 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill and Align Decomposition for Enhanced Claim Verification
Feb 25, 2026Complex claim verification requires decomposing sentences into verifiable subclaims, yet existing methods struggle to align decomposition quality with verification performance. We propose a reinforcement learning (RL) approach that jointly optimizes decomposition quality and verifier alignment using Group Relative Policy Optimization (GRPO). Our method integrates: (i) structured sequential reasoning; (ii) supervised finetuning on teacher-distilled exemplars; and (iii) a multi-objective reward balancing format compliance, verifier alignment, and decomposition quality. Across six evaluation settings, our trained 8B decomposer improves downstream verification performance to (71.75%) macro-F1, outperforming prompt-based approaches ((+1.99), (+6.24)) and existing RL methods ((+5.84)). Human evaluation confirms the high quality of the generated subclaims. Our framework enables smaller language models to achieve state-of-the-art claim verification by jointly optimising for verification accuracy and decomposition quality.
Discovery of skill switching criteria for learning agile quadruped locomotion
Feb 10, 2025This paper develops a hierarchical learning and optimization framework that can learn and achieve well-coordinated multi-skill locomotion. The learned multi-skill policy can switch between skills automatically and naturally in tracking arbitrarily positioned goals and recover from failures promptly. The proposed framework is composed of a deep reinforcement learning process and an optimization process. First, the contact pattern is incorporated into the reward terms for learning different types of gaits as separate policies without the need for any other references. Then, a higher level policy is learned to generate weights for individual policies to compose multi-skill locomotion in a goal-tracking task setting. Skills are automatically and naturally switched according to the distance to the goal. The proper distances for skill switching are incorporated in reward calculation for learning the high level policy and updated by an outer optimization loop as learning progresses. We first demonstrated successful multi-skill locomotion in comprehensive tasks on a simulated Unitree A1 quadruped robot. We also deployed the learned policy in the real world showcasing trotting, bounding, galloping, and their natural transitions as the goal position changes. Moreover, the learned policy can react to unexpected failures at any time, perform prompt recovery, and resume locomotion successfully. Compared to discrete switch between single skills which failed to transition to galloping in the real world, our proposed approach achieves all the learned agile skills, with smoother and more continuous skill transitions.
Are Large Language Models Strategic Decision Makers? A Study of Performance and Bias in Two-Player Non-Zero-Sum Games
Jul 05, 2024



Large Language Models (LLMs) have been increasingly used in real-world settings, yet their strategic abilities remain largely unexplored. Game theory provides a good framework for assessing the decision-making abilities of LLMs in interactions with other agents. Although prior studies have shown that LLMs can solve these tasks with carefully curated prompts, they fail when the problem setting or prompt changes. In this work we investigate LLMs' behaviour in strategic games, Stag Hunt and Prisoner Dilemma, analyzing performance variations under different settings and prompts. Our results show that the tested state-of-the-art LLMs exhibit at least one of the following systematic biases: (1) positional bias, (2) payoff bias, or (3) behavioural bias. Subsequently, we observed that the LLMs' performance drops when the game configuration is misaligned with the affecting biases. Performance is assessed based on the selection of the correct action, one which agrees with the prompted preferred behaviours of both players. Alignment refers to whether the LLM's bias aligns with the correct action. For example, GPT-4o's average performance drops by 34% when misaligned. Additionally, the current trend of "bigger and newer is better" does not hold for the above, where GPT-4o (the current best-performing LLM) suffers the most substantial performance drop. Lastly, we note that while chain-of-thought prompting does reduce the effect of the biases on most models, it is far from solving the problem at the fundamental level.
