 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable LLM-based Table Question Answering
Dec 16, 2024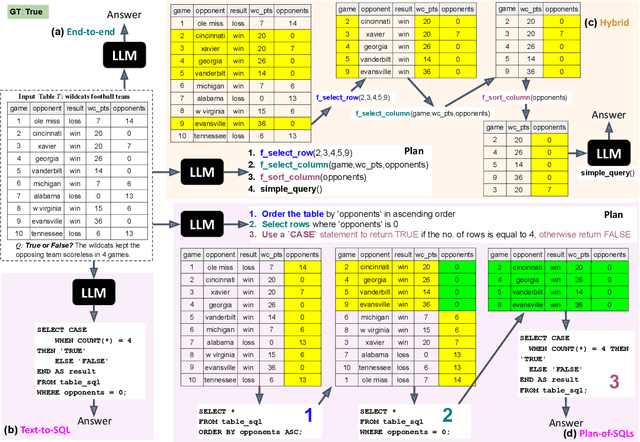

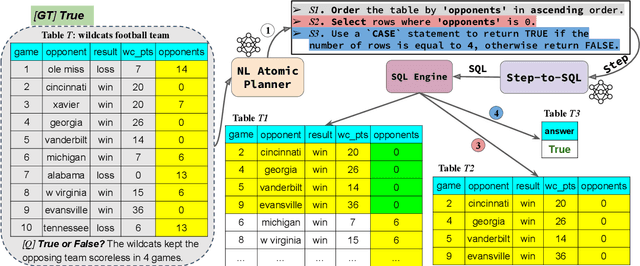
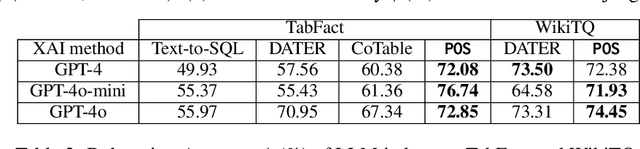
Interpretability for Table Question Answering (Table QA) is critical, particularly in high-stakes industries like finance or healthcare. Although recent approaches using Large Language Models (LLMs) have significantly improved Table QA performance, their explanations for how the answers are generated are ambiguous. To fill this gap, we introduce Plan-of-SQLs ( or POS), an interpretable, effective, and efficient approach to Table QA that answers an input query solely with SQL executions. Through qualitative and quantitative evaluations with human and LLM judges, we show that POS is most preferred among explanation methods, helps human users understand model decision boundaries, and facilitates model success and error identification. Furthermore, when evaluated in standard benchmarks (TabFact, WikiTQ, and FetaQA), POS achieves competitive or superior accuracy compared to existing methods, while maintaining greater efficiency by requiring significantly fewer LLM calls and database queries.
Responsive Regulation of Dynamic UAV Communication Networks Based on Deep Reinforcement Learning
Aug 25, 2021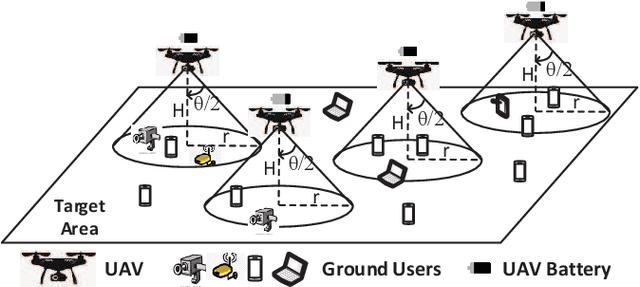
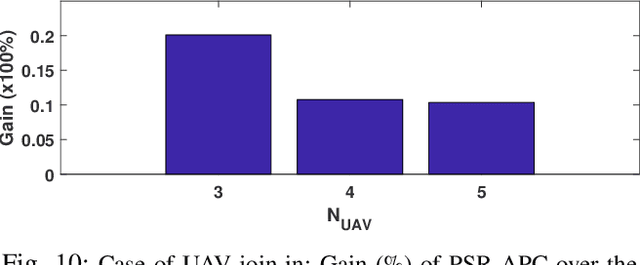
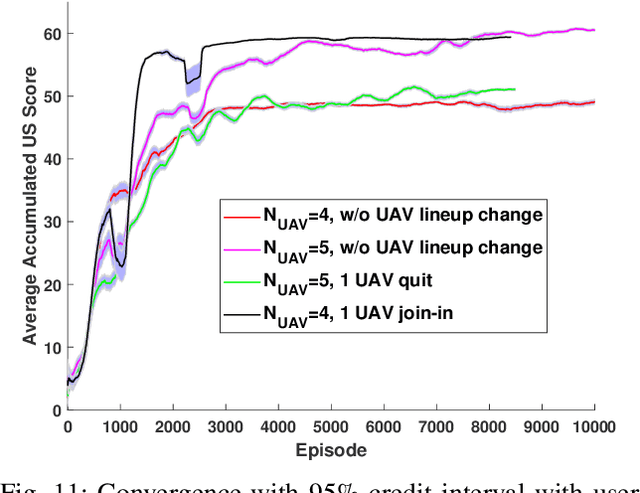
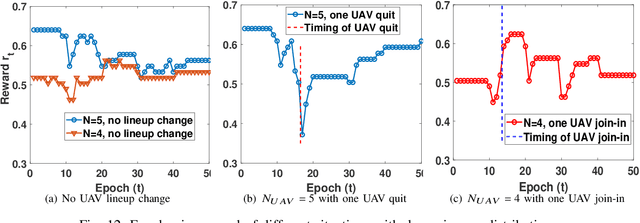
In this chapter, the regulation of Unmanned Aerial Vehicle (UAV) communication network is investigated in the presence of dynamic changes in the UAV lineup and user distribution. We target an optimal UAV control policy which is capable of identifying the upcoming change in the UAV lineup (quit or join-in) or user distribution, and proactively relocating the UAVs ahead of the change rather than passively dispatching the UAVs after the change. Specifically, a deep reinforcement learning (DRL)-based UAV control framework is developed to maximize the accumulated user satisfaction (US) score for a given time horizon which is able to handle the change in both the