 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying KV Cache Compression for Large Language Models with LeanKV
Dec 04, 2024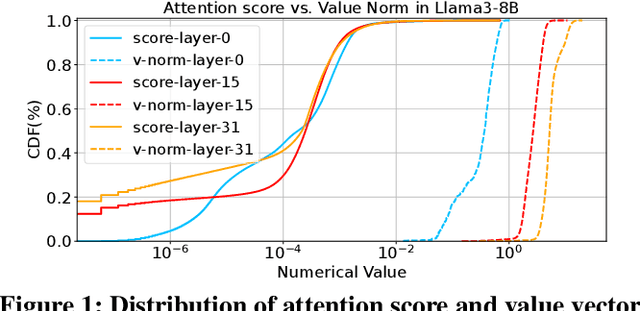
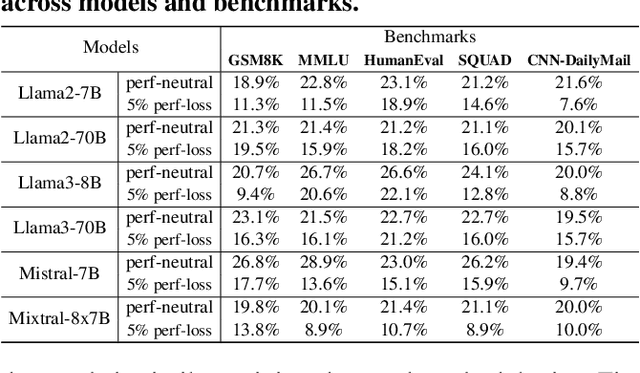
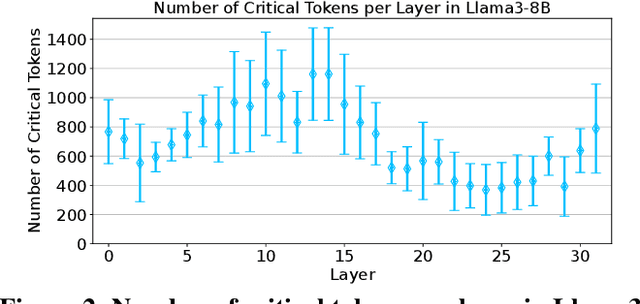
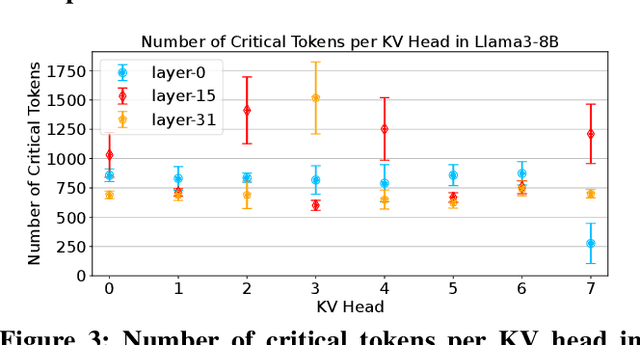
Large language models (LLMs) demonstrate exceptional performance but incur high serving costs due to substantial memory demands, with the key-value (KV) cache being a primary bottleneck. Existing KV cache compression methods, including quantization and pruning, struggle with limitations such as uniform treatment of keys and values and static memory allocation across attention heads. To address these challenges, we introduce LeanKV, a unified KV cache compression framework that enhances LLM serving efficiency without compromising accuracy through three innovations: (1) Hetero-KV quantization, which stores keys at a higher precision than values to reflect their greater impact on attention computations; (2) per-head dynamic sparsity, which allocates memory based on token importance per head and per request; and (3) unified KV compression, integrating mixed-precision quantization and selective pruning to enable a smooth tradeoff between model accuracy and memory efficiency. To efficiently support these techniques, LeanKV introduces systems optimizations including unified paging and on-GPU parallel memory management. Implemented on vLLM, LeanKV compresses the KV cache by $3.0\times$ to $5.0\times$ without accuracy loss and up to $11.0\times$ with under 5% accuracy loss, enhancing throughput by $1.9\times$ to $2.5\times$, and up to $6.9\times$.
ChipExpert: The Open-Source Integrated-Circuit-Design-Specific Large Language Model
Jul 26, 2024The field of integrated circuit (IC) design is highly specialized, presenting significant barriers to entry and research and development challenges. Although large language models (LLMs) have achieved remarkable success in various domains, existing LLMs often fail to meet the specific needs of students, engineers, and researchers. Consequently, the potential of LLMs in the IC design domain remains largely unexplored. To address these issues, we introduce ChipExpert, the first open-source, instructional LLM specifically tailored for the IC design field. ChipExpert is trained on one of the current best open-source base model (Llama-3 8B). The entire training process encompasses several key stages, including data preparation, continue pre-training, instruction-guided supervised fine-tuning, preference alignment, and evaluation. In the data preparation stage, we construct multiple high-quality custom datasets through manual selection and data synthesis techniques. In the subsequent two stages, ChipExpert acquires a vast amount of IC design knowledge and learns how to respond to user queries professionally. ChipExpert also undergoes an alignment phase, using Direct Preference Optimization, to achieve a high standard of ethical performance. Finally, to mitigate the hallucinations of ChipