 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic ODYN: Differentiable Optimization for Infeasible Control and Learning in Robotics
Jun 15, 2026Robotic systems routinely encounter conflicting objectives, modeling errors, and degenerate contact conditions that render quadratic programs (QPs) infeasible. Yet most optimization solvers and differentiable QP layers assume feasibility, leading to numerical failures, unstable gradients, or solver breakdown when constraints cannot be simultaneously satisfied. We present Elastic ODYN, a primal--dual non-interior-point QP solver that handles infeasibility through smooth squared-$\ell_2$ elastic relaxations. The resulting formulation remains well posed under ill-conditioning and degeneracy, supports warm starting, and converges to closest-to-feasible solutions when no feasible point exists. A lightweight refinement stage recovers physically meaningful dual variables from the elastic solution. Building on this framework, we develop Elastic OdynLayer, a differentiable QP layer with stable gradients under infeasibility, and Elastic OdynSQP, an infeasibility-aware SQP method that resolves inconsistent subproblems and intrinsically infeasible optimal control tasks through selective constraint relaxation. We evaluate the framework on benchmark QPs, singular contact mechanics, differentiable parameter identification, and quadrupedal and humanoid trajectory optimization. Across all settings, Elastic ODYN consistently outperforms state-of-the-art elastic QP solvers in robustness, warm-start performance, and convergence reliability, enabling optimization, simulation, control, and learning beyond the feasibility assumptions of existing methods.
ODYN: An All-Shifted Non-Interior-Point Method for Quadratic Programming in Robotics and AI
Feb 17, 2026We introduce ODYN, a novel all-shifted primal-dual non-interior-point quadratic programming (QP) solver designed to efficiently handle challenging dense and sparse QPs. ODYN combines all-shifted nonlinear complementarity problem (NCP) functions with proximal method of multipliers to robustly address ill-conditioned and degenerate problems, without requiring linear independence of the constraints. It exhibits strong warm-start performance and is well suited to both general-purpose optimization, and robotics and AI applications, including model-based control, estimation, and kernel-based learning methods. We provide an open-source implementation and benchmark ODYN on the Maros-Mészáros test set, demonstrating state-of-the-art convergence performance in small-to-high-scale problems. The results highlight ODYN's superior warm-starting capabilities, which are critical in sequential and real-time settings common in robotics and AI. These advantages are further demonstrated by deploying ODYN as the backend of an SQP-based predictive control framework (OdynSQP), as the implicitly differentiable optimization layer for deep learning (ODYNLayer), and the optimizer of a contact-dynamics simulation (ODYNSim).
PlatoLTL: Learning to Generalize Across Symbols in LTL Instructions for Multi-Task RL
Jan 30, 2026A central challenge in multi-task reinforcement learning (RL) is to train generalist policies capable of performing tasks not seen during training. To facilitate such generalization, linear temporal logic (LTL) has recently emerged as a powerful formalism for specifying structured, temporally extended tasks to RL agents. While existing approaches to LTL-guided multi-task RL demonstrate successful generalization across LTL specifications, they are unable to generalize to unseen vocabularies of propositions (or "symbols"), which describe high-level events in LTL. We present PlatoLTL, a novel approach that enables policies to zero-shot generalize not only compositionally across LTL formula structures, but also parametrically across propositions. We achieve this by treating propositions as instances of parameterized predicates rather than discrete symbols, allowing policies to learn shared structure across related propositions. We propose a novel architecture that embeds and composes predicates to represent LTL specifications, and demonstrate successful zero-shot generalization to novel propositions and tasks across challenging environments.
