 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Agency Program: Curiosity, compression, and communication in agents
Feb 27, 2026This paper presents the Artificial Agency Program (AAP), a position and research agenda for building AI systems as reality embedded, resource-bounded agents whose development is driven by curiosity-as-learning-progress under physical and computational constraints. The central thesis is that AI is most useful when treated as part of an extended human--tool system that increases sensing, understanding, and actuation capability while reducing friction at the interface between people, tools, and environments. The agenda unifies predictive compression, intrinsic motivation, empowerment and control, interface quality (unification), and language/self-communication as selective information bottlenecks. We formulate these ideas as a falsifiable program with explicit costs, staged experiments, and a concrete multimodal tokenized testbed in which an agent allocates limited budget among observation, action, and deliberation. The aim is to provide a conceptual and experimental framework that connects intrinsic motivation, information theory, thermodynamics, bounded rationality, and modern reasoning systems
Scaling Next-Brain-Token Prediction for MEG
Jan 29, 2026We present a large autoregressive model for source-space MEG that scales next-token prediction to long context across datasets and scanners: handling a corpus of over 500 hours and thousands of sessions across the three largest MEG datasets. A modified SEANet-style vector-quantizer reduces multichannel MEG into a flattened token stream on which we train a Qwen2.5-VL backbone from scratch to predict the next brain token and to recursively generate minutes of MEG from up to a minute of context. To evaluate long-horizon generation, we introduce task-matched tests: (i) on-manifold stability via generated-only drift compared to the time-resolved distribution of real sliding windows, and (ii) conditional specificity via correct context versus prompt-swap controls using a neurophysiologically grounded metric set. We train on CamCAN and Omega and run all analyses on held-out MOUS, establishing cross-dataset generalization. Across metrics, generations remain relatively stable over long rollouts and are closer to the correct continuation than swapped controls. Code available at: https://github.com/ricsinaruto/brain-gen.
Foundational GPT Model for MEG
Apr 14, 2024



Deep learning techniques can be used to first training unsupervised models on large amounts of unlabelled data, before fine-tuning the models on specific tasks. This approach has seen massive success for various kinds of data, e.g. images, language, audio, and holds the promise of improving performance in various downstream tasks (e.g. encoding or decoding brain data). However, there has been limited progress taking this approach for modelling brain signals, such as Magneto-/electroencephalography (M/EEG). Here we propose two classes of deep learning foundational models that can be trained using forecasting of unlabelled MEG. First, we consider a modified Wavenet; and second, we consider a modified Transformer-based (GPT2) model. The modified GPT2 includes a novel application of tokenisation and embedding methods, allowing a model developed initially for the discrete domain of language to be applied to continuous multichannel time series data. We also extend the forecasting framework to include condition labels as inputs, enabling better modelling (encoding) of task data. We compare the performance of these deep learning models with standard linear autoregressive (AR) modelling on MEG data. This shows that GPT2-based models provide better modelling capabilities than Wavenet and linear AR models, by better reproducing the temporal, spatial and spectral characteristics of real data and evoked activity in task data. We show how the GPT2 model scales well to multiple subjects, while adapting its model to each subject through subject embedding. Finally, we show how such a model can be useful in downstream decoding tasks through data simulation. All code is available on GitHub (https://github.com/ricsinaruto/MEG-transfer-decoding).
Generalizing Brain Decoding Across Subjects with Deep Learning
May 27, 2022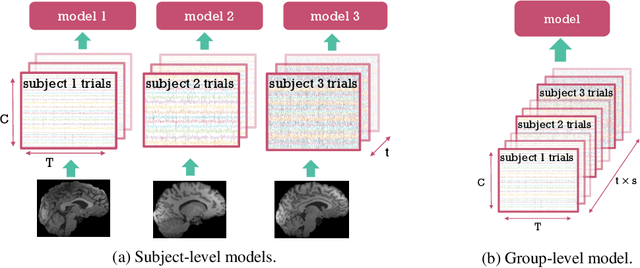

