 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenIPDM: A Probabilistic Framework for Estimating the Deterioration and Effect of Interventions on Bridges
Jan 20, 2022
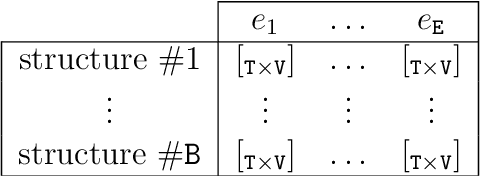


This paper describes OpenIPDM software for modelling the deterioration process of infrastructures using network-scale visual inspection data. In addition to the deterioration state estimates, OpenIPDM provides functions for quantifying the effect of interventions, estimating the service life of an intervention, and generating synthetic data for verification purposes. Each of the aforementioned functions are accessible by an interactive graphical user interface. OpenIPDM is designed based on the research work done on a network of bridges in Quebec province, so that the concepts presented in the software have been validated for applications in a real-world context. In addition, this software provides foundations for future developments in the subject area of modelling the deterioration as well as intervention planning.
Analytically Tractable Hidden-States Inference in Bayesian Neural Networks
Jul 08, 2021



With few exceptions, neural networks have been relying on backpropagation and gradient descent as the inference engine in order to learn the model parameters, because the closed-form Bayesian inference for neural networks has been considered to be intractable. In this paper, we show how we can leverage the tractable approximate Gaussian inference's (TAGI) capabilities to infer hidden states, rather than only using it for inferring the network's parameters. One novel aspect it allows is to infer hidden states through the imposition of constraints designed to achieve specific objectives, as illustrated through three examples: (1) the generation of adversarial-attack examples, (2) the usage of a neural network as a black-box optimization method, and (3) the application of inference on continuous-action reinforcement learning. These applications showcase how tasks that were previously reserved to gradient-based optimization approaches can now be approached with analytically tractable inference
Analytically Tractable Bayesian Deep Q-Learning
Jun 21, 2021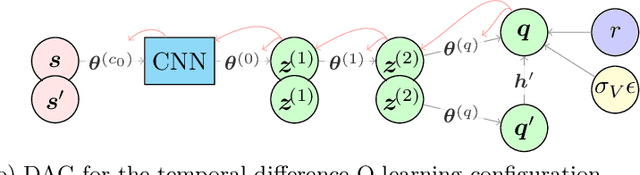


Reinforcement learning (RL) has gained increasing interest since the demonstration it was able to reach human performance on video game benchmarks using deep Q-learning (DQN). The current consensus for training neural networks on such complex environments is to rely on gradient-based optimization. Although alternative Bayesian deep learning methods exist, most of them still rely on gradient-based optimization, and they typically do not scale on benchmarks such as the Atari game environment. Moreover none of these approaches allow performing the analytical inference for the weights and biases defining the neural network. In this paper, we present how we can adapt the temporal difference Q-learning framework to make it compatible with the tractable approximate Gaussian inference (TAGI), which allows learning the parameters of a neural network using a closed-form analytical method. Throughout the experiments with on- and off-policy reinforcement learning approaches, we demonstrate that TAGI can reach a performance comparable to backpropagation-trained networks while using fewer hyperparameters, and without relying on gradient-based optimization.
Analytically Tractable Inference in Deep Neural Networks
Mar 09, 2021

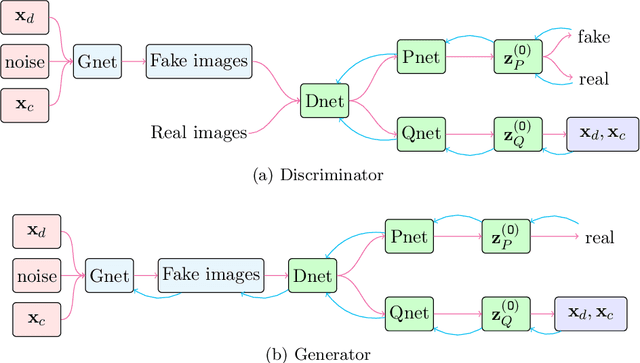
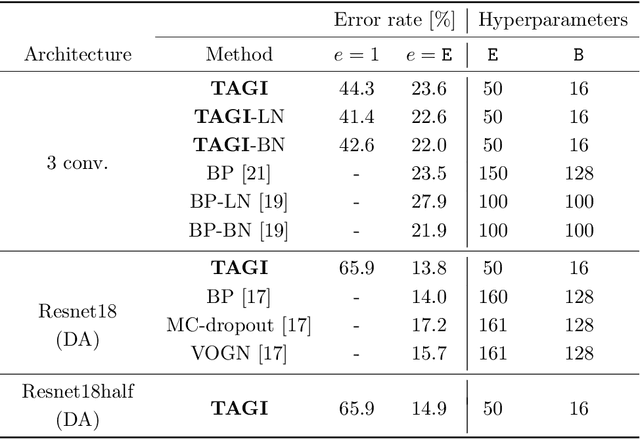
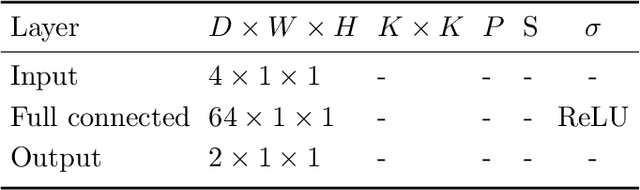
Since its inception, deep learning has been overwhelmingly reliant on backpropagation and gradient-based optimization algorithms in order to learn weight and bias parameter values. Tractable Approximate Gaussian Inference (TAGI) algorithm was shown to be a viable and scalable alternative to backpropagation for shallow fully-connected neural networks. In this paper, we are demonstrating how TAGI matches or exceeds the performance of backpropagation, for training classic deep neural network architectures. Although TAGI's computational efficiency is still below that of deterministic approaches relying on backpropagation, it outperforms them on classification tasks and matches their performance for information maximizing generative adversarial networks while using smaller architectures trained with fewer epochs.
Tractable Approximate Gaussian Inference for Bayesian Neural Networks
Apr 20, 2020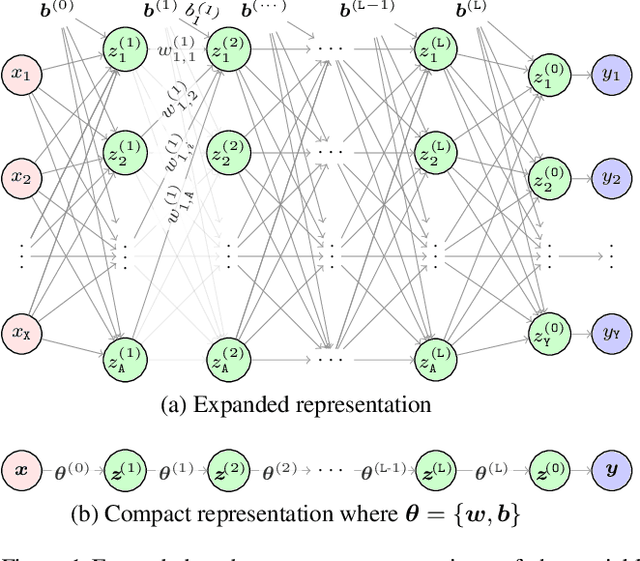
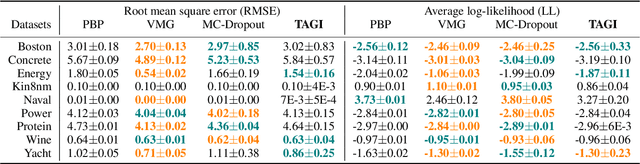
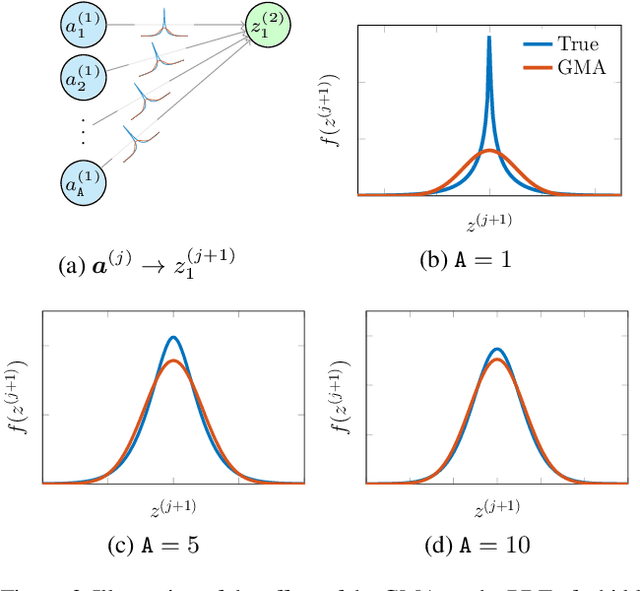

In this paper, we propose an analytical method allowing for tractable approximate Gaussian inference (TAGI) in Bayesian neural networks. The method enables: (1) the analytical inference of the posterior mean vector and diagonal covariance matrix for weights and bias, (2) the end-to-end treatment of uncertainty from the input layer to the output, and (3) the online inference of model parameters using a single observation at a time. The method proposed has a computational complexity of O(n) with respect to the number of parameters n, and the tests performed on regression and classification benchmarks confirm that, for a same network architecture, it matches the performance of existing methods relying on gradient backpropagation.
The Nataf-Beta Random Field Classifier: An Extension of the Beta Conjugate Prior to Classification Problems
Apr 17, 2015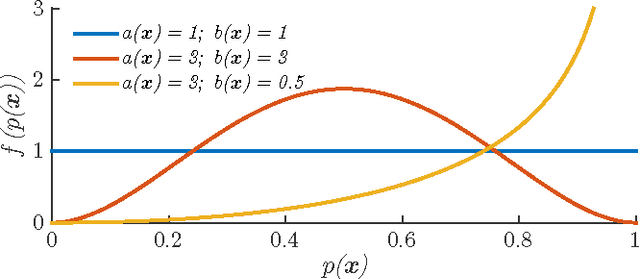


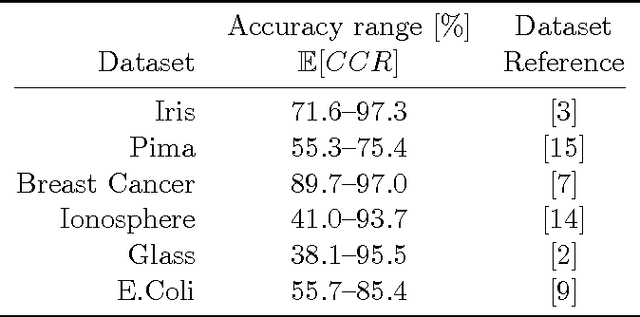
This paper presents the Nataf-Beta Random Field Classifier, a discriminative approach that extends the applicability of the Beta conjugate prior to classification problems. The approach's key feature is to model the probability of a class conditional on attribute values as a random field whose marginals are Beta distributed, and where the parameters of marginals are themselves described by random fields. Although the classification accuracy of the approach proposed does not statistically outperform the best accuracies reported in the literature, it ranks among the top tier for the six benchmark datasets tested. The Nataf-Beta Random Field Classifier is suited as a general purpose classification approach for real-continuous and real-integer attribute value problems.