 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation Extraction or Pattern Matching? Unravelling the Generalisation Limits of Language Models for Biographical RE
May 18, 2025Analysing the generalisation capabilities of relation extraction (RE) models is crucial for assessing whether they learn robust relational patterns or rely on spurious correlations. Our cross-dataset experiments find that RE models struggle with unseen data, even within similar domains. Notably, higher intra-dataset performance does not indicate better transferability, instead often signaling overfitting to dataset-specific artefacts. Our results also show that data quality, rather than lexical similarity, is key to robust transfer, and the choice of optimal adaptation strategy depends on the quality of data available: while fine-tuning yields the best cross-dataset performance with high-quality data, few-shot in-context learning (ICL) is more effective with noisier data. However, even in these cases, zero-shot baselines occasionally outperform all cross-dataset results. Structural issues in RE benchmarks, such as single-relation per sample constraints and non-standardised negative class definitions, further hinder model transferability.
A Reproducibility and Generalizability Study of Large Language Models for Query Generation
Nov 22, 2024
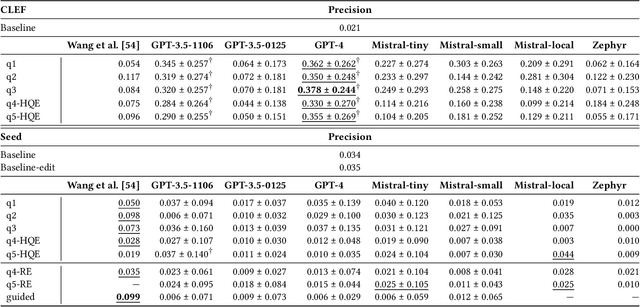

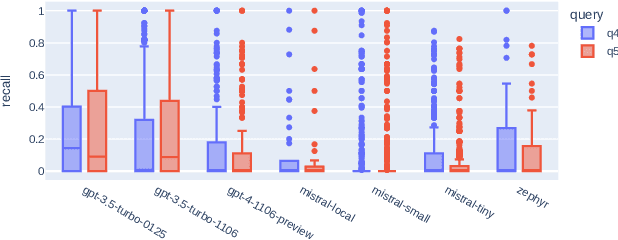
Systematic literature reviews (SLRs) are a cornerstone of academic research, yet they are often labour-intensive and time-consuming due to the detailed literature curation process. The advent of generative AI and large language models (LLMs) promises to revolutionize this process by assisting researchers in several tedious tasks, one of them being the generation of effective Boolean queries that will select the publications to consider including in a review. This paper presents an extensive study of Boolean query generation using LLMs for systematic reviews, reproducing and extending the work of Wang et al. and Alaniz et al. Our study investigates the replicability and reliability of results achieved using ChatGPT and compares its performance with open-source alternatives like Mistral and Zephyr to provide a more comprehensive analysis of LLMs for query generation. Therefore, we implemented a pipeline, which automatically creates a Boolean query for a given review topic by using a previously defined LLM, retrieves all documents for this query from the PubMed database and then evaluates the results. With this pipeline we first assess whether the results obtained using ChatGPT for query generation are reproducible and consistent. We then generalize our results by analyzing and evaluating open-source models and evaluating their efficacy in generating Boolean queries. Finally, we conduct a failure analysis to identify and discuss the limitations and shortcomings of using LLMs for Boolean query generation. This examination helps to understand the gaps and potential areas for improvement in the application of LLMs to information retrieval tasks. Our findings highlight the strengths, limitations, and potential of LLMs in the domain of information retrieval and literature review automation.
Beyond the Numbers: Transparency in Relation Extraction Benchmark Creation and Leaderboards
Nov 07, 2024This paper investigates the transparency in the creation of benchmarks and the use of leaderboards for measuring progress in NLP, with a focus on the relation extraction (RE) task. Existing RE benchmarks often suffer from insufficient documentation, lacking crucial details such as data sources, inter-annotator agreement, the algorithms used for the selection of instances for datasets, and information on potential biases like dataset imbalance. Progress in RE is frequently measured by leaderboards that rank systems based on evaluation methods, typically limited to aggregate metrics like F1-score. However, the absence of detailed performance analysis beyond these metrics can obscure the true generalisation capabilities of models. Our analysis reveals that widely used RE benchmarks, such as TACRED and NYT, tend to be highly imbalanced and contain noisy labels. Moreover, the lack of class-based performance metrics fails to accurately reflect model performance across datasets with a large number of relation types. These limitations should be carefully considered when reporting progress in RE. While our discussion centers on the transparency of RE benchmarks and leaderboards, the observations we discuss are broadly applicable to other NLP tasks as well. Rather than undermining the significance and value of existing RE benchmarks and the development of new models, this paper advocates for improved documentation and more rigorous evaluation to advance the field.
AustroTox: A Dataset for Target-Based Austrian German Offensive Language Detection
Jun 12, 2024