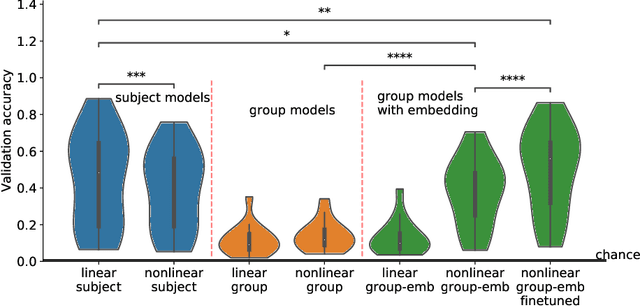
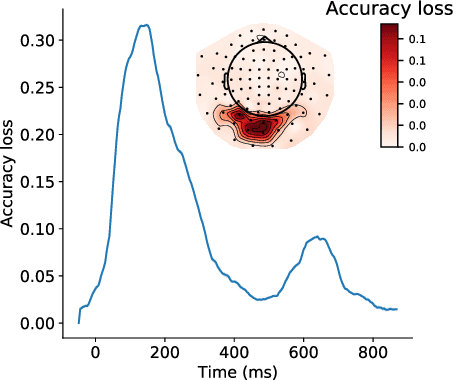
Decoding experimental variables from brain imaging data is gaining popularity, with applications in brain-computer interfaces and the study of neural representations. Decoding is typically subject-specific and does not generalise well over subjects. Here, we investigate ways to achieve cross-subject decoding. We used magnetoencephalography (MEG) data where 15 subjects viewed 118 different images, with 30 examples per image. Training on the entire 1s window following the presentation of each image, we experimented with an adaptation of the WaveNet architecture for classification. We also investigated the use of subject embedding to aid learning of subject variability in the group model. We show that deep learning and subject embedding are crucial to closing the performance gap between subject and group-level models. Importantly group models outperform subject models when tested on an unseen subject with little available data. The potential of such group modelling is even higher with bigger datasets. Furthermore, we demonstrate the use of permutation feature importance to gain insight into the spatio-temporal and spectral information encoded in the models, enabling better physiological interpretation. All experimental code is available at https://github.com/ricsinaruto/MEG-group-decode.
The Gutenberg Dialogue Dataset
Apr 27, 2020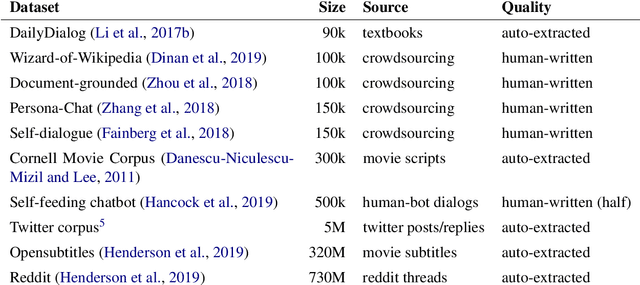

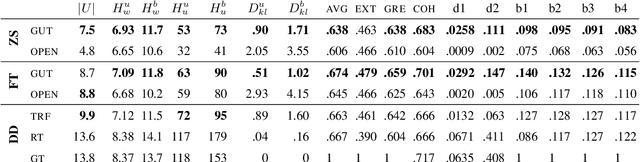
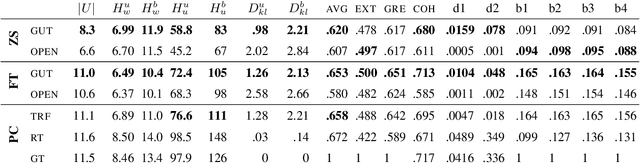
Large datasets are essential for many NLP tasks. Current publicly available open-domain dialogue datasets offer a trade-off between size and quality (e.g. DailyDialog vs. Opensubtitles). We aim to close this gap by building a high-quality dataset consisting of 14.8M utterances in English. We extract and process dialogues from publicly available online books. We present a detailed description of our pipeline and heuristics and an error analysis of extracted dialogues. Better response quality can be achieved in zero-shot and finetuning settings by training on our data than on the larger but much noisier Opensubtitles dataset. Researchers can easily build their versions of the dataset by adjusting various trade-off parameters. The code can be extended to further languages with limited effort (https://github.com/ricsinaruto/gutenberg-dialog).
Proposal Towards a Personalized Knowledge-powered Self-play Based Ensemble Dialog System
Sep 11, 2019
This is the application document for the 2019 Amazon Alexa competition. We give an overall vision of our conversational experience, as well as a sample conversation that we would like our dialog system to achieve by the end of the competition. We believe personalization, knowledge, and self-play are important components towards better chatbots. These are further highlighted by our detailed system architecture proposal and novelty section. Finally, we describe how we would ensure an engaging experience, how this research would impact the field, and related work.
Deep Learning Based Chatbot Models
Aug 23, 2019

