 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Do We Need LLMs? A Diagnostic for Language-Driven Bandits
Apr 07, 2026We study Contextual Multi-Armed Bandits (CMABs) for non-episodic sequential decision making problems where the context includes both textual and numerical information (e.g., recommendation systems, dynamic portfolio adjustments, offer selection; all frequent problems in finance). While Large Language Models (LLMs) are increasingly applied to these settings, utilizing LLMs for reasoning at every decision step is computationally expensive and uncertainty estimates are difficult to obtain. To address this, we introduce LLMP-UCB, a bandit algorithm that derives uncertainty estimates from LLMs via repeated inference. However, our experiments demonstrate that lightweight numerical bandits operating on text embeddings (dense or Matryoshka) match or exceed the accuracy of LLM-based solutions at a fraction of their cost. We further show that embedding dimensionality is a practical lever on the exploration-exploitation balance, enabling cost--performance tradeoffs without prompt complexity. Finally, to guide practitioners, we propose a geometric diagnostic based on the arms' embedding to decide when to use LLM-driven reasoning versus a lightweight numerical bandit. Our results provide a principled deployment framework for cost-effective, uncertainty-aware decision systems with broad applicability across AI use cases in financial services.
GenePlan: Evolving Better Generalized PDDL Plans using Large Language Models
Mar 10, 2026We present GenePlan (GENeralized Evolutionary Planner), a novel framework that leverages large language model (LLM) assisted evolutionary algorithms to generate domain-dependent generalized planners for classical planning tasks described in PDDL. By casting generalized planning as an optimization problem, GenePlan iteratively evolves interpretable Python planners that minimize plan length across diverse problem instances. In empirical evaluation across six existing benchmark domains and two new domains, GenePlan achieved an average SAT score of 0.91, closely matching the performance of the state-of-the-art planners (SAT score 0.93), and significantly outperforming other LLM-based baselines such as chain-of-thought (CoT) prompting (average SAT score 0.64). The generated planners solve new instances rapidly (average 0.49 seconds per task) and at low cost (average $1.82 per domain using GPT-4o).
Beyond Manual Planning: Seating Allocation for Large Organizations
Feb 05, 2026We introduce the Hierarchical Seating Allocation Problem (HSAP) which addresses the optimal assignment of hierarchically structured organizational teams to physical seating arrangements on a floor plan. This problem is driven by the necessity for large organizations with large hierarchies to ensure that teams with close hierarchical relationships are seated in proximity to one another, such as ensuring a research group occupies a contiguous area. Currently, this problem is managed manually leading to infrequent and suboptimal replanning efforts. To alleviate this manual process, we propose an end-to-end framework to solve the HSAP. A scalable approach to calculate the distance between any pair of seats using a probabilistic road map (PRM) and rapidly-exploring random trees (RRT) which is combined with heuristic search and dynamic programming approach to solve the HSAP using integer programming. We demonstrate our approach under different sized instances by evaluating the PRM framework and subsequent allocations both quantitatively and qualitatively.
The Subset Sum Matching Problem
Aug 26, 2025



This paper presents a new combinatorial optimisation task, the Subset Sum Matching Problem (SSMP), which is an abstraction of common financial applications such as trades reconciliation. We present three algorithms, two suboptimal and one optimal, to solve this problem. We also generate a benchmark to cover different instances of SSMP varying in complexity, and carry out an experimental evaluation to assess the performance of the approaches.
ELATE: Evolutionary Language model for Automated Time-series Engineering
Aug 20, 2025Time-series prediction involves forecasting future values using machine learning models. Feature engineering, whereby existing features are transformed to make new ones, is critical for enhancing model performance, but is often manual and time-intensive. Existing automation attempts rely on exhaustive enumeration, which can be computationally costly and lacks domain-specific insights. We introduce ELATE (Evolutionary Language model for Automated Time-series Engineering), which leverages a language model within an evolutionary framework to automate feature engineering for time-series data. ELATE employs time-series statistical measures and feature importance metrics to guide and prune features, while the language model proposes new, contextually relevant feature transformations. Our experiments demonstrate that ELATE improves forecasting accuracy by an average of 8.4% across various domains.
Model Evaluation in the Dark: Robust Classifier Metrics with Missing Labels
Apr 25, 2025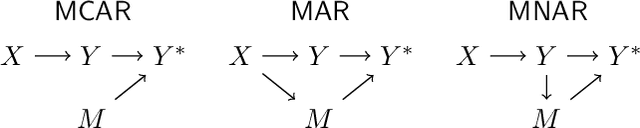

