 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatute-enhanced lexical retrieval of court cases for COLIEE 2022
Apr 17, 2023


We discuss our experiments for COLIEE Task 1, a court case retrieval competition using cases from the Federal Court of Canada. During experiments on the training data we observe that passage level retrieval with rank fusion outperforms document level retrieval. By explicitly adding extracted statute information to the queries and documents we can further improve the results. We submit two passage level runs to the competition, which achieve high recall but low precision.
The Gutenberg Dialogue Dataset
Apr 27, 2020

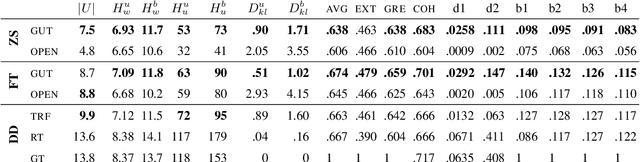
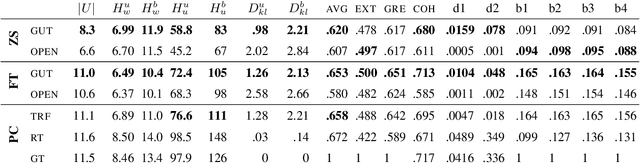
Large datasets are essential for many NLP tasks. Current publicly available open-domain dialogue datasets offer a trade-off between size and quality (e.g. DailyDialog vs. Opensubtitles). We aim to close this gap by building a high-quality dataset consisting of 14.8M utterances in English. We extract and process dialogues from publicly available online books. We present a detailed description of our pipeline and heuristics and an error analysis of extracted dialogues. Better response quality can be achieved in zero-shot and finetuning settings by training on our data than on the larger but much noisier Opensubtitles dataset. Researchers can easily build their versions of the dataset by adjusting various trade-off parameters. The code can be extended to further languages with limited effort (https://github.com/ricsinaruto/gutenberg-dialog).
Improving Neural Conversational Models with Entropy-Based Data Filtering
Jun 04, 2019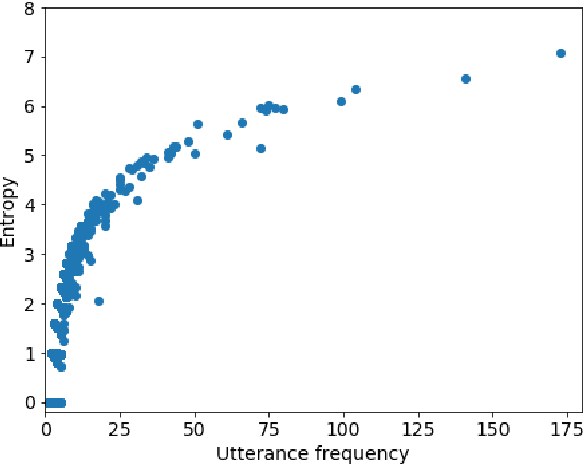

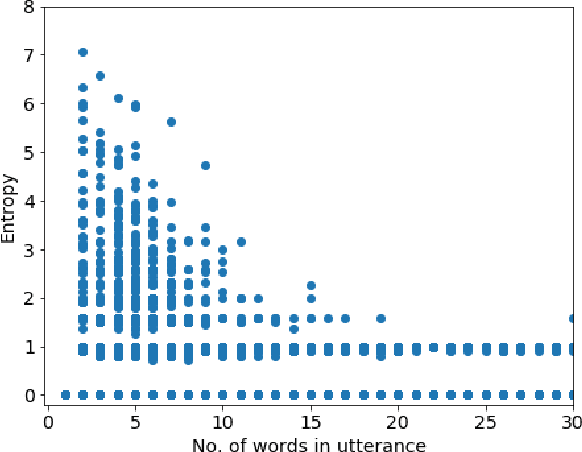
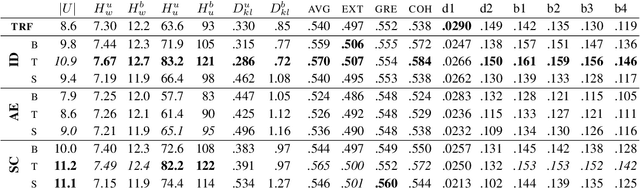
Current neural network-based conversational models lack diversity and generate boring responses to open-ended utterances. Priors such as persona, emotion, or topic provide additional information to dialog models to aid response generation, but annotating a dataset with priors is expensive and such annotations are rarely available. While previous methods for improving the quality of open-domain response generation focused on either the underlying model or the training objective, we present a method of filtering dialog datasets by removing generic utterances from training data using a simple entropy-based approach that does not require human supervision. We conduct extensive experiments with different variations of our method, and compare dialog models across 17 evaluation metrics to show that training on datasets filtered this way results in better conversational quality as chatbots learn to output more diverse responses.