 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecting Secure AI Agents: Perspectives on System-Level Defenses Against Indirect Prompt Injection Attacks
Mar 31, 2026AI agents, predominantly powered by large language models (LLMs), are vulnerable to indirect prompt injection, in which malicious instructions embedded in untrusted data can trigger dangerous agent actions. This position paper discusses our vision for system-level defenses against indirect prompt injection attacks. We articulate three positions: (1) dynamic replanning and security policy updates are often necessary for dynamic tasks and realistic environments; (2) certain context-dependent security decisions would still require LLMs (or other learned models), but should only be made within system designs that strictly constrain what the model can observe and decide; (3) in inherently ambiguous cases, personalization and human interaction should be treated as core design considerations. In addition to our main positions, we discuss limitations of existing benchmarks that can create a false sense of utility and security. We also highlight the value of system-level defenses, which serve as the skeleton of agentic systems by structuring and controlling agent behaviors, integrating rule-based and model-based security checks, and enabling more targeted research on model robustness and human interaction.
SideQuest: Model-Driven KV Cache Management for Long-Horizon Agentic Reasoning
Feb 26, 2026Long-running agentic tasks, such as deep research, require multi-hop reasoning over information distributed across multiple webpages and documents. In such tasks, the LLM context is dominated by tokens from external retrieval, causing memory usage to grow rapidly and limiting decode performance. While several KV cache compression techniques exist for long-context inputs, we find that existing heuristics fail to support multi-step reasoning models effectively. We address this challenge with SideQuest -- a novel approach that leverages the Large Reasoning Model (LRM) itself to perform KV cache compression by reasoning about the usefulness of tokens in its context. To prevent the tokens associated with this management process from polluting the model's memory, we frame KV cache compression as an auxiliary task executed in parallel to the main reasoning task. Our evaluations, using a model trained with just 215 samples, show that SideQuest reduces peak token usage by up to 65% on agentic tasks with minimal degradation in accuracy, outperforming heuristic-based KV cache compression techniques.
ReasoningBomb: A Stealthy Denial-of-Service Attack by Inducing Pathologically Long Reasoning in Large Reasoning Models
Jan 29, 2026Large reasoning models (LRMs) extend large language models with explicit multi-step reasoning traces, but this capability introduces a new class of prompt-induced inference-time denial-of-service (PI-DoS) attacks that exploit the high computational cost of reasoning. We first formalize inference cost for LRMs and define PI-DoS, then prove that any practical PI-DoS attack should satisfy three properties: (1) a high amplification ratio, where each query induces a disproportionately long reasoning trace relative to its own length; (ii) stealthiness, in which prompts and responses remain on the natural language manifold and evade distribution shift detectors; and (iii) optimizability, in which the attack supports efficient optimization without being slowed by its own success. Under this framework, we present ReasoningBomb, a reinforcement-learning-based PI-DoS framework that is guided by a constant-time surrogate reward and trains a large reasoning-model attacker to generate short natural prompts that drive victim LRMs into pathologically long and often effectively non-terminating reasoning. Across seven open-source models (including LLMs and LRMs) and three commercial LRMs, ReasoningBomb induces 18,759 completion tokens on average and 19,263 reasoning tokens on average across reasoning models. It outperforms the the runner-up baseline by 35% in completion tokens and 38% in reasoning tokens, while inducing 6-7x more tokens than benign queries and achieving 286.7x input-to-output amplification ratio averaged across all samples. Additionally, our method achieves 99.8% bypass rate on input-based detection, 98.7% on output-based detection, and 98.4% against strict dual-stage joint detection.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Stronger Enforcement of Instruction Hierarchy via Augmented Intermediate Representations
May 25, 2025
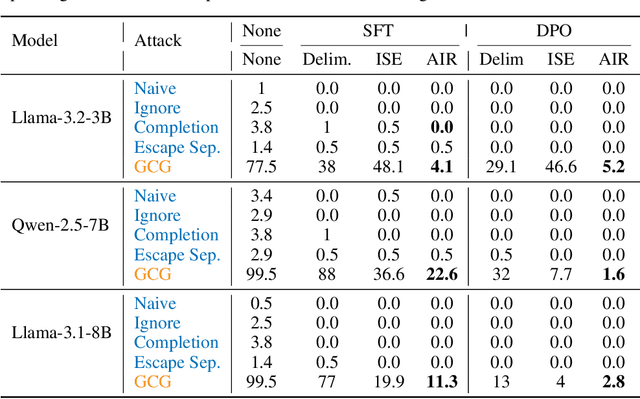
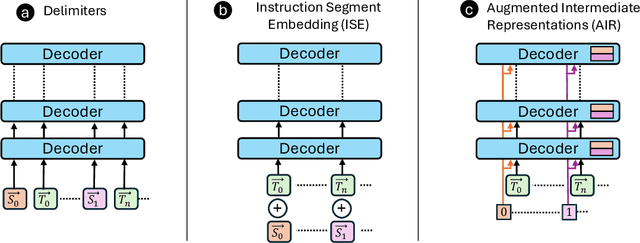
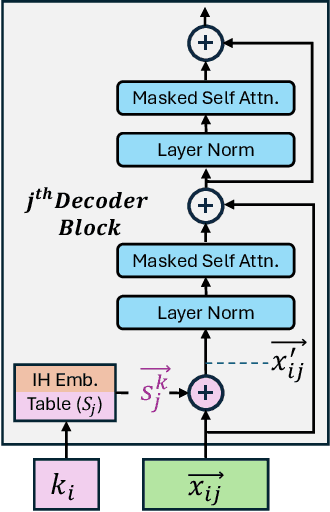
Prompt injection attacks are a critical security vulnerability in large language models (LLMs), allowing attackers to hijack model behavior by injecting malicious instructions within the input context. Recent defense mechanisms have leveraged an Instruction Hierarchy (IH) Signal, often implemented through special delimiter tokens or additive embeddings to denote the privilege level of input tokens. However, these prior works typically inject the IH signal exclusively at the initial input layer, which we hypothesize limits its ability to effectively distinguish the privilege levels of tokens as it propagates through the different layers of the model. To overcome this limitation, we introduce a novel approach that injects the IH signal into the intermediate token representations within the network. Our method augments these representations with layer-specific trainable embeddings that encode the privilege information. Our evaluations across multiple models and training methods reveal that our proposal yields between $1.6\times$ and $9.2\times$ reduction in attack success rate on gradient-based prompt injection attacks compared to state-of-the-art methods, without significantly degrading the model's utility.
