 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongEval at CLEF 2025: Longitudinal Evaluation of IR Model Performance
Mar 11, 2025
This paper presents the third edition of the LongEval Lab, part of the CLEF 2025 conference, which continues to explore the challenges of temporal persistence in Information Retrieval (IR). The lab features two tasks designed to provide researchers with test data that reflect the evolving nature of user queries and document relevance over time. By evaluating how model performance degrades as test data diverge temporally from training data, LongEval seeks to advance the understanding of temporal dynamics in IR systems. The 2025 edition aims to engage the IR and NLP communities in addressing the development of adaptive models that can maintain retrieval quality over time in the domains of web search and scientific retrieval.
A Reproducibility and Generalizability Study of Large Language Models for Query Generation
Nov 22, 2024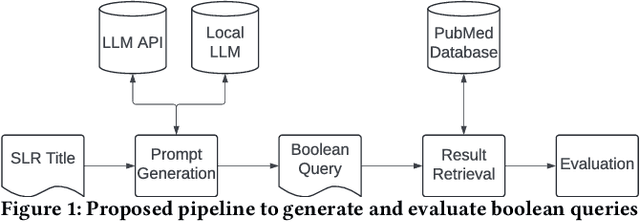
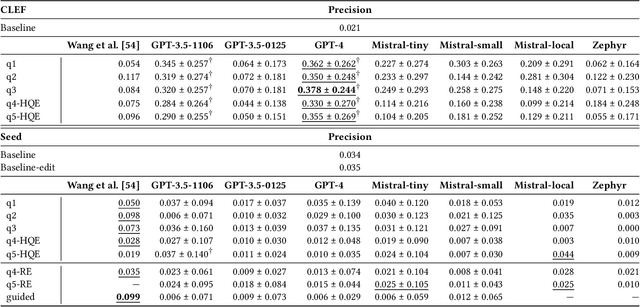

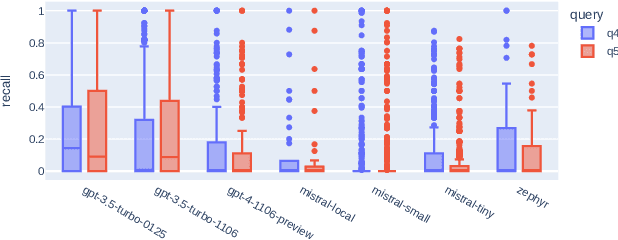
Systematic literature reviews (SLRs) are a cornerstone of academic research, yet they are often labour-intensive and time-consuming due to the detailed literature curation process. The advent of generative AI and large language models (LLMs) promises to revolutionize this process by assisting researchers in several tedious tasks, one of them being the generation of effective Boolean queries that will select the publications to consider including in a review. This paper presents an extensive study of Boolean query generation using LLMs for systematic reviews, reproducing and extending the work of Wang et al. and Alaniz et al. Our study investigates the replicability and reliability of results achieved using ChatGPT and compares its performance with open-source alternatives like Mistral and Zephyr to provide a more comprehensive analysis of LLMs for query generation. Therefore, we implemented a pipeline, which automatically creates a Boolean query for a given review topic by using a previously defined LLM, retrieves all documents for this query from the PubMed database and then evaluates the results. With this pipeline we first assess whether the results obtained using ChatGPT for query generation are reproducible and consistent. We then generalize our results by analyzing and evaluating open-source models and evaluating their efficacy in generating Boolean queries. Finally, we conduct a failure analysis to identify and discuss the limitations and shortcomings of using LLMs for Boolean query generation. This examination helps to understand the gaps and potential areas for improvement in the application of LLMs to information retrieval tasks. Our findings highlight the strengths, limitations, and potential of LLMs in the domain of information retrieval and literature review automation.