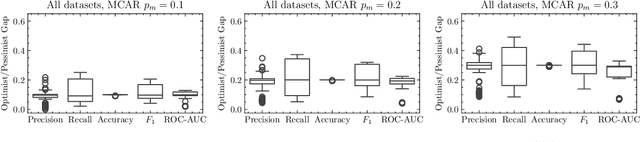

Missing data in supervised learning is well-studied, but the specific issue of missing labels during model evaluation has been overlooked. Ignoring samples with missing values, a common solution, can introduce bias, especially when data is Missing Not At Random (MNAR). We propose a multiple imputation technique for evaluating classifiers using metrics such as precision, recall, and ROC-AUC. This method not only offers point estimates but also a predictive distribution for these quantities when labels are missing. We empirically show that the predictive distribution's location and shape are generally correct, even in the MNAR regime. Moreover, we establish that this distribution is approximately Gaussian and provide finite-sample convergence bounds. Additionally, a robustness proof is presented, confirming the validity of the approximation under a realistic error model.
Temporal Fairness in Decision Making Problems
Aug 23, 2024



In this work we consider a new interpretation of fairness in decision making problems. Building upon existing fairness formulations, we focus on how to reason over fairness from a temporal perspective, taking into account the fairness of a history of past decisions. After introducing the concept of temporal fairness, we propose three approaches that incorporate temporal fairness in decision making problems formulated as optimization problems. We present a qualitative evaluation of our approach in four different domains and compare the solutions against a baseline approach that does not consider the temporal aspect of fairness.
Deep Reinforcement Learning and Mean-Variance Strategies for Responsible Portfolio Optimization
Mar 25, 2024Portfolio optimization involves determining the optimal allocation of portfolio assets in order to maximize a given investment objective. Traditionally, some form of mean-variance optimization is used with the aim of maximizing returns while minimizing risk, however, more recently, deep reinforcement learning formulations have been explored. Increasingly, investors have demonstrated an interest in incorporating ESG objectives when making investment decisions, and modifications to the classical mean-variance optimization framework have been developed. In this work, we study the use of deep reinforcement learning for responsible portfolio optimization, by incorporating ESG states and objectives, and provide comparisons against modified mean-variance approaches. Our results show that deep reinforcement learning policies can provide competitive performance against mean-variance approaches for responsible portfolio allocation across additive and multiplicative utility functions of financial and ESG responsibility objectives.
Surrogate Assisted Monte Carlo Tree Search in Combinatorial Optimization
Mar 14, 2024Industries frequently adjust their facilities network by opening new branches in promising areas and closing branches in areas where they expect low profits. In this paper, we examine a particular class of facility location problems. Our objective is to minimize the loss of sales resulting from the removal of several retail stores. However, estimating sales accurately is expensive and time-consuming. To overcome this challenge, we leverage Monte Carlo Tree Search (MCTS) assisted by a surrogate model that computes evaluations faster. Results suggest that MCTS supported by a fast surrogate function can generate solutions faster while maintaining a consistent solution compared to MCTS that does not benefit from the surrogate function.
Towards Accelerating Benders Decomposition via Reinforcement Learning Surrogate Models
Jul 17, 2023



Stochastic optimization (SO) attempts to offer optimal decisions in the presence of uncertainty. Often, the classical formulation of these problems becomes intractable due to (a) the number of scenarios required to capture the uncertainty and (b) the discrete nature of real-world planning problems. To overcome these tractability issues, practitioners turn to decomposition methods that divide the problem into smaller, more tractable sub-problems. The focal decomposition method of this paper is Benders decomposition (BD), which decomposes stochastic optimization problems on the basis of scenario independence. In this paper we propose a method of accelerating BD with the aid of a surrogate model in place of an NP-hard integer master problem. Through the acceleration method we observe 30% faster average convergence when compared to other accelerated BD implementations. We introduce a reinforcement learning agent as a surrogate and demonstrate how it can be used to solve a stochastic inventory management problem.