 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXQCfD: Accelerating Fast Actor-Critic Algorithms with Prior Data and Prior Policies
May 11, 2026For reinforcement learning in the real world online exploration is expensive A common practice in robotic reinforcement learning is to incorporate additional data to improve sample efficiency Expert demonstration data is often crucial for solving hard exploration tasks with sparse rewards While prior data is used to augment experience and pretrain models we show that the design of existing algorithms fails to achieve the sample efficiency that is possible in this setting due to a failure to use pretrained policies effectively We propose XQCfD which extends the sample-efficient XQC actor-critic to learn from demonstrations using augmented replay buffers pretrained policies and stationary policy architectures designed to avoid rapidly unlearning the strong initial policy like prior works We show our stationary network architecture enables policy improvement out-of-distribution better than standard network architectures due to its higher entropy predictions XQCfD achieves state of the art performance across a range of complex manipulation tasks with sparse rewards from the popular Adroit Robomimic and MimicGen benchmarks -- notably with a low update-to-data ratio and no ensemble networks
Sim-to-Real Transfer for Muscle-Actuated Robots via Generalized Actuator Networks
Apr 10, 2026Tendon drives paired with soft muscle actuation enable faster and safer robots while potentially accelerating skill acquisition. Still, these systems are rarely used in practice due to inherent nonlinearities, friction, and hysteresis, which complicate modeling and control. So far, these challenges have hindered policy transfer from simulation to real systems. To bridge this gap, we propose a sim-to-real pipeline that learns a neural network model of this complex actuation and leverages established rigid body simulation for the arm dynamics and interactions with the environment. Our method, called Generalized Actuator Network (GeAN), enables actuation model identification across a wide range of robots by learning directly from joint position trajectories rather than requiring torque sensors. Using GeAN on PAMY2, a tendon-driven robot powered by pneumatic artificial muscles, we successfully deploy precise goal-reaching and dynamic ball-in-a-cup policies trained entirely in simulation. To the best of our knowledge, this result constitutes the first successful sim-to-real transfer for a four-degrees-of-freedom muscle-actuated robot arm.
Disentangling Dynamical Systems: Causal Representation Learning Meets Local Sparse Attention
Mar 15, 2026Parametric system identification methods estimate the parameters of explicitly defined physical systems from data. Yet, they remain constrained by the need to provide an explicit function space, typically through a predefined library of candidate functions chosen via available domain knowledge. In contrast, deep learning can demonstrably model systems of broad complexity with high fidelity, but black-box function approximation typically fails to yield explicit descriptive or disentangled representations revealing the structure of a system. We develop a novel identifiability theorem, leveraging causal representation learning, to uncover disentangled representations of system parameters without structural assumptions. We derive a graphical criterion specifying when system parameters can be uniquely disentangled from raw trajectory data, up to permutation and diffeomorphism. Crucially, our analysis demonstrates that global causal structures provide a lower bound on the disentanglement guarantees achievable when considering local state-dependent causal structures. We instantiate system parameter identification as a variational inference problem, leveraging a sparsity-regularised transformer to uncover state-dependent causal structures. We empirically validate our approach across four synthetic domains, demonstrating its ability to recover highly disentangled representations that baselines fail to recover. Corroborating our theoretical analysis, our results confirm that enforcing local causal structure is often necessary for full identifiability.
Posterior Sampling Reinforcement Learning with Gaussian Processes for Continuous Control: Sublinear Regret Bounds for Unbounded State Spaces
Mar 09, 2026We analyze the Bayesian regret of the Gaussian process posterior sampling reinforcement learning (GP-PSRL) algorithm. Posterior sampling is an effective heuristic for decision-making under uncertainty that has been used to develop successful algorithms for a variety of continuous control problems. However, theoretical work on GP-PSRL is limited. All known regret bounds either fail to achieve a tight dependence on a kernel-dependent quantity called the maximum information gain or fail to properly account for the fact that the set of possible system states is unbounded. Through a recursive application of the Borell-Tsirelson-Ibragimov-Sudakov inequality, we show that, with high probability, the states actually visited by the algorithm are contained within a ball of near-constant radius. To obtain tight dependence on the maximum information gain, we use the chaining method to control the regret suffered by GP-PSRL. Our main result is a Bayesian regret bound of the order $\widetilde{\mathcal{O}}(H^{3/2}\sqrt{γ_{T/H} T})$, where $H$ is the horizon, $T$ is the number of time steps and $γ_{T/H}$ is the maximum information gain. With this result, we resolve the limitations with prior theoretical work on PSRL, and provide the theoretical foundation and tools for analyzing PSRL in complex settings.
Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications
Oct 08, 2025Amid growing efforts to leverage advances in large language models (LLMs) and vision-language models (VLMs) for robotics, Vision-Language-Action (VLA) models have recently gained significant attention. By unifying vision, language, and action data at scale, which have traditionally been studied separately, VLA models aim to learn policies that generalise across diverse tasks, objects, embodiments, and environments. This generalisation capability is expected to enable robots to solve novel downstream tasks with minimal or no additional task-specific data, facilitating more flexible and scalable real-world deployment. Unlike previous surveys that focus narrowly on action representations or high-level model architectures, this work offers a comprehensive, full-stack review, integrating both software and hardware components of VLA systems. In particular, this paper provides a systematic review of VLAs, covering their strategy and architectural transition, architectures and building blocks, modality-specific processing techniques, and learning paradigms. In addition, to support the deployment of VLAs in real-world robotic applications, we also review commonly used robot platforms, data collection strategies, publicly available datasets, data augmentation methods, and evaluation benchmarks. Throughout this comprehensive survey, this paper aims to offer practical guidance for the robotics community in applying VLAs to real-world robotic systems. All references categorized by training approach, evaluation method, modality, and dataset are available in the table on our project website: https://vla-survey.github.io .
Building Gradient by Gradient: Decentralised Energy Functions for Bimanual Robot Assembly
Oct 06, 2025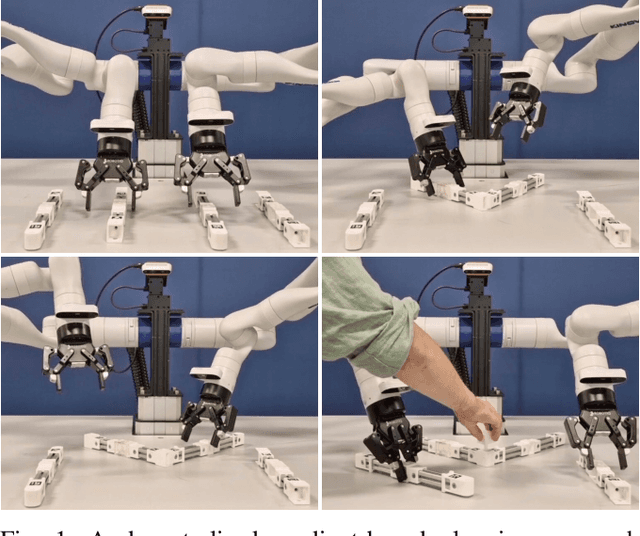



There are many challenges in bimanual assembly, including high-level sequencing, multi-robot coordination, and low-level, contact-rich operations such as component mating. Task and motion planning (TAMP) methods, while effective in this domain, may be prohibitively slow to converge when adapting to disturbances that require new task sequencing and optimisation. These events are common during tight-tolerance assembly, where difficult-to-model dynamics such as friction or deformation require rapid replanning and reattempts. Moreover, defining explicit task sequences for assembly can be cumbersome, limiting flexibility when task replanning is required. To simplify this planning, we introduce a decentralised gradient-based framework that uses a piecewise continuous energy function through the automatic composition of adaptive potential functions. This approach generates sub-goals using only myopic optimisation, rather than long-horizon planning. It demonstrates effectiveness at solving long-horizon tasks due to the structure and adaptivity of the energy function. We show that our approach scales to physical bimanual assembly tasks for constructing tight-tolerance assemblies. In these experiments, we discover that our gradient-based rapid replanning framework generates automatic retries, coordinated motions and autonomous handovers in an emergent fashion.
Is Single-View Mesh Reconstruction Ready for Robotics?
May 23, 2025



This paper evaluates single-view mesh reconstruction models for creating digital twin environments in robot manipulation. Recent advances in computer vision for 3D reconstruction from single viewpoints present a potential breakthrough for efficiently creating virtual replicas of physical environments for robotics contexts. However, their suitability for physics simulations and robotics applications remains unexplored. We establish benchmarking criteria for 3D reconstruction in robotics contexts, including handling typical inputs, producing collision-free and stable reconstructions, managing occlusions, and meeting computational constraints. Our empirical evaluation using realistic robotics datasets shows that despite success on computer vision benchmarks, existing approaches fail to meet robotics-specific requirements. We quantitively examine limitations of single-view reconstruction for practical robotics implementation, in contrast to prior work that focuses on multi-view approaches. Our findings highlight critical gaps between computer vision advances and robotics needs, guiding future research at this intersection.