Towards Generalist Robot Learning from Internet Video: A Survey
Apr 30, 2024



This survey presents an overview of methods for learning from video (LfV) in the context of reinforcement learning (RL) and robotics. We focus on methods capable of scaling to large internet video datasets and, in the process, extracting foundational knowledge about the world's dynamics and physical human behaviour. Such methods hold great promise for developing general-purpose robots. We open with an overview of fundamental concepts relevant to the LfV-for-robotics setting. This includes a discussion of the exciting benefits LfV methods can offer (e.g., improved generalization beyond the available robot data) and commentary on key LfV challenges (e.g., challenges related to missing information in video and LfV distribution shifts). Our literature review begins with an analysis of video foundation model techniques that can extract knowledge from large, heterogeneous video datasets. Next, we review methods that specifically leverage video data for robot learning. Here, we categorise work according to which RL knowledge modality benefits from the use of video data. We additionally highlight techniques for mitigating LfV challenges, including reviewing action representations that address the issue of missing action labels in video. Finally, we examine LfV datasets and benchmarks, before concluding the survey by discussing challenges and opportunities in LfV. Here, we advocate for scalable approaches that can leverage the full range of available data and that target the key benefits of LfV. Overall, we hope this survey will serve as a comprehensive reference for the emerging field of LfV, catalysing further research in the area, and ultimately facilitating progress towards obtaining general-purpose robots.
Deep Reinforcement Learning and Mean-Variance Strategies for Responsible Portfolio Optimization
Mar 25, 2024Portfolio optimization involves determining the optimal allocation of portfolio assets in order to maximize a given investment objective. Traditionally, some form of mean-variance optimization is used with the aim of maximizing returns while minimizing risk, however, more recently, deep reinforcement learning formulations have been explored. Increasingly, investors have demonstrated an interest in incorporating ESG objectives when making investment decisions, and modifications to the