 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEG-XL: Data-Efficient Brain-to-Text via Long-Context Pre-Training
Feb 02, 2026Clinical brain-to-text interfaces are designed for paralysed patients who cannot provide extensive training recordings. Pre-training improves data-efficient generalisation by learning statistical priors across subjects, but these priors critically depend on context. While natural speech might unfold gradually over minutes, most methods pre-train with only a few seconds of context. Thus, we propose MEG-XL, a model pre-trained with 2.5 minutes of MEG context per sample, 5-300x longer than prior work, and equivalent to 191k tokens, capturing extended neural context. Fine-tuning on the task of word decoding from brain data, MEG-XL matches supervised performance with a fraction of the data (e.g. 1hr vs 50hrs) and outperforms brain foundation models. We find that models pre-trained with longer contexts learn representations that transfer better to word decoding. Our results indicate that long-context pre-training helps exploit extended neural context that other methods unnecessarily discard. Code, model weights, and instructions are available at https://github.com/neural-processing-lab/MEG-XL .
MEGnifying Emotion: Sentiment Analysis from Annotated Brain Data
Jan 26, 2026Decoding emotion from brain activity could unlock a deeper understanding of the human experience. While a number of existing datasets align brain data with speech and with speech transcripts, no datasets have annotated brain data with sentiment. To bridge this gap, we explore the use of pre-trained Text-to-Sentiment models to annotate non invasive brain recordings, acquired using magnetoencephalography (MEG), while participants listened to audiobooks. Having annotated the text, we employ force-alignment of the text and audio to align our sentiment labels with the brain recordings. It is straightforward then to train Brainto-Sentiment models on these data. Experimental results show an improvement in balanced accuracy for Brain-to-Sentiment compared to baseline, supporting the proposed approach as a proof-of-concept for leveraging existing MEG datasets and learning to decode sentiment directly from the brain.
The 2025 PNPL Competition: Speech Detection and Phoneme Classification in the LibriBrain Dataset
Jun 11, 2025The advance of speech decoding from non-invasive brain data holds the potential for profound societal impact. Among its most promising applications is the restoration of communication to paralysed individuals affected by speech deficits such as dysarthria, without the need for high-risk surgical interventions. The ultimate aim of the 2025 PNPL competition is to produce the conditions for an "ImageNet moment" or breakthrough in non-invasive neural decoding, by harnessing the collective power of the machine learning community. To facilitate this vision we present the largest within-subject MEG dataset recorded to date (LibriBrain) together with a user-friendly Python library (pnpl) for easy data access and integration with deep learning frameworks. For the competition we define two foundational tasks (i.e. Speech Detection and Phoneme Classification from brain data), complete with standardised data splits and evaluation metrics, illustrative benchmark models, online tutorial code, a community discussion board, and public leaderboard for submissions. To promote accessibility and participation the competition features a Standard track that emphasises algorithmic innovation, as well as an Extended track that is expected to reward larger-scale computing, accelerating progress toward a non-invasive brain-computer interface for speech.
Unlocking Non-Invasive Brain-to-Text
May 19, 2025Despite major advances in surgical brain-to-text (B2T), i.e. transcribing speech from invasive brain recordings, non-invasive alternatives have yet to surpass even chance on standard metrics. This remains a barrier to building a non-invasive brain-computer interface (BCI) capable of restoring communication in paralysed individuals without surgery. Here, we present the first non-invasive B2T result that significantly exceeds these critical baselines, raising BLEU by $1.4\mathrm{-}2.6\times$ over prior work. This result is driven by three contributions: (1) we extend recent word-classification models with LLM-based rescoring, transforming single-word predictors into closed-vocabulary B2T systems; (2) we introduce a predictive in-filling approach to handle out-of-vocabulary (OOV) words, substantially expanding the effective vocabulary; and (3) we demonstrate, for the first time, how to scale non-invasive B2T models across datasets, unlocking deep learning at scale and improving accuracy by $2.1\mathrm{-}2.3\times$. Through these contributions, we offer new insights into the roles of data quality and vocabulary size. Together, our results remove a major obstacle to realising practical non-invasive B2T systems.