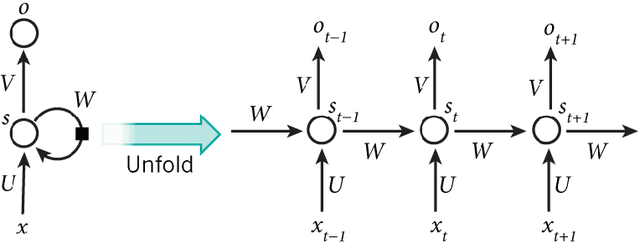

A conversational agent (chatbot) is a piece of software that is able to communicate with humans using natural language. Modeling conversation is an important task in natural language processing and artificial intelligence. While chatbots can be used for various tasks, in general they have to understand users' utterances and provide responses that are relevant to the problem at hand. In my work, I conduct an in-depth survey of recent literature, examining over 70 publications related to chatbots published in the last 3 years. Then, I proceed to make the argument that the very nature of the general conversation domain demands approaches that are different from current state-of-of-the-art architectures. Based on several examples from the literature I show why current chatbot models fail to take into account enough priors when generating responses and how this affects the quality of the conversation. In the case of chatbots, these priors can be outside sources of information that the conversation is conditioned on like the persona or mood of the conversers. In addition to presenting the reasons behind this problem, I propose several ideas on how it could be remedied. The next section focuses on adapting the very recent Transformer model to the chatbot domain, which is currently state-of-the-art in neural machine translation. I first present experiments with the vanilla model, using conversations extracted from the Cornell Movie-Dialog Corpus. Secondly, I augment the model with some of my ideas regarding the issues of encoder-decoder architectures. More specifically, I feed additional features into the model like mood or persona together with the raw conversation data. Finally, I conduct a detailed analysis of how the vanilla model performs on conversational data by comparing it to previous chatbot models and how the additional features affect the quality of the generated responses.
Improving Neural Conversational Models with Entropy-Based Data Filtering
Jun 04, 2019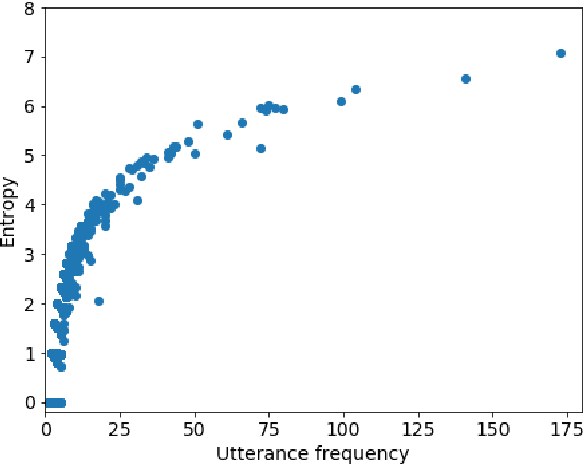

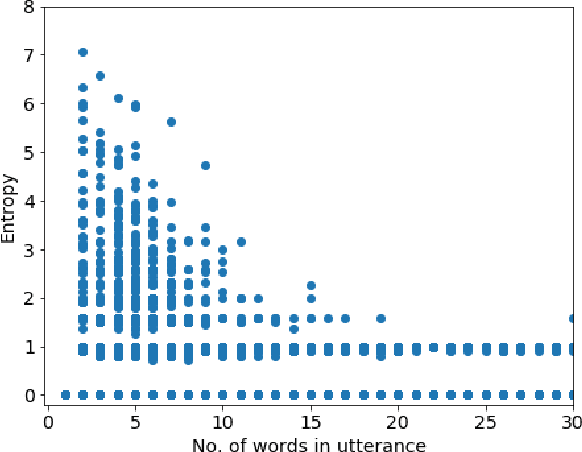
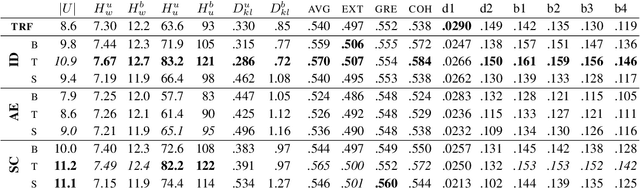
Current neural network-based conversational models lack diversity and generate boring responses to open-ended utterances. Priors such as persona, emotion, or topic provide additional information to dialog models to aid response generation, but annotating a dataset with priors is expensive and such annotations are rarely available. While previous methods for improving the quality of open-domain response generation focused on either the underlying model or the training objective, we present a method of filtering dialog datasets by removing generic utterances from training data using a simple entropy-based approach that does not require human supervision. We conduct extensive experiments with different variations of our method, and compare dialog models across 17 evaluation metrics to show that training on datasets filtered this way results in better conversational quality as chatbots learn to output more diverse responses.