval and provides baseline runs and analysis.
Toward Word Embedding for Personalized Information Retrieval
Jun 22, 2016
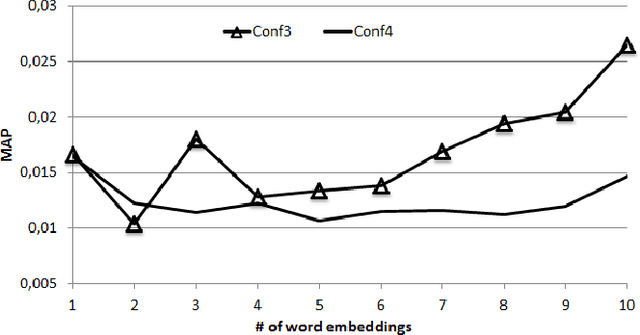

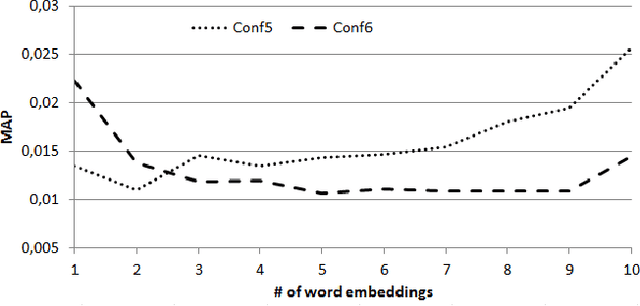
This paper presents preliminary works on using Word Embedding (word2vec) for query expansion in the context of Personalized Information Retrieval. Traditionally, word embeddings are learned on a general corpus, like Wikipedia. In this work we try to personalize the word embeddings learning, by achieving the learning on the user's profile. The word embeddings are then in the same context than the user interests. Our proposal is evaluated on the CLEF Social Book Search 2016 collection. The results obtained show that some efforts should be made in the way to apply Word Embedding in the context of Personalized Information Retrieval.