classical mean-variance optimization framework have been developed. In this work, we study the use of deep reinforcement learning for responsible portfolio optimization, by incorporating ESG states and objectives, and provide comparisons against modified mean-variance approaches. Our results show that deep reinforcement learning policies can provide competitive performance against mean-variance approaches for responsible portfolio allocation across additive and multiplicative utility functions of financial and ESG responsibility objectives.
Distilling Reinforcement Learning Policies for Interpretable Robot Locomotion: Gradient Boosting Machines and Symbolic Regression
Mar 21, 2024
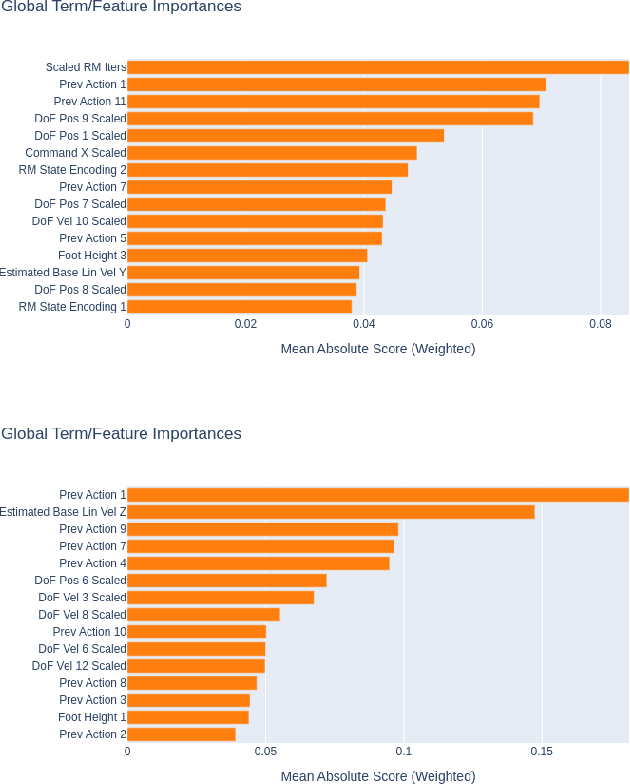
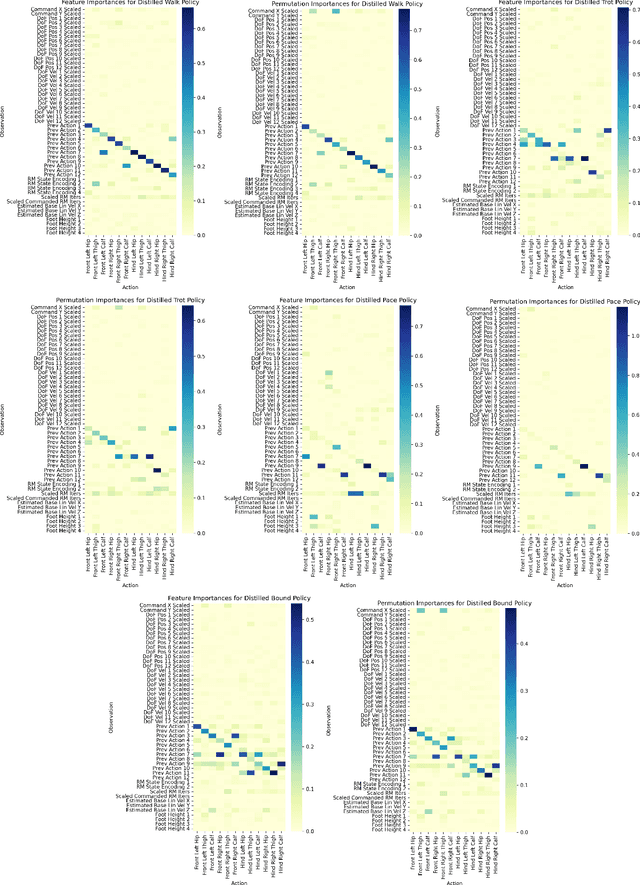
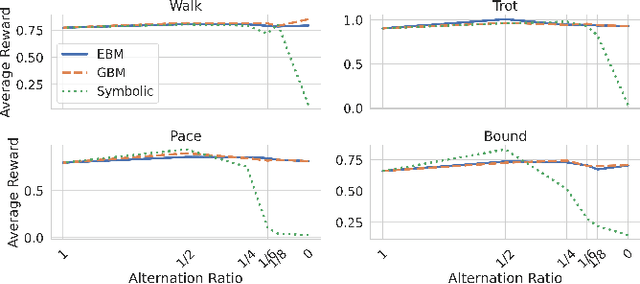
Recent advancements in reinforcement learning (RL) have led to remarkable achievements in robot locomotion capabilities. However, the complexity and ``black-box'' nature of neural network-based RL policies hinder their interpretability and broader acceptance, particularly in applications demanding high levels of safety and reliability. This paper introduces a novel approach to distill neural RL policies into more interpretable forms using Gradient Boosting Machines (GBMs), Explainable Boosting Machines (EBMs) and Symbolic Regression. By leveraging the inherent interpretability of generalized additive models, decision trees, and analytical expressions, we transform opaque neural network policies into more transparent ``glass-box'' models. We train expert neural network policies using RL and subsequently distill them into (i) GBMs, (ii) EBMs, and (iii) symbolic policies. To address the inherent distribution shift challenge of behavioral cloning, we propose to use the Dataset Aggregation (DAgger) algorithm with a curriculum of episode-dependent alternation of actions between expert and distilled policies, to enable efficient distillation of feedback control policies. We evaluate our approach on various robot locomotion gaits -- walking, trotting, bounding, and pacing -- and study the importance of different observations in joint actions for distilled policies using various methods. We train neural expert policies for 205 hours of simulated experience and distill interpretable policies with only 10 minutes of simulated interaction for each gait using the proposed method.
