 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDKPROMPT: Domain Knowledge Prompting Vision-Language Models for Open-World Planning
Jun 25, 2024Vision-language models (VLMs) have been applied to robot task planning problems, where the robot receives a task in natural language and generates plans based on visual inputs. While current VLMs have demonstrated strong vision-language understanding capabilities, their performance is still far from being satisfactory in planning tasks. At the same time, although classical task planners, such as PDDL-based, are strong in planning for long-horizon tasks, they do not work well in open worlds where unforeseen situations are common. In this paper, we propose a novel task planning and execution framework, called DKPROMPT, which automates VLM prompting using domain knowledge in PDDL for classical planning in open worlds. Results from quantitative experiments show that DKPROMPT outperforms classical planning, pure VLM-based and a few other competitive baselines in task completion rate.
Surrogate Assisted Monte Carlo Tree Search in Combinatorial Optimization
Mar 14, 2024Industries frequently adjust their facilities network by opening new branches in promising areas and closing branches in areas where they expect low profits. In this paper, we examine a particular class of facility location problems. Our objective is to minimize the loss of sales resulting from the removal of several retail stores. However, estimating sales accurately is expensive and time-consuming. To overcome this challenge, we leverage Monte Carlo Tree Search (MCTS) assisted by a surrogate model that computes evaluations faster. Results suggest that MCTS supported by a fast surrogate function can generate solutions faster while maintaining a consistent solution compared to MCTS that does not benefit from the surrogate function.
Integrating Action Knowledge and LLMs for Task Planning and Situation Handling in Open Worlds
May 27, 2023Task planning systems have been developed to help robots use human knowledge (about actions) to complete long-horizon tasks. Most of them have been developed for "closed worlds" while assuming the robot is provided with complete world knowledge. However, the real world is generally open, and the robots frequently encounter unforeseen situations that can potentially break the planner's completeness. Could we leverage the recent advances on pre-trained Large Language Models (LLMs) to enable classical planning systems to deal with novel situations? This paper introduces a novel framework, called COWP, for open-world task planning and situation handling. COWP dynamically augments the robot's action knowledge, including the preconditions and effects of actions, with task-oriented commonsense knowledge. COWP embraces the openness from LLMs, and is grounded to specific domains via action knowledge. For systematic evaluations, we collected a dataset that includes 1,085 execution-time situations. Each situation corresponds to a state instance wherein a robot is potentially unable to complete a task using a solution that normally works. Experimental results show that our approach outperforms competitive baselines from the literature in the success rate of service tasks. Additionally, we have demonstrated COWP using a mobile manipulator. Supplementary materials are available at: https://cowplanning.github.io/
Grounding Classical Task Planners via Vision-Language Models
Apr 17, 2023



Classical planning systems have shown great advances in utilizing rule-based human knowledge to compute accurate plans for service robots, but they face challenges due to the strong assumptions of perfect perception and action executions. To tackle these challenges, one solution is to connect the symbolic states and actions generated by classical planners to the robot's sensory observations, thus closing the perception-action loop. This research proposes a visually-grounded planning framework, named TPVQA, which leverages Vision-Language Models (VLMs) to detect action failures and verify action affordances towards enabling successful plan execution. Results from quantitative experiments show that TPVQA surpasses competitive baselines from previous studies in task completion rate.
