 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Based Chatbot Models
Paper and Code

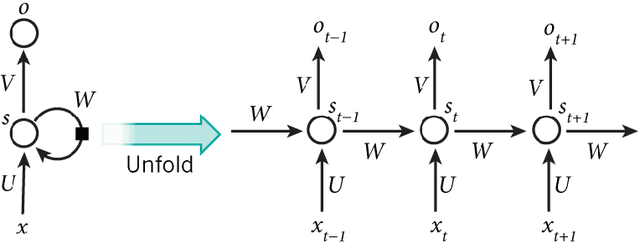

A conversational agent (chatbot) is a piece of software that is able to communicate with humans using natural language. Modeling conversation is an important task in natural language processing and artificial intelligence. While chatbots can be used for various tasks, in general they have to understand users' utterances and provide responses that are relevant to the problem at hand. In my work, I conduct an in-depth survey of recent literature, examining over 70 publications related to chatbots published in the last 3 years. Then, I proceed to make the argument that the very nature of the general conversation domain demands approaches that are different from current state-of-of-the-art architectures. Based on several examples from the literature I show why current chatbot models fail to take into account enough priors when generating responses and how this affects the quality of the conversation. In the case of chatbots, these priors can be outside sources of information that the conversation is conditioned on like the persona or mood of the conversers. In addition to presenting the reasons behind this problem, I propose several ideas on how it could be remedied. The next section focuses on adapting the very recent Transformer model to the chatbot domain, which is currently state-of-the-art in neural machine translation. I first present experiments with the vanilla model, using conversations extracted from the Cornell Movie-Dialog Corpus. Secondly, I augment the model with some of my ideas regarding the issues of encoder-decoder architectures. More specifically, I feed additional features into the model like mood or persona together with the raw conversation data. Finally, I conduct a detailed analysis of how the vanilla model performs on conversational data by comparing it to previous chatbot models and how the additional features affect the quality of the generated responses.