NeuGPT: Unified multi-modal Neural GPT
Oct 28, 2024This paper introduces NeuGPT, a groundbreaking multi-modal language generation model designed to harmonize the fragmented landscape of neural recording research. Traditionally, studies in the field have been compartmentalized by signal type, with EEG, MEG, ECoG, SEEG, fMRI, and fNIRS data being analyzed in isolation. Recognizing the untapped potential for cross-pollination and the adaptability of neural signals across varying experimental conditions, we set out to develop a unified model capable of interfacing with multiple modalities. Drawing inspiration from the success of pre-trained large models in NLP, computer vision, and speech processing, NeuGPT is architected to process a diverse array of neural recordings and interact with speech and text data. Our model mainly focus on brain-to-text decoding, improving SOTA from 6.94 to 12.92 on BLEU-1 and 6.93 to 13.06 on ROUGE-1F. It can also simulate brain signals, thereby serving as a novel neural interface. Code is available at \href{https://github.com/NeuSpeech/NeuGPT}{NeuSpeech/NeuGPT (https://github.com/NeuSpeech/NeuGPT) .}
Resolving Domain Shift For Representations Of Speech In Non-Invasive Brain Recordings
Oct 25, 2024
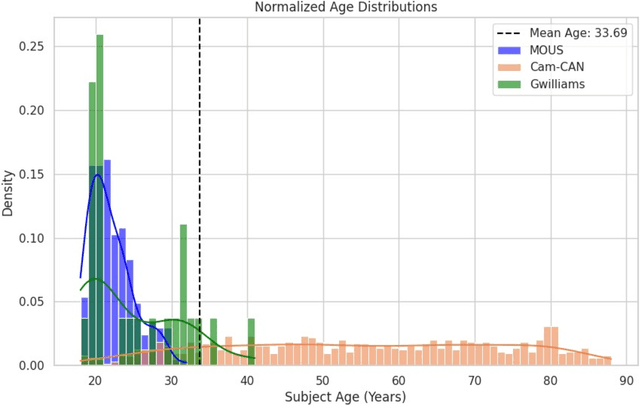
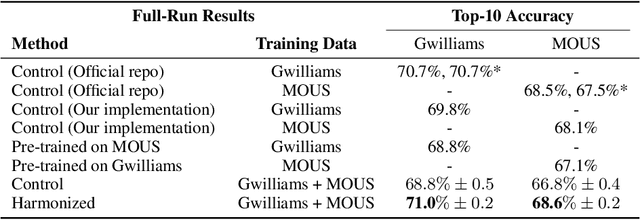
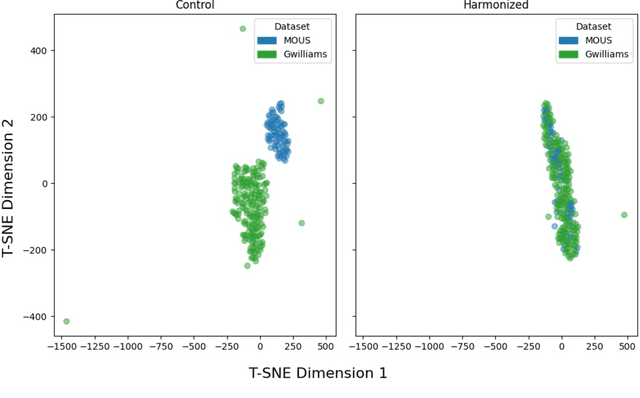
Machine learning techniques have enabled researchers to leverage neuroimaging data to decode speech from brain activity, with some amazing recent successes achieved by applications built using invasive devices. However, research requiring surgical implants has a number of practical limitations. Non-invasive neuroimaging techniques provide an alternative but come with their own set of challenges, the limited scale of individual studies being among them. Without the ability to pool the recordings from different non-invasive studies, data on the order of magnitude needed to leverage deep learning techniques to their full potential remains out of reach. In this work, we focus on non-invasive data collected using magnetoencephalography (MEG). We leverage two different, leading speech decoding models to investigate how an adversarial domain adaptation framework augments their ability to generalize across datasets. We successfully improve the performance of both models when training across multiple datasets. To the best of our knowledge, this study is the first ever application of feature-level, deep learning based harmonization for MEG neuroimaging data. Our analysis additionally offers further evidence of the impact of demographic features on neuroimaging data, demonstrating that participant age strongly affects how machine learning models solve speech decoding tasks using MEG data. Lastly, in the course of this study we produce a new open-source implementation of one of these models to the benefit of the broader scientific community.