Vision-Language-Policy Model for Dynamic Robot Task Planning
Dec 22, 2025



Bridging the gap between natural language commands and autonomous execution in unstructured environments remains an open challenge for robotics. This requires robots to perceive and reason over the current task scene through multiple modalities, and to plan their behaviors to achieve their intended goals. Traditional robotic task-planning approaches often struggle to bridge low-level execution with high-level task reasoning, and cannot dynamically update task strategies when instructions change during execution, which ultimately limits their versatility and adaptability to new tasks. In this work, we propose a novel language model-based framework for dynamic robot task planning. Our Vision-Language-Policy (VLP) model, based on a vision-language model fine-tuned on real-world data, can interpret semantic instructions and integrate reasoning over the current task scene to generate behavior policies that control the robot to accomplish the task. Moreover, it can dynamically adjust the task strategy in response to changes in the task, enabling flexible adaptation to evolving task requirements. Experiments conducted with different robots and a variety of real-world tasks show that the trained model can efficiently adapt to novel scenarios and dynamically update its policy, demonstrating strong planning autonomy and cross-embodiment generalization. Videos: https://robovlp.github.io/
QuantGraph: A Receding-Horizon Quantum Graph Solver
Dec 17, 2025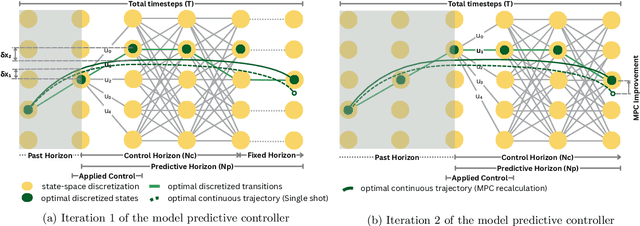
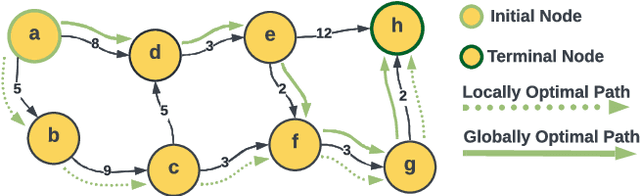
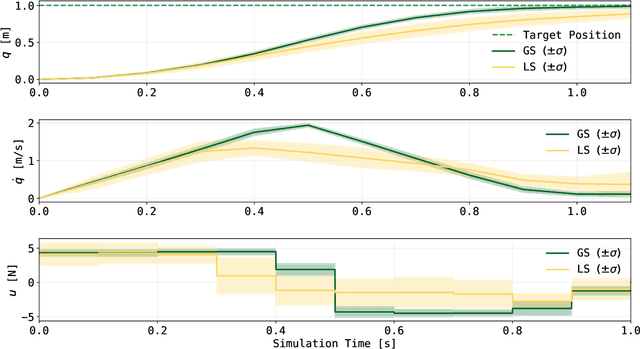
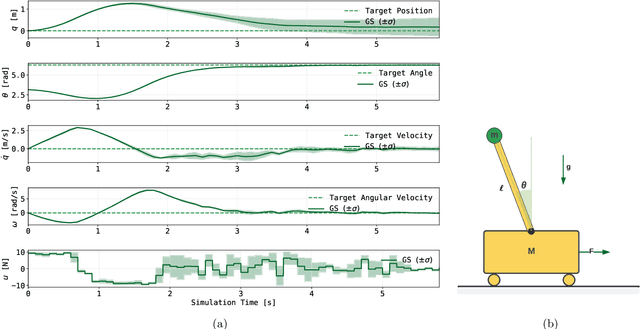
Dynamic programming is a cornerstone of graph-based optimization. While effective, it scales unfavorably with problem size. In this work, we present QuantGraph, a two-stage quantum-enhanced framework that casts local and global graph-optimization problems as quantum searches over discrete trajectory spaces. The solver is designed to operate efficiently by first finding a sequence of locally optimal transitions in the graph (local stage), without considering full trajectories. The accumulated cost of these transitions acts as a threshold that prunes the search space (up to 60% reduction for certain examples). The subsequent global stage, based on this threshold, refines the solution. Both stages utilize variants of the Grover-adaptive-search algorithm. To achieve scalability and robustness, we draw on principles from control theory and embed QuantGraph's global stage within a receding-horizon model-predictive-control scheme. This classical layer stabilizes and guides the quantum search, improving precision and reducing computational burden. In practice, the resulting closed-loop system exhibits robust behavior and lower overall complexity. Notably, for a fixed query budget, QuantGraph attains a 2x increase in control-discretization precision while still benefiting from Grover-search's inherent quadratic speedup compared to classical methods.
Sampling Strategies for Robust Universal Quadrupedal Locomotion Policies
Oct 08, 2025This work focuses on sampling strategies of configuration variations for generating robust universal locomotion policies for quadrupedal robots. We investigate the effects of sampling physical robot parameters and joint proportional-derivative gains to enable training a single reinforcement learning policy that generalizes to multiple parameter configurations. Three fundamental joint gain sampling strategies are compared: parameter sampling with (1) linear and polynomial function mappings of mass-to-gains, (2) performance-based adaptive filtering, and (3) uniform random sampling. We improve the robustness of the policy by biasing the configurations using nominal priors and reference models. All training was conducted on RaiSim, tested in simulation on a range of diverse quadrupeds, and zero-shot deployed onto hardware using the ANYmal quadruped robot. Compared to multiple baseline implementations, our results demonstrate the need for significant joint controller gains randomization for robust closing of the sim-to-real gap.
