 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reinforcement Learning for Exploration of Speculative Execution Vulnerabilities
Feb 24, 2025Speculative attacks such as Spectre can leak secret information without being discovered by the operating system. Speculative execution vulnerabilities are finicky and deep in the sense that to exploit them, it requires intensive manual labor and intimate knowledge of the hardware. In this paper, we introduce SpecRL, a framework that utilizes reinforcement learning to find speculative execution leaks in post-silicon (black box) microprocessors.
Unlocking Visual Secrets: Inverting Features with Diffusion Priors for Image Reconstruction
Dec 11, 2024Inverting visual representations within deep neural networks (DNNs) presents a challenging and important problem in the field of security and privacy for deep learning. The main goal is to invert the features of an unidentified target image generated by a pre-trained DNN, aiming to reconstruct the original image. Feature inversion holds particular significance in understanding the privacy leakage inherent in contemporary split DNN execution techniques, as well as in various applications based on the extracted DNN features. In this paper, we explore the use of diffusion models, a promising technique for image synthesis, to enhance feature inversion quality. We also investigate the potential of incorporating alternative forms of prior knowledge, such as textual prompts and cross-frame temporal correlations, to further improve the quality of inverted features. Our findings reveal that diffusion models can effectively leverage hidden information from the DNN features, resulting in superior reconstruction performance compared to previous methods. This research offers valuable insights into how diffusion models can enhance privacy and security within applications that are reliant on DNN features.
FATH: Authentication-based Test-time Defense against Indirect Prompt Injection Attacks
Oct 28, 2024



Large language models (LLMs) have been widely deployed as the backbone with additional tools and text information for real-world applications. However, integrating external information into LLM-integrated applications raises significant security concerns. Among these, prompt injection attacks are particularly threatening, where malicious instructions injected in the external text information can exploit LLMs to generate answers as the attackers desire. While both training-time and test-time defense methods have been developed to mitigate such attacks, the unaffordable training costs associated with training-time methods and the limited effectiveness of existing test-time methods make them impractical. This paper introduces a novel test-time defense strategy, named Formatting AuThentication with Hash-based tags (FATH). Unlike existing approaches that prevent LLMs from answering additional instructions in external text, our method implements an authentication system, requiring LLMs to answer all received instructions with a security policy and selectively filter out responses to user instructions as the final output. To achieve this, we utilize hash-based authentication tags to label each response, facilitating accurate identification of responses according to the user's instructions and improving the robustness against adaptive attacks. Comprehensive experiments demonstrate that our defense method can effectively defend against indirect prompt injection attacks, achieving state-of-the-art performance under Llama3 and GPT3.5 models across various attack methods. Our code is released at: https://github.com/Jayfeather1024/FATH
AutoDAN-Turbo: A Lifelong Agent for Strategy Self-Exploration to Jailbreak LLMs
Oct 14, 2024



In this paper, we propose AutoDAN-Turbo, a black-box jailbreak method that can automatically discover as many jailbreak strategies as possible from scratch, without any human intervention or predefined scopes (e.g., specified candidate strategies), and use them for red-teaming. As a result, AutoDAN-Turbo can significantly outperform baseline methods, achieving a 74.3% higher average attack success rate on public benchmarks. Notably, AutoDAN-Turbo achieves an 88.5 attack success rate on GPT-4-1106-turbo. In addition, AutoDAN-Turbo is a unified framework that can incorporate existing human-designed jailbreak strategies in a plug-and-play manner. By integrating human-designed strategies, AutoDAN-Turbo can even achieve a higher attack success rate of 93.4 on GPT-4-1106-turbo.
GPU-based Private Information Retrieval for On-Device Machine Learning Inference
Jan 27, 2023