Interpretable LLM-based Table Question Answering
Dec 16, 2024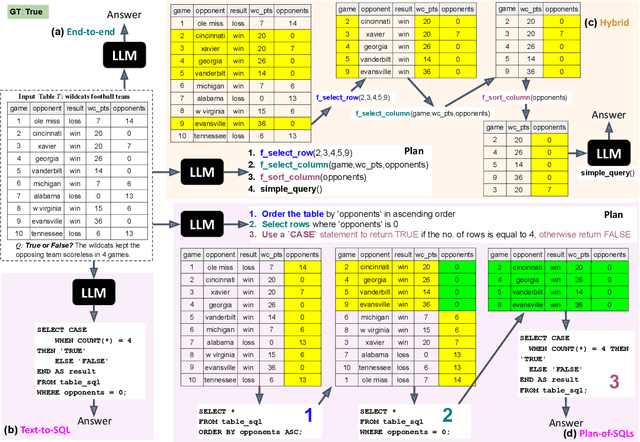

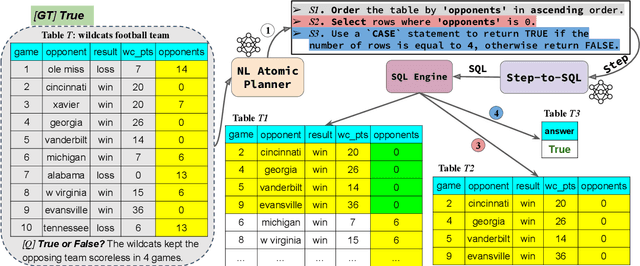
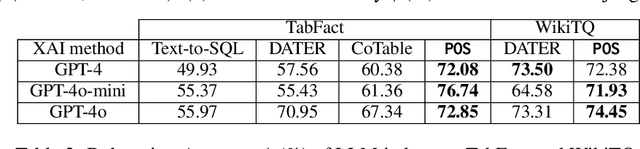
Interpretability for Table Question Answering (Table QA) is critical, particularly in high-stakes industries like finance or healthcare. Although recent approaches using Large Language Models (LLMs) have significantly improved Table QA performance, their explanations for how the answers are generated are ambiguous. To fill this gap, we introduce Plan-of-SQLs ( or POS), an interpretable, effective, and efficient approach to Table QA that answers an input query solely with SQL executions. Through qualitative and quantitative evaluations with human and LLM judges, we show that POS is most preferred among explanation methods, helps human users understand model decision boundaries, and facilitates model success and error identification. Furthermore, when evaluated in standard benchmarks (TabFact, WikiTQ, and FetaQA), POS achieves competitive or superior accuracy compared to existing methods, while maintaining greater efficiency by requiring significantly fewer LLM calls and database queries.
Progressive Inference: Explaining Decoder-Only Sequence Classification Models Using Intermediate Predictions
Jun 03, 2024



This paper proposes Progressive Inference - a framework to compute input attributions to explain the predictions of decoder-only sequence classification models. Our work is based on the insight that the classification head of a decoder-only Transformer model can be used to make intermediate predictions by evaluating them at different points in the input sequence. Due to the causal attention mechanism, these intermediate predictions only depend on the tokens seen before the inference point, allowing us to obtain the model's prediction on a masked input sub-sequence, with negligible computational overheads. We develop two methods to provide sub-sequence level attributions using this insight. First, we propose Single Pass-Progressive Inference (SP-PI), which computes attributions by taking the difference between consecutive intermediate predictions. Second, we exploit a connection with Kernel SHAP to develop Multi Pass-Progressive Inference (MP-PI). MP-PI uses intermediate predictions from multiple masked versions of the input to compute higher quality attributions. Our studies on a diverse set of models trained on text classification tasks show that SP-PI and MP-PI provide significantly better attributions compared to prior work.
Privacy-Preserving Algorithmic Recourse
Nov 23, 2023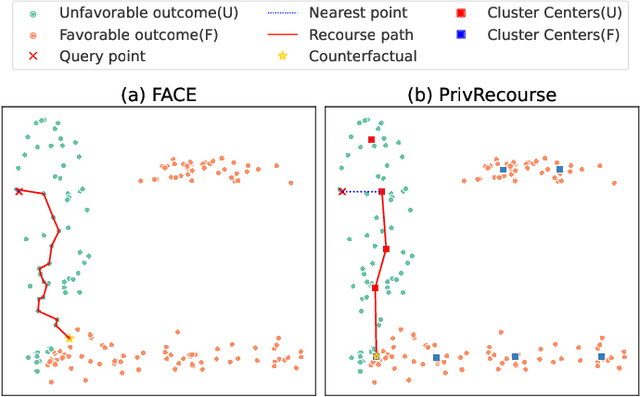

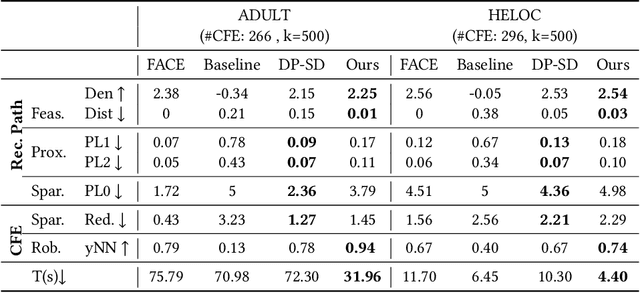
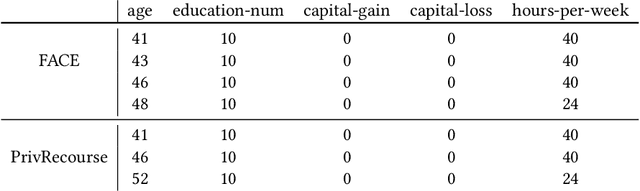
When individuals are subject to adverse outcomes from machine learning models, providing a recourse path to help achieve a positive outcome is desirable. Recent work has shown that counterfactual explanations - which can be used as a means of single-step recourse - are vulnerable to privacy issues, putting an individuals' privacy at risk. Providing a sequential multi-step path for recourse can amplify this risk. Furthermore, simply adding noise to recourse paths found from existing methods can impact the realism and actionability of the path for an end-user. In this work, we address privacy issues when generating realistic recourse paths based on instance-based counterfactual explanations, and provide PrivRecourse: an end-to-end privacy preserving pipeline that can provide realistic recourse paths. PrivRecourse uses differentially private (DP) clustering to represent non-overlapping subsets of the private dataset. These DP cluster centers are then used to generate recourse paths by forming a graph with cluster centers as the nodes, so that we can generate realistic - feasible and actionable - recourse paths. We empirically evaluate our approach on finance datasets and compare it to simply adding noise to data instances, and to using DP synthetic data, to generate the graph. We observe that PrivRecourse can provide paths that are private and realistic.
SHAP@k:Efficient and Probably Approximately Correct (PAC) Identification of Top-k Features
Jul 10, 2023


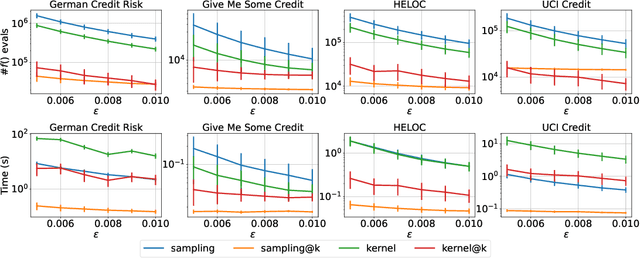
The SHAP framework provides a principled method to explain the predictions of a model by computing feature importance. Motivated by applications in finance, we introduce the Top-k Identification Problem (TkIP), where the objective is to identify the k features with the highest SHAP values. While any method to compute SHAP values with uncertainty estimates (such as KernelSHAP and SamplingSHAP) can be trivially adapted to solve TkIP, doing so is highly sample inefficient. The goal of our work is to improve the sample efficiency of existing methods in the context of solving TkIP. Our key insight is that TkIP can be framed as an Explore-m problem--a well-studied problem related to multi-armed bandits (MAB). This connection enables us to improve sample efficiency by leveraging two techniques from the MAB literature: (1) a better stopping-condition (to stop sampling) that identifies when PAC (Probably Approximately Correct) guarantees have been met and (2) a greedy sampling scheme that judiciously allocates samples between different features. By adopting these methods we develop KernelSHAP@k and SamplingSHAP@k to efficiently solve TkIP, offering an average improvement of $5\times$ in sample-efficiency and runtime across most common credit related datasets.