Robot Task Planning and Situation Handling in Open Worlds
Oct 04, 2022
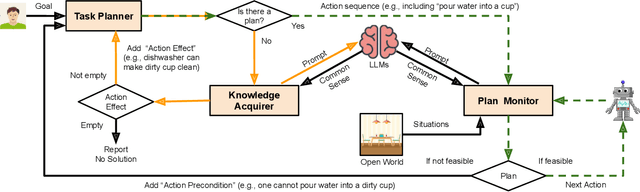
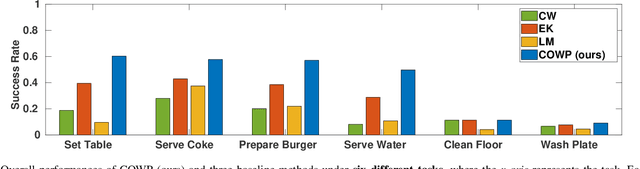
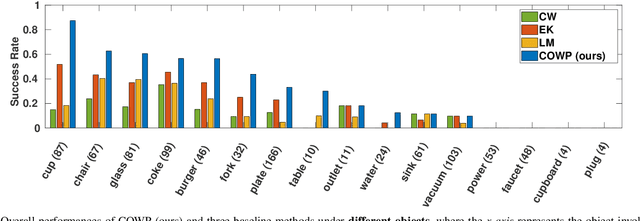
Automated task planning algorithms have been developed to help robots complete complex tasks that require multiple actions. Most of those algorithms have been developed for "closed worlds" assuming complete world knowledge is provided. However, the real world is generally open, and the robots frequently encounter unforeseen situations that can potentially break the planner's completeness. This paper introduces a novel algorithm (COWP) for open-world task planning and situation handling that dynamically augments the robot's action knowledge with task-oriented common sense. In particular, common sense is extracted from Large Language Models based on the current task at hand and robot skills. For systematic evaluations, we collected a dataset that includes 561 execution-time situations in a dining domain, where each situation corresponds to a state instance of a robot being potentially unable to complete a task using a solution that normally works. Experimental results show that our approach significantly outperforms competitive baselines from the literature in the success rate of service tasks. Additionally, we have demonstrated COWP using a mobile manipulator. Supplementary materials are available at: https://cowplanning.github.io/
Reasoning with Scene Graphs for Robot Planning under Partial Observability
Feb 21, 2022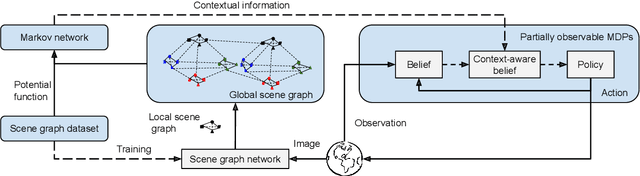
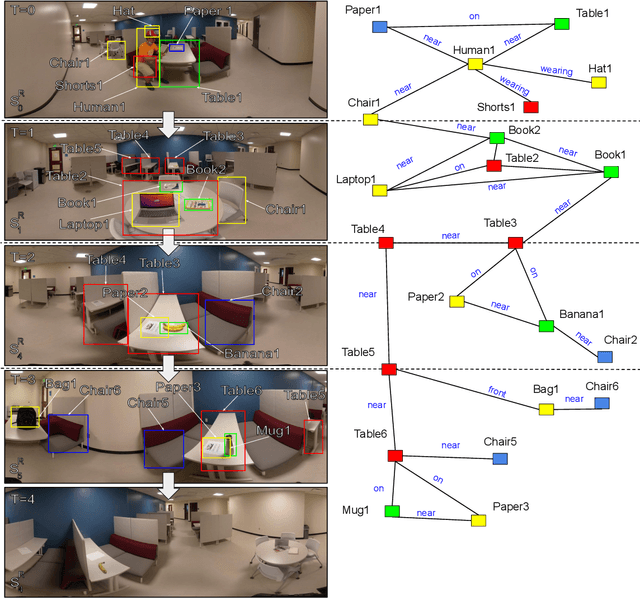

Robot planning in partially observable domains is difficult, because a robot needs to estimate the current state and plan actions at the same time. When the domain includes many objects, reasoning about the objects and their relationships makes robot planning even more difficult. In this paper, we develop an algorithm called scene analysis for robot planning (SARP) that enables robots to reason with visual contextual information toward achieving long-term goals under uncertainty. SARP constructs scene graphs, a factored representation of objects and their relations, using images captured from different positions, and reasons with them to enable context-aware robot planning under partial observability. Experiments have been conducted using multiple 3D environments in simulation, and a dataset collected by a real robot. In comparison to standard robot planning and scene analysis methods, in a target search domain, SARP improves both efficiency and accuracy in task completion. Supplementary material can be found at https://tinyurl.com/sarp22
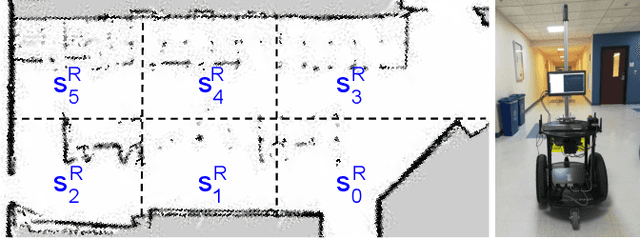
Guided Dyna-Q for Mobile Robot Exploration and Navigation
Apr 23, 2020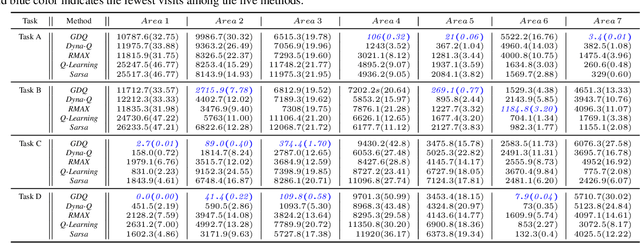
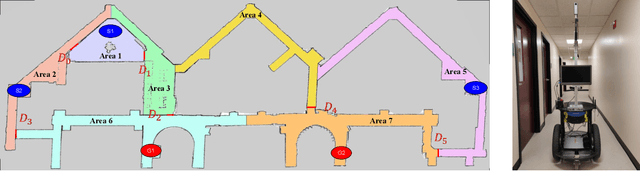
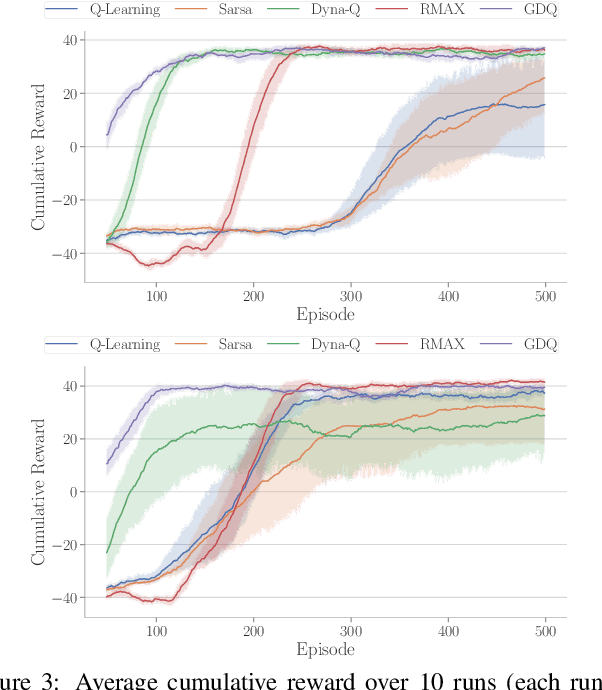
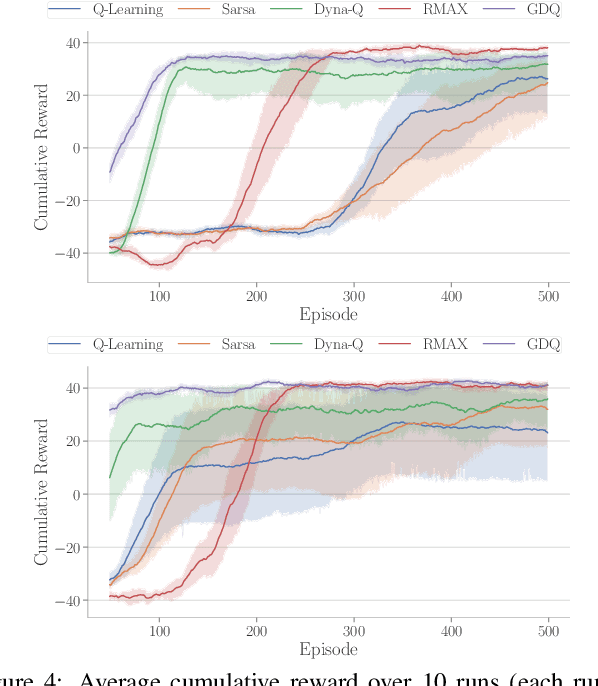
Model-based reinforcement learning (RL) enables an agent to learn world models from trial-and-error experiences toward achieving long-term goals. Automated planning, on the other hand, can be used for accomplishing tasks through reasoning with declarative action knowledge. Despite their shared goal of completing complex tasks, the development of RL and automated planning has mainly been isolated due to their different modalities of computation. Focusing on improving model-based RL agent's exploration strategy and sample efficiency, we develop Guided Dyna-Q (GDQ) to enable RL agents to reason with action knowledge to avoid exploring less-relevant states toward more efficient task accomplishment. GDQ has been evaluated in simulation and using a mobile robot conducting navigation tasks in an office environment. Results show that GDQ reduces the effort in exploration while improving the quality of learned policies.