Learning Physical Systems: Symplectification via Gauge Fixing in Dirac Structures
Jun 23, 2025
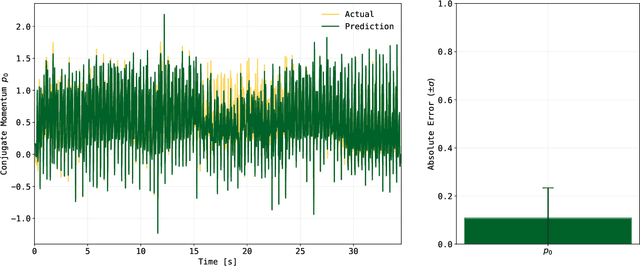

Physics-informed deep learning has achieved remarkable progress by embedding geometric priors, such as Hamiltonian symmetries and variational principles, into neural networks, enabling structure-preserving models that extrapolate with high accuracy. However, in systems with dissipation and holonomic constraints, ubiquitous in legged locomotion and multibody robotics, the canonical symplectic form becomes degenerate, undermining the very invariants that guarantee stability and long-term prediction. In this work, we tackle this foundational limitation by introducing Presymplectification Networks (PSNs), the first framework to learn the symplectification lift via Dirac structures, restoring a non-degenerate symplectic geometry by embedding constrained systems into a higher-dimensional manifold. Our architecture combines a recurrent encoder with a flow-matching objective to learn the augmented phase-space dynamics end-to-end. We then attach a lightweight Symplectic Network (SympNet) to forecast constrained trajectories while preserving energy, momentum, and constraint satisfaction. We demonstrate our method on the dynamics of the ANYmal quadruped robot, a challenging contact-rich, multibody system. To the best of our knowledge, this is the first framework that effectively bridges the gap between constrained, dissipative mechanical systems and symplectic learning, unlocking a whole new class of geometric machine learning models, grounded in first principles yet adaptable from data.
Reference Free Platform Adaptive Locomotion for Quadrupedal Robots using a Dynamics Conditioned Policy
May 21, 2025This article presents Platform Adaptive Locomotion (PAL), a unified control method for quadrupedal robots with different morphologies and dynamics. We leverage deep reinforcement learning to train a single locomotion policy on procedurally generated robots. The policy maps proprioceptive robot state information and base velocity commands into desired joint actuation targets, which are conditioned using a latent embedding of the temporally local system dynamics. We explore two conditioning strategies - one using a GRU-based dynamics encoder and another using a morphology-based property estimator - and show that morphology-aware conditioning outperforms temporal dynamics encoding regarding velocity task tracking for our hardware test on ANYmal C. Our results demonstrate that both approaches achieve robust zero-shot transfer across multiple unseen simulated quadrupeds. Furthermore, we demonstrate the need for careful robot reference modelling during training, enabling us to reduce the velocity tracking error by up to 30% compared to the baseline method. Despite PAL not surpassing the best-performing reference-free controller in all cases, our analysis uncovers critical design choices and informs improvements to the state of the art.
Neural Associative Skill Memories for safer robotics and modelling human sensorimotor repertoires
May 14, 2025Modern robots face challenges shared by humans, where machines must learn multiple sensorimotor skills and express them adaptively. Equipping robots with a human-like memory of how it feels to do multiple stereotypical movements can make robots more aware of normal operational states and help develop self-preserving safer robots. Associative Skill Memories (ASMs) aim to address this by linking movement primitives to sensory feedback, but existing implementations rely on hard-coded libraries of individual skills. A key unresolved problem is how a single neural network can learn a repertoire of skills while enabling fault detection and context-aware execution. Here we introduce Neural Associative Skill Memories (ASMs), a framework that utilises self-supervised predictive coding for temporal prediction to unify skill learning and expression, using biologically plausible learning rules. Unlike traditional ASMs which require explicit skill selection, Neural ASMs implicitly recognize and express skills through contextual inference, enabling fault detection across learned behaviours without an explicit skill selection mechanism. Compared to recurrent neural networks trained via backpropagation through time, our model achieves comparable qualitative performance in skill memory expression while using local learning rules and predicts a biologically relevant speed-accuracy trade-off during skill memory expression. This work advances the field of neurorobotics by demonstrating how predictive coding principles can model adaptive robot control and human motor preparation. By unifying fault detection, reactive control, skill memorisation and expression into a single energy-based architecture, Neural ASMs contribute to safer robotics and provide a computational lens to study biological sensorimotor learning.
Improving Trajectory Stitching with Flow Models
May 12, 2025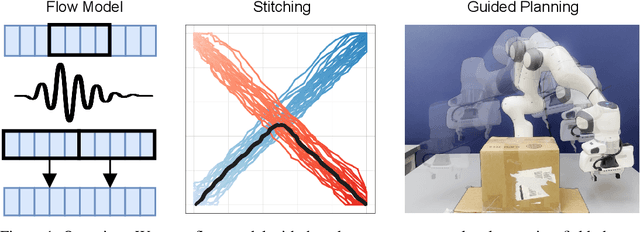



Generative models have shown great promise as trajectory planners, given their affinity to modeling complex distributions and guidable inference process. Previous works have successfully applied these in the context of robotic manipulation but perform poorly when the required solution does not exist as a complete trajectory within the training set. We identify that this is a result of being unable to plan via stitching, and subsequently address the architectural and dataset choices needed to remedy this. On top of this, we propose a novel addition to the training and inference procedures to both stabilize and enhance these capabilities. We demonstrate the efficacy of our approach by generating plans with out of distribution boundary conditions and performing obstacle avoidance on the Franka Panda in simulation and on real hardware. In both of these tasks our method performs significantly better than the baselines and is able to avoid obstacles up to four times as large.