UAV lineup and user distribution. The framework accommodates the changed dimension of the state-action space before and after the UAV lineup change by deliberate state transition design. In addition, to handle the continuous state and action space, deep deterministic policy gradient (DDPG) algorithm, which is an actor-critic based DRL, is exploited. Furthermore, to promote the learning exploration around the timing of the change, the original DDPG is adapted into an asynchronous parallel computing (APC) structure which leads to a better training performance in both the critic and actor networks. Finally, extensive simulations are conducted to validate the convergence of the proposed learning approach, and demonstrate its capability in jointly handling the dynamics in UAV lineup and user distribution as well as its superiority over a passive reaction method.
Analytically Tractable Bayesian Deep Q-Learning
Jun 21, 2021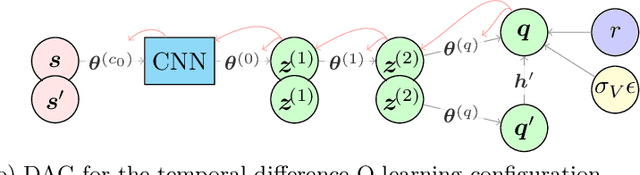


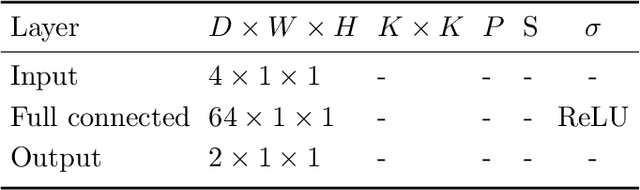
Reinforcement learning (RL) has gained increasing interest since the demonstration it was able to reach human performance on video game benchmarks using deep Q-learning (DQN). The current consensus for training neural networks on such complex environments is to rely on gradient-based optimization. Although alternative Bayesian deep learning methods exist, most of them still rely on gradient-based optimization, and they typically do not scale on benchmarks such as the Atari game environment. Moreover none of these approaches allow performing the analytical inference for the weights and biases defining the neural network. In this paper, we present how we can adapt the temporal difference Q-learning framework to make it compatible with the tractable approximate Gaussian inference (TAGI), which allows learning the parameters of a neural network using a closed-form analytical method. Throughout the experiments with on- and off-policy reinforcement learning approaches, we demonstrate that TAGI can reach a performance comparable to backpropagation-trained networks while using fewer hyperparameters, and without relying on gradient-based optimization.