Tractable Approximate Gaussian Inference for Bayesian Neural Networks
Apr 20, 2020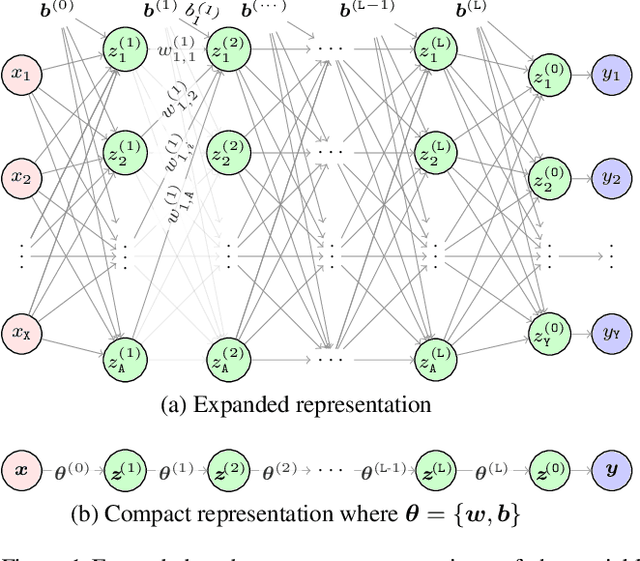
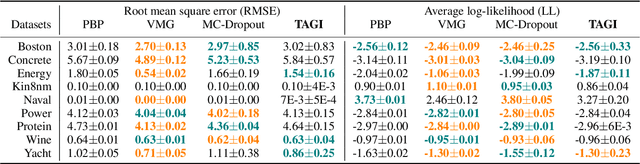
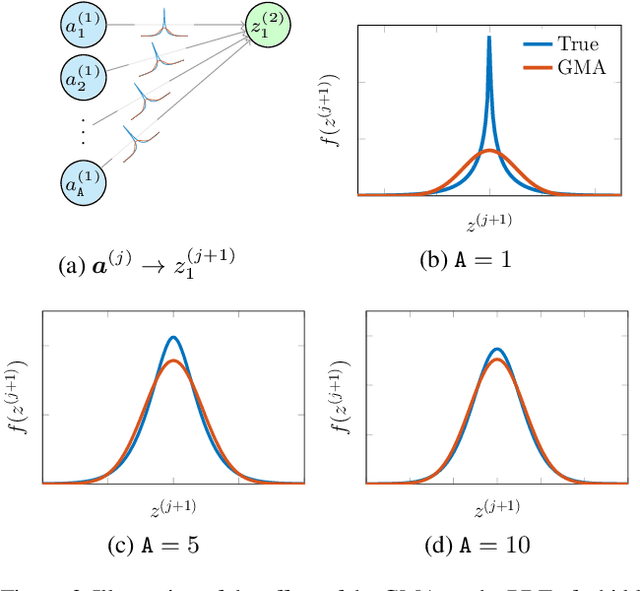

In this paper, we propose an analytical method allowing for tractable approximate Gaussian inference (TAGI) in Bayesian neural networks. The method enables: (1) the analytical inference of the posterior mean vector and diagonal covariance matrix for weights and bias, (2) the end-to-end treatment of uncertainty from the input layer to the output, and (3) the online inference of model parameters using a single observation at a time. The method proposed has a computational complexity of O(n) with respect to the number of parameters n, and the tests performed on regression and classification benchmarks confirm that, for a same network architecture, it matches the performance of existing methods relying on gradient backpropagation.