Modular Neural Network Policies for Learning In-Flight Object Catching with a Robot Hand-Arm System
Dec 21, 2023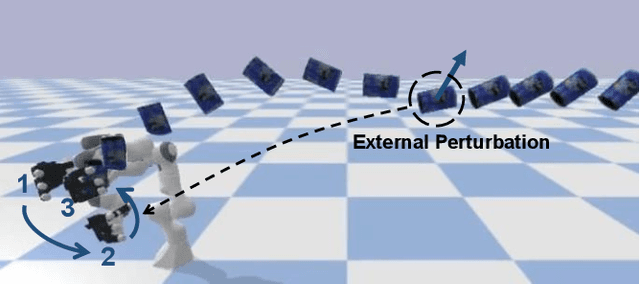
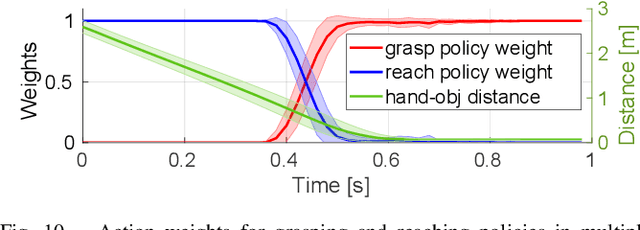


We present a modular framework designed to enable a robot hand-arm system to learn how to catch flying objects, a task that requires fast, reactive, and accurately-timed robot motions. Our framework consists of five core modules: (i) an object state estimator that learns object trajectory prediction, (ii) a catching pose quality network that learns to score and rank object poses for catching, (iii) a reaching control policy trained to move the robot hand to pre-catch poses, (iv) a grasping control policy trained to perform soft catching motions for safe and robust grasping, and (v) a gating network trained to synthesize the actions given by the reaching and grasping policy. The former two modules are trained via supervised learning and the latter three use deep reinforcement learning in a simulated environment. We conduct extensive evaluations of our framework in simulation for each module and the integrated system, to demonstrate high success rates of in-flight catching and robustness to perturbations and sensory noise. Whilst only simple cylindrical and spherical objects are used for training, the integrated system shows successful generalization to a variety of household objects that are not used in training.
RObotic MAnipulation Network (ROMAN) $\unicode{x2013}$ Hybrid Hierarchical Learning for Solving Complex Sequential Tasks
Jul 07, 2023Solving long sequential tasks poses a significant challenge in embodied artificial intelligence. Enabling a robotic system to perform diverse sequential tasks with a broad range of manipulation skills is an active area of research. In this work, we present a Hybrid Hierarchical Learning framework, the Robotic Manipulation Network (ROMAN), to address the challenge of solving multiple complex tasks over long time horizons in robotic manipulation. ROMAN achieves task versatility and robust failure recovery by integrating behavioural cloning, imitation learning, and reinforcement learning. It consists of a central manipulation network that coordinates an ensemble of various neural networks, each specialising in distinct re-combinable sub-tasks to generate their correct in-sequence actions for solving complex long-horizon manipulation tasks. Experimental results show that by orchestrating and activating these specialised manipulation experts, ROMAN generates correct sequential activations for accomplishing long sequences of sophisticated manipulation tasks and achieving adaptive behaviours beyond demonstrations, while exhibiting robustness to various sensory noises. These results demonstrate the significance and versatility of ROMAN's dynamic adaptability featuring autonomous failure recovery capabilities, and highlight its potential for various autonomous manipulation tasks that demand adaptive motor skills.
Value Functions are Control Barrier Functions: Verification of Safe Policies using Control Theory
Jun 08, 2023



Guaranteeing safe behaviour of reinforcement learning (RL) policies poses significant challenges for safety-critical applications, despite RL's generality and scalability. To address this, we propose a new approach to apply verification methods from control theory to learned value functions. By analyzing task structures for safety preservation, we formalize original theorems that establish links between value functions and control barrier functions. Further, we propose novel metrics for verifying value functions in safe control tasks and practical implementation details to improve learning. Our work presents a novel method for certificate learning, which unlocks a diversity of verification techniques from control theory for RL policies, and marks a significant step towards a formal framework for the general, scalable, and verifiable design of RL-based control systems.