Model interpretability in toxicity detection greatly profits from token-level annotations. However, currently such annotations are only available in English. We introduce a dataset annotated for offensive language detection sourced from a news forum, notable for its incorporation of the Austrian German dialect, comprising 4,562 user comments. In addition to binary offensiveness classification, we identify spans within each comment constituting vulgar language or representing targets of offensive statements. We evaluate fine-tuned language models as well as large language models in a zero- and few-shot fashion. The results indicate that while fine-tuned models excel in detecting linguistic peculiarities such as vulgar dialect, large language models demonstrate superior performance in detecting offensiveness in AustroTox. We publish the data and code.
CSMeD: Bridging the Dataset Gap in Automated Citation Screening for Systematic Literature Reviews
Nov 21, 2023



Systematic literature reviews (SLRs) play an essential role in summarising, synthesising and validating scientific evidence. In recent years, there has been a growing interest in using machine learning techniques to automate the identification of relevant studies for SLRs. However, the lack of standardised evaluation datasets makes comparing the performance of such automated literature screening systems difficult. In this paper, we analyse the citation screening evaluation datasets, revealing that many of the available datasets are either too small, suffer from data leakage or have limited applicability to systems treating automated literature screening as a classification task, as opposed to, for example, a retrieval or question-answering task. To address these challenges, we introduce CSMeD, a meta-dataset consolidating nine publicly released collections, providing unified access to 325 SLRs from the fields of medicine and computer science. CSMeD serves as a comprehensive resource for training and evaluating the performance of automated citation screening models. Additionally, we introduce CSMeD-FT, a new dataset designed explicitly for evaluating the full text publication screening task. To demonstrate the utility of CSMeD, we conduct experiments and establish baselines on new datasets.
Annotating Data for Fine-Tuning a Neural Ranker? Current Active Learning Strategies are not Better than Random Selection
Sep 12, 2023Search methods based on Pretrained Language Models (PLM) have demonstrated great effectiveness gains compared to statistical and early neural ranking models. However, fine-tuning PLM-based rankers requires a great amount of annotated training data. Annotating data involves a large manual effort and thus is expensive, especially in domain specific tasks. In this paper we investigate fine-tuning PLM-based rankers under limited training data and budget. We investigate two scenarios: fine-tuning a ranker from scratch, and domain adaptation starting with a ranker already fine-tuned on general data, and continuing fine-tuning on a target dataset. We observe a great variability in effectiveness when fine-tuning on different randomly selected subsets of training data. This suggests that it is possible to achieve effectiveness gains by actively selecting a subset of the training data that has the most positive effect on the rankers. This way, it would be possible to fine-tune effective PLM rankers at a reduced annotation budget. To investigate this, we adapt existing Active Learning (AL) strategies to the task of fine-tuning PLM rankers and investigate their effectiveness, also considering annotation and computational costs. Our extensive analysis shows that AL strategies do not significantly outperform random selection of training subsets in terms of effectiveness. We further find that gains provided by AL strategies come at the expense of more assessments (thus higher annotation costs) and AL strategies underperform random selection when comparing effectiveness given a fixed annotation cost. Our results highlight that ``optimal'' subsets of training data that provide high effectiveness at low annotation cost do exist, but current mainstream AL strategies applied to PLM rankers are not capable of identifying them.
CRUISE-Screening: Living Literature Reviews Toolbox
Sep 04, 2023