Reproducible Hybrid Time-Travel Retrieval in Evolving Corpora
Nov 06, 2024
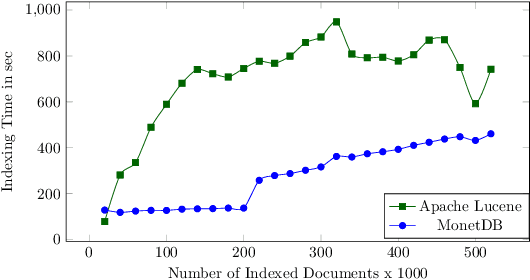
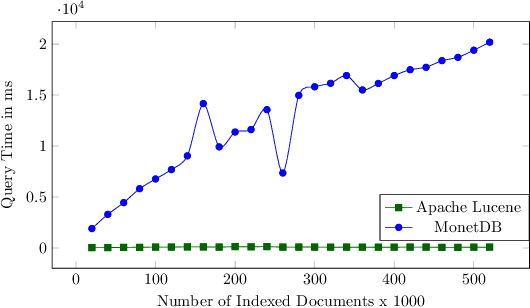
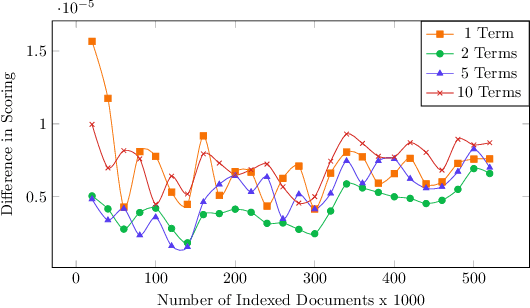
There are settings in which reproducibility of ranked lists is desirable, such as when extracting a subset of an evolving document corpus for downstream research tasks or in domains such as patent retrieval or in medical systematic reviews, with high reproducibility expectations. However, as global term statistics change when documents change or are added to a corpus, queries using typical ranked retrieval models are not even reproducible for the parts of the document corpus that have not changed. Thus, Boolean retrieval frequently remains the mechanism of choice in such settings. We present a hybrid retrieval system combining Lucene for fast retrieval with a column-store-based retrieval system maintaining a versioned and time-stamped index. The latter component allows re-execution of previously posed queries resulting in the same ranked list and further allows for time-travel queries over evolving collection, as web archives, while maintaining the original ranking. Thus, retrieval results in evolving document collections are fully reproducible even when document collections and thus term statistics change.
LongEval-Retrieval: French-English Dynamic Test Collection for Continuous Web Search Evaluation
Mar 06, 2023


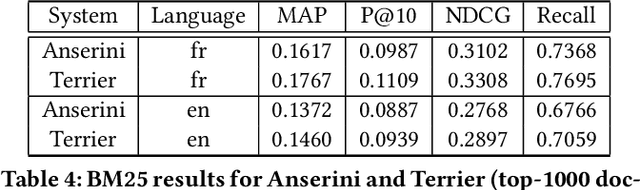
LongEval-Retrieval is a Web document retrieval benchmark that focuses on continuous retrieval evaluation. This test collection is intended to be used to study the temporal persistence of Information Retrieval systems and will be used as the test collection in the Longitudinal Evaluation of Model Performance Track (LongEval) at CLEF 2023. This benchmark simulates an evolving information system environment - such as the one a Web search engine operates in - where the document collection, the query distribution, and relevance all move continuously, while following the Cranfield paradigm for offline evaluation. To do that, we introduce the concept of a dynamic test collection that is composed of successive sub-collections each representing the state of an information system at a given time step. In LongEval-Retrieval, each sub-collection contains a set of queries, documents, and soft relevance assessments built from click models. The data comes from Qwant, a privacy-preserving Web search engine that primarily focuses on the French market. LongEval-Retrieval also provides a 'mirror' collection: it is initially constructed in the French language to benefit from the majority of Qwant's traffic, before being translated to English. This paper presents the creation process of LongEval-Retrieval and provides baseline runs and analysis.
Towards More Accountable Search Engines: Online Evaluation of Representation Bias
Oct 17, 2021
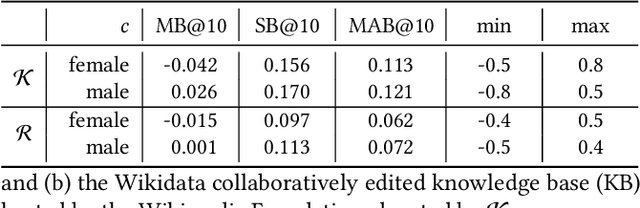
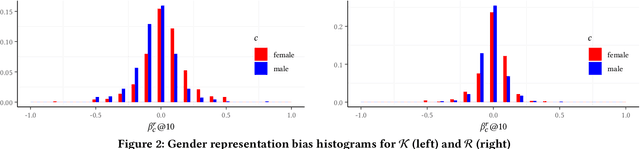
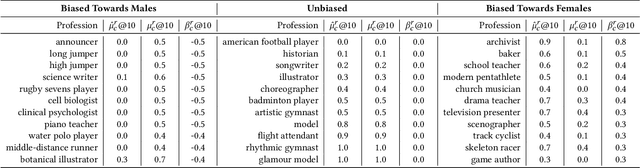
Information availability affects people's behavior and perception of the world. Notably, people rely on search engines to satisfy their need for information. Search engines deliver results relevant to user requests usually without being or making themselves accountable for the information they deliver, which may harm people's lives and, in turn, society. This potential risk urges the development of evaluation mechanisms of bias in order to empower the user in judging the results of search engines. In this paper, we give a possible solution to measuring representation bias with respect to societal features for search engines and apply it to evaluating the gender representation bias for Google's Knowledge Graph Carousel for listing occupations.