Learning Perceptual Locomotion on Uneven Terrains using Sparse Visual Observations
Sep 28, 2021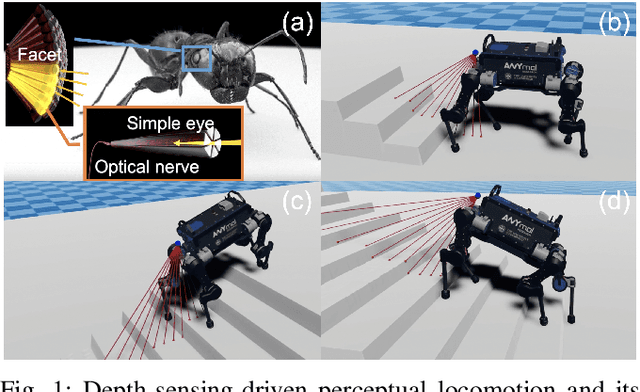
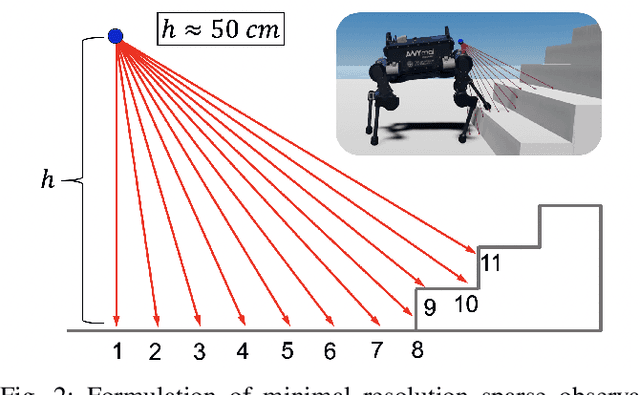
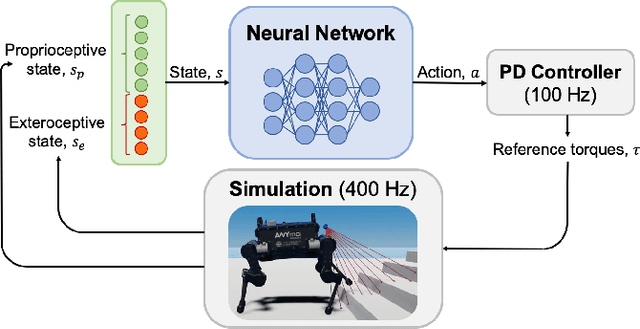
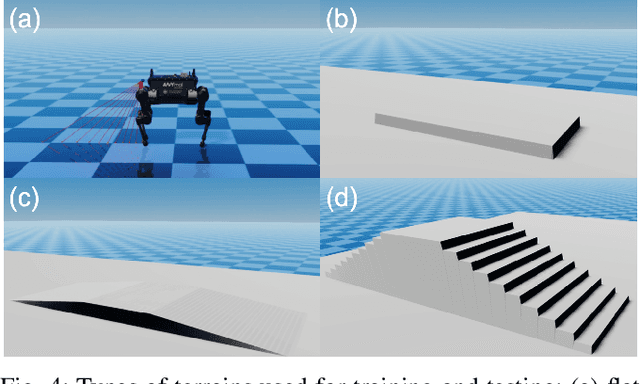
Legged robots have achieved remarkable performance in blind walking using either model-based control or data-driven deep reinforcement learning. To proactively navigate and traverse various terrains, active use of visual perception becomes indispensable, and this work aims to exploit the use of sparse visual observations to achieve perceptual locomotion over a range of commonly seen bumps, ramps, and stairs in human-centred environments. We first formulate the selection of minimal visual input that can represent the uneven surfaces of interest, and propose a learning framework that integrates such exteroceptive and proprioceptive data. We specifically select state observations and design a training curriculum to learn feedback control policies more effectively over a range of different terrains. Using an extensive benchmark, we validate the learned policy in tasks that require omnidirectional walking over flat ground and forward locomotion over terrains with obstacles, showing a high success rate of traversal. Particularly, the robot performs autonomous perceptual locomotion with minimal visual perception using depth measurements, which are easily available from a Lidar or RGB-D sensor, and successfully demonstrates robust ascent and descent over high stairs of 20 cm step height, i.e., 50% of its leg length.