Keeping up with research and finding related work is still a time-consuming task for academics. Researchers sift through thousands of studies to identify a few relevant ones. Automation techniques can help by increasing the efficiency and effectiveness of this task. To this end, we developed CRUISE-Screening, a web-based application for conducting living literature reviews - a type of literature review that is continuously updated to reflect the latest research in a particular field. CRUISE-Screening is connected to several search engines via an API, which allows for updating the search results periodically. Moreover, it can facilitate the process of screening for relevant publications by using text classification and question answering models. CRUISE-Screening can be used both by researchers conducting literature reviews and by those working on automating the citation screening process to validate their algorithms. The application is open-source: https://github.com/ProjectDoSSIER/cruise-screening, and a demo is available under this URL: https://citation-screening.ec.tuwien.ac.at. We discuss the limitations of our tool in Appendix A.
Effective Matching of Patients to Clinical Trials using Entity Extraction and Neural Re-ranking
Jul 01, 2023



Clinical trials (CTs) often fail due to inadequate patient recruitment. This paper tackles the challenges of CT retrieval by presenting an approach that addresses the patient-to-trials paradigm. Our approach involves two key components in a pipeline-based model: (i) a data enrichment technique for enhancing both queries and documents during the first retrieval stage, and (ii) a novel re-ranking schema that uses a Transformer network in a setup adapted to this task by leveraging the structure of the CT documents. We use named entity recognition and negation detection in both patient description and the eligibility section of CTs. We further classify patient descriptions and CT eligibility criteria into current, past, and family medical conditions. This extracted information is used to boost the importance of disease and drug mentions in both query and index for lexical retrieval. Furthermore, we propose a two-step training schema for the Transformer network used to re-rank the results from the lexical retrieval. The first step focuses on matching patient information with the descriptive sections of trials, while the second step aims to determine eligibility by matching patient information with the criteria section. Our findings indicate that the inclusion criteria section of the CT has a great influence on the relevance score in lexical models, and that the enrichment techniques for queries and documents improve the retrieval of relevant trials. The re-ranking strategy, based on our training schema, consistently enhances CT retrieval and shows improved performance by 15\% in terms of precision at retrieving eligible trials. The results of our experiments suggest the benefit of making use of extracted entities. Moreover, our proposed re-ranking schema shows promising effectiveness compared to larger neural models, even with limited training data.
Outcome-based Evaluation of Systematic Review Automation
Jun 30, 2023

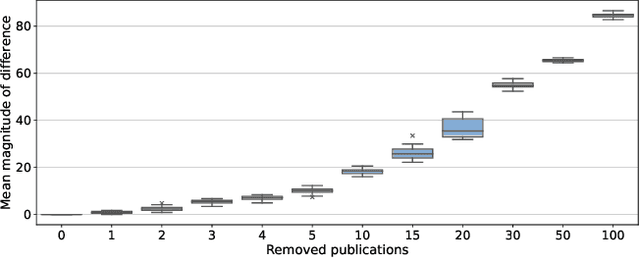

Current methods of evaluating search strategies and automated citation screening for systematic literature reviews typically rely on counting the number of relevant and not relevant publications. This established practice, however, does not accurately reflect the reality of conducting a systematic review, because not all included publications have the same influence on the final outcome of the systematic review. More specifically, if an important publication gets excluded or included, this might significantly change the overall review outcome, while not including or excluding less influential studies may only have a limited impact. However, in terms of evaluation measures, all inclusion and exclusion decisions are treated equally and, therefore, failing to retrieve publications with little to no impact on the review outcome leads to the same decrease in recall as failing to retrieve crucial publications. We propose a new evaluation framework that takes into account the impact of the reported study on the overall systematic review outcome. We demonstrate the framework by extracting review meta-analysis data and estimating outcome effects using predictions from ranking runs on systematic reviews of interventions from CLEF TAR 2019 shared task. We further measure how closely the obtained outcomes are to the outcomes of the original review if the arbitrary rankings were used. We evaluate 74 runs using the proposed framework and compare the results with those obtained using standard IR measures. We find that accounting for the difference in review outcomes leads to a different assessment of the quality of a system than if traditional evaluation measures were used. Our analysis provides new insights into the evaluation of retrieval results in the context of systematic review automation, emphasising the importance of assessing the usefulness of each document beyond binary relevance.
Statute-enhanced lexical retrieval of court cases for COLIEE 2022
Apr 17, 2023


We discuss our experiments for COLIEE Task 1, a court case retrieval competition using cases from the Federal Court of Canada. During experiments on the training data we observe that passage level retrieval with rank fusion outperforms document level retrieval. By explicitly adding extracted statute information to the queries and documents we can further improve the results. We submit two passage level runs to the competition, which achieve high recall but low precision.