The Brain's Bitter Lesson: Scaling Speech Decoding With Self-Supervised Learning
Jun 06, 2024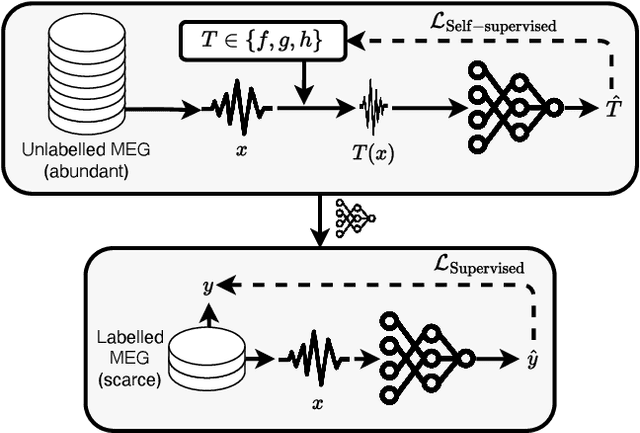
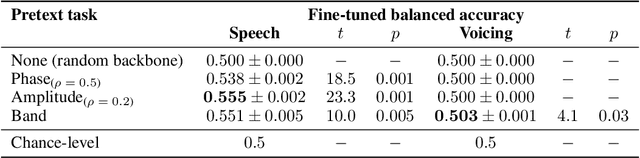
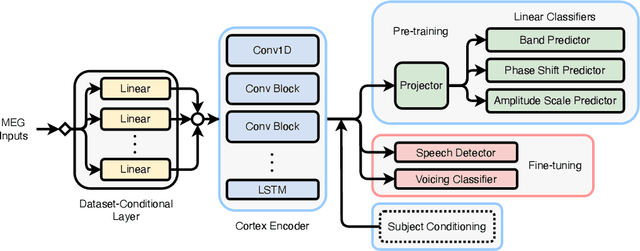
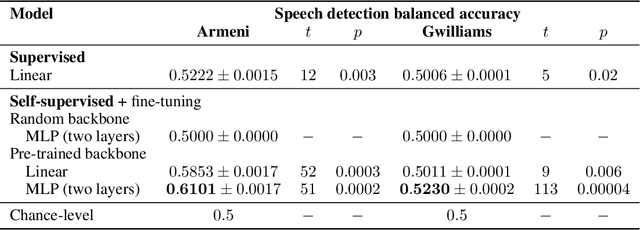
The past few years have produced a series of spectacular advances in the decoding of speech from brain activity. The engine of these advances has been the acquisition of labelled data, with increasingly large datasets acquired from single subjects. However, participants exhibit anatomical and other individual differences, and datasets use varied scanners and task designs. As a result, prior work has struggled to leverage data from multiple subjects, multiple datasets, multiple tasks, and unlabelled datasets. In turn, the field has not benefited from the rapidly growing number of open neural data repositories to exploit large-scale data and deep learning. To address this, we develop an initial set of neuroscience-inspired self-supervised objectives, together with a neural architecture, for representation learning from heterogeneous and unlabelled neural recordings. Experimental results show that representations learned with these objectives generalise across subjects, datasets, and tasks, and are also learned faster than using only labelled data. In addition, we set new benchmarks for two foundational speech decoding tasks. Taken together, these methods now unlock the potential for training speech decoding models with orders of magnitude more existing data.