Task and Joint Space Dual-Arm Compliant Control
Apr 29, 2025Robots that interact with humans or perform delicate manipulation tasks must exhibit compliance. However, most commercial manipulators are rigid and suffer from significant friction, limiting end-effector tracking accuracy in torque-controlled modes. To address this, we present a real-time, open-source impedance controller that smoothly interpolates between joint-space and task-space compliance. This hybrid approach ensures safe interaction and precise task execution, such as sub-centimetre pin insertions. We deploy our controller on Frank, a dual-arm platform with two Kinova Gen3 arms, and compensate for modelled friction dynamics using a model-free observer. The system is real-time capable and integrates with standard ROS tools like MoveIt!. It also supports high-frequency trajectory streaming, enabling closed-loop execution of trajectories generated by learning-based methods, optimal control, or teleoperation. Our results demonstrate robust tracking and compliant behaviour even under high-friction conditions. The complete system is available open-source at https://github.com/applied-ai-lab/compliant_controllers.
LUMOS: Language-Conditioned Imitation Learning with World Models
Mar 13, 2025We introduce LUMOS, a language-conditioned multi-task imitation learning framework for robotics. LUMOS learns skills by practicing them over many long-horizon rollouts in the latent space of a learned world model and transfers these skills zero-shot to a real robot. By learning on-policy in the latent space of the learned world model, our algorithm mitigates policy-induced distribution shift which most offline imitation learning methods suffer from. LUMOS learns from unstructured play data with fewer than 1% hindsight language annotations but is steerable with language commands at test time. We achieve this coherent long-horizon performance by combining latent planning with both image- and language-based hindsight goal relabeling during training, and by optimizing an intrinsic reward defined in the latent space of the world model over multiple time steps, effectively reducing covariate shift. In experiments on the difficult long-horizon CALVIN benchmark, LUMOS outperforms prior learning-based methods with comparable approaches on chained multi-task evaluations. To the best of our knowledge, we are the first to learn a language-conditioned continuous visuomotor control for a real-world robot within an offline world model. Videos, dataset and code are available at http://lumos.cs.uni-freiburg.de.
COMBO-Grasp: Learning Constraint-Based Manipulation for Bimanual Occluded Grasping
Feb 12, 2025

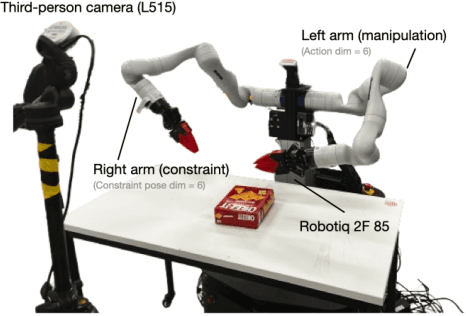
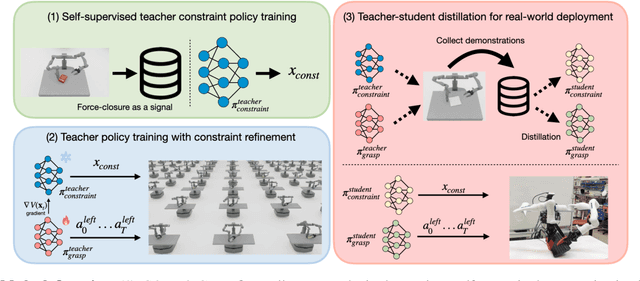
This paper addresses the challenge of occluded robot grasping, i.e. grasping in situations where the desired grasp poses are kinematically infeasible due to environmental constraints such as surface collisions. Traditional robot manipulation approaches struggle with the complexity of non-prehensile or bimanual strategies commonly used by humans in these circumstances. State-of-the-art reinforcement learning (RL) methods are unsuitable due to the inherent complexity of the task. In contrast, learning from demonstration requires collecting a significant number of expert demonstrations, which is often infeasible. Instead, inspired by human bimanual manipulation strategies, where two hands coordinate to stabilise and reorient objects, we focus on a bimanual robotic setup to tackle this challenge. In particular, we introduce Constraint-based Manipulation for Bimanual Occluded Grasping (COMBO-Grasp), a learning-based approach which leverages two coordinated policies: a constraint policy trained using self-supervised datasets to generate stabilising poses and a grasping policy trained using RL that reorients and grasps the target object. A key contribution lies in value function-guided policy coordination. Specifically, during RL training for the grasping policy, the constraint policy's output is refined through gradients from a jointly trained value function, improving bimanual coordination and task performance. Lastly, COMBO-Grasp employs teacher-student policy distillation to effectively deploy point cloud-based policies in real-world environments. Empirical evaluations demonstrate that COMBO-Grasp significantly improves task success rates compared to competitive baseline approaches, with successful generalisation to unseen objects in both simulated and real-world environments.