Augmenting Knowledge through Statistical, Goal-oriented Human-Robot Dialog
Jul 08, 2019
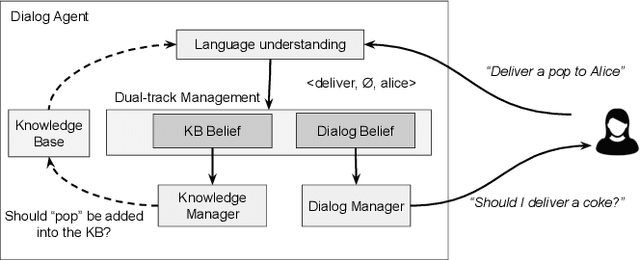
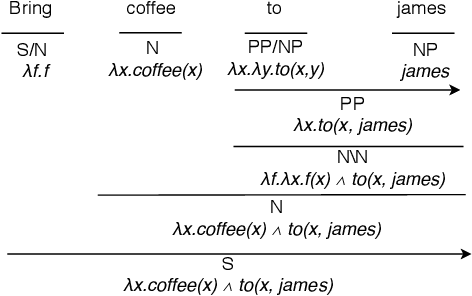
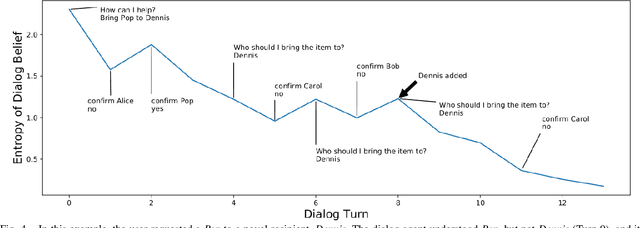
Some robots can interact with humans using natural language, and identify service requests through human-robot dialog. However, few robots are able to improve their language capabilities from this experience. In this paper, we develop a dialog agent for robots that is able to interpret user commands using a semantic parser, while asking clarification questions using a probabilistic dialog manager. This dialog agent is able to augment its knowledge base and improve its language capabilities by learning from dialog experiences, e.g., adding new entities and learning new ways of referring to existing entities. We have extensively evaluated our dialog system in simulation as well as with human participants through MTurk and real-robot platforms. We demonstrate that our dialog agent performs better in efficiency and accuracy in comparison to baseline learning agents. Demo video can be found at https://youtu.be/DFB3jbHBqYE
Robot Sequential Decision Making using LSTM-based Learning and Logical-probabilistic Reasoning
Jan 16, 2019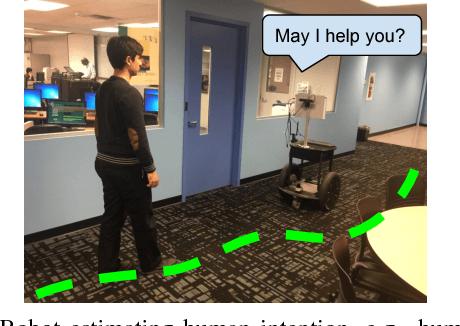

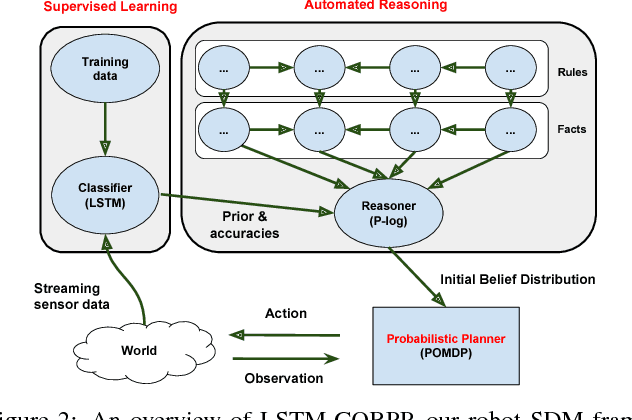
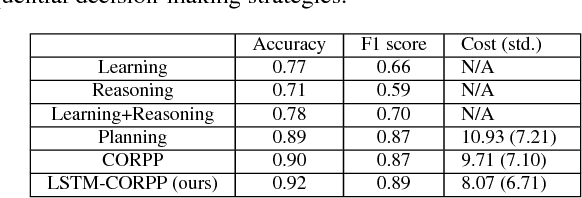
Sequential decision-making (SDM) plays a key role in intelligent robotics, and can be realized in very different ways, such as supervised learning, automated reasoning, and probabilistic planning. The three families of methods follow different assumptions and have different (dis)advantages. In this work, we aim at a robot SDM framework that exploits the complementary features of learning, reasoning, and planning. We utilize long short-term memory (LSTM), for passive state estimation with streaming sensor data, and commonsense reasoning and probabilistic planning (CORPP) for active information collection and task accomplishment. In experiments, a mobile robot is tasked with estimating human intentions using their motion trajectories, declarative contextual knowledge, and human-robot interaction (dialog-based and motion-based). Results suggest that our framework performs better than its no-learning and no-reasoning versions in a real-world office environment.