Foundational GPT Model for MEG
Apr 14, 2024



Deep learning techniques can be used to first training unsupervised models on large amounts of unlabelled data, before fine-tuning the models on specific tasks. This approach has seen massive success for various kinds of data, e.g. images, language, audio, and holds the promise of improving performance in various downstream tasks (e.g. encoding or decoding brain data). However, there has been limited progress taking this approach for modelling brain signals, such as Magneto-/electroencephalography (M/EEG). Here we propose two classes of deep learning foundational models that can be trained using forecasting of unlabelled MEG. First, we consider a modified Wavenet; and second, we consider a modified Transformer-based (GPT2) model. The modified GPT2 includes a novel application of tokenisation and embedding methods, allowing a model developed initially for the discrete domain of language to be applied to continuous multichannel time series data. We also extend the forecasting framework to include condition labels as inputs, enabling better modelling (encoding) of task data. We compare the performance of these deep learning models with standard linear autoregressive (AR) modelling on MEG data. This shows that GPT2-based models provide better modelling capabilities than Wavenet and linear AR models, by better reproducing the temporal, spatial and spectral characteristics of real data and evoked activity in task data. We show how the GPT2 model scales well to multiple subjects, while adapting its model to each subject through subject embedding. Finally, we show how such a model can be useful in downstream decoding tasks through data simulation. All code is available on GitHub (https://github.com/ricsinaruto/MEG-transfer-decoding).
Mai Ho'omāuna i ka 'Ai: Language Models Improve Automatic Speech Recognition in Hawaiian
Apr 03, 2024In this paper we address the challenge of improving Automatic Speech Recognition (ASR) for a low-resource language, Hawaiian, by incorporating large amounts of independent text data into an ASR foundation model, Whisper. To do this, we train an external language model (LM) on ~1.5M words of Hawaiian text. We then use the LM to rescore Whisper and compute word error rates (WERs) on a manually curated test set of labeled Hawaiian data. As a baseline, we use Whisper without an external LM. Experimental results reveal a small but significant improvement in WER when ASR outputs are rescored with a Hawaiian LM. The results support leveraging all available data in the development of ASR systems for underrepresented languages.
DreamUp3D: Object-Centric Generative Models for Single-View 3D Scene Understanding and Real-to-Sim Transfer
Feb 26, 2024
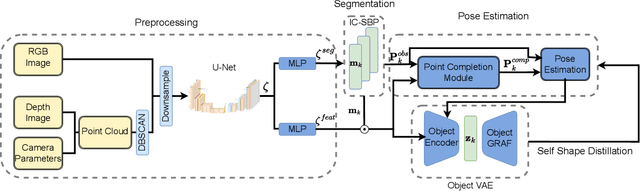

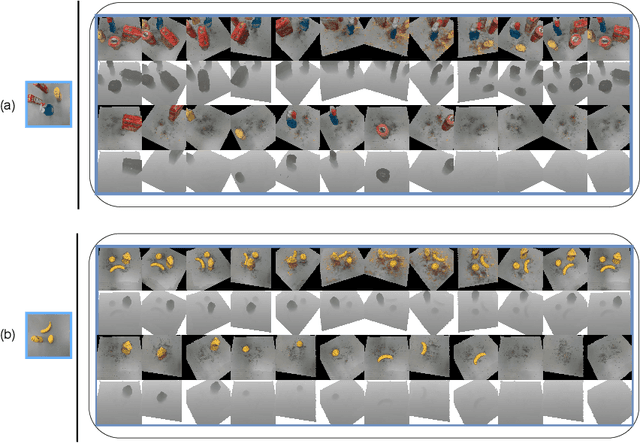
3D scene understanding for robotic applications exhibits a unique set of requirements including real-time inference, object-centric latent representation learning, accurate 6D pose estimation and 3D reconstruction of objects. Current methods for scene understanding typically rely on a combination of trained models paired with either an explicit or learnt volumetric representation, all of which have their own drawbacks and limitations. We introduce DreamUp3D, a novel Object-Centric Generative Model (OCGM) designed explicitly to perform inference on a 3D scene informed only by a single RGB-D image. DreamUp3D is a self-supervised model, trained end-to-end, and is capable of segmenting objects, providing 3D object reconstructions, generating object-centric latent representations and accurate per-object 6D pose estimates. We compare DreamUp3D to baselines including NeRFs, pre-trained CLIP-features, ObSurf, and ObPose, in a range of tasks including 3D scene reconstruction, object matching and object pose estimation. Our experiments show that our model outperforms all baselines by a significant margin in real-world scenarios displaying its applicability for 3D scene understanding tasks while meeting the strict demands exhibited in robotics applications.