On-device machine learning (ML) inference can enable the use of private user data on user devices without remote servers. However, a pure on-device solution to private ML inference is impractical for many applications that rely on embedding tables that are too large to be stored on-device. To overcome this barrier, we propose the use of private information retrieval (PIR) to efficiently and privately retrieve embeddings from servers without sharing any private information during on-device ML inference. As off-the-shelf PIR algorithms are usually too computationally intensive to directly use for latency-sensitive inference tasks, we 1) develop a novel algorithm for accelerating PIR on GPUs, and 2) co-design PIR with the downstream ML application to obtain further speedup. Our GPU acceleration strategy improves system throughput by more than $20 \times$ over an optimized CPU PIR implementation, and our co-design techniques obtain over $5 \times$ additional throughput improvement at fixed model quality. Together, on various on-device ML applications such as recommendation and language modeling, our system on a single V100 GPU can serve up to $100,000$ queries per second -- a $>100 \times$ throughput improvement over a naively implemented system -- while maintaining model accuracy, and limiting inference communication and response latency to within $300$KB and $<100$ms respectively.
Measuring and Controlling Split Layer Privacy Leakage Using Fisher Information
Sep 21, 2022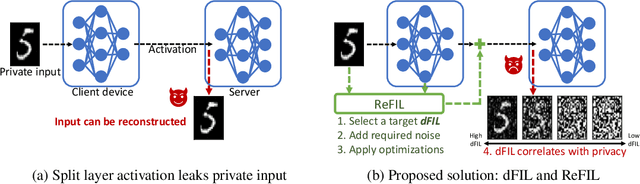
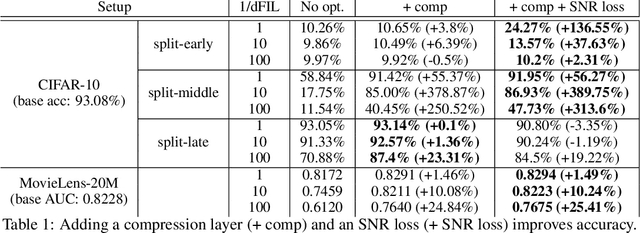
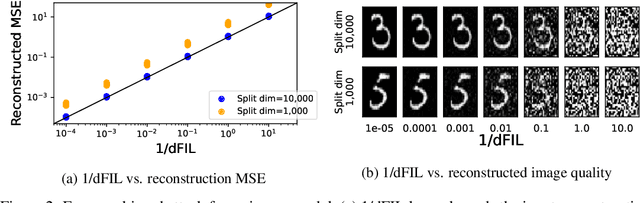
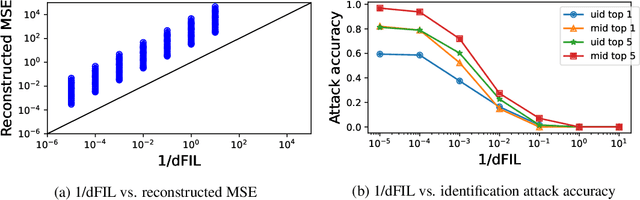
Split learning and inference propose to run training/inference of a large model that is split across client devices and the cloud. However, such a model splitting imposes privacy concerns, because the activation flowing through the split layer may leak information about the clients' private input data. There is currently no good way to quantify how much private information is being leaked through the split layer, nor a good way to improve privacy up to the desired level. In this work, we propose to use Fisher information as a privacy metric to measure and control the information leakage. We show that Fisher information can provide an intuitive understanding of how much private information is leaking through the split layer, in the form of an error bound for an unbiased reconstruction attacker. We then propose a privacy-enhancing technique, ReFIL, that can enforce a user-desired level of Fisher information leakage at the split layer to achieve high privacy, while maintaining reasonable utility.
Sinan: Data-Driven, QoS-Aware Cluster Management for Microservices
May 27, 2021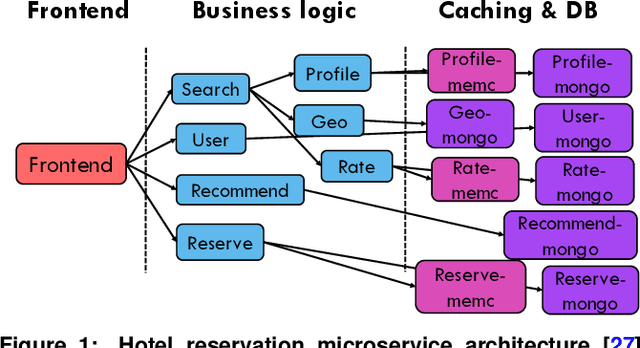
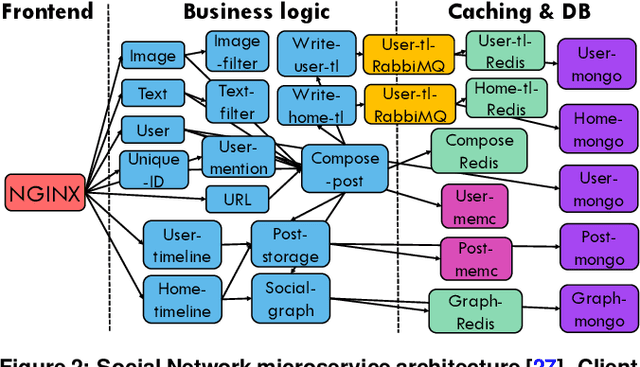

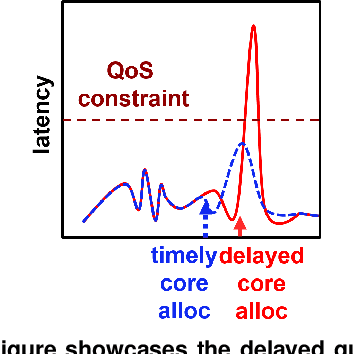
Cloud applications are increasingly shifting from large monolithic services, to large numbers of loosely-coupled, specialized microservices. Despite their advantages in terms of facilitating development, deployment, modularity, and isolation, microservices complicate resource management, as dependencies between them introduce backpressure effects and cascading QoS violations. We present Sinan, a data-driven cluster manager for interactive cloud microservices that is online and QoS-aware. Sinan leverages a set of scalable and validated machine learning models to determine the performance impact of dependencies between microservices, and allocate appropriate resources per tier in a way that preserves the end-to-end tail latency target. We evaluate Sinan both on dedicated local clusters and large-scale deployments on Google Compute Engine (GCE) across representative end-to-end applications built with microservices, such as social networks and hotel reservation sites. We show that Sinan always meets QoS, while also maintaining cluster utilization high, in contrast to prior work which leads to unpredictable performance or sacrifices resource efficiency. Furthermore, the techniques in Sinan are explainable, meaning that cloud operators can yield insights from the ML models on how to better deploy and design their applications to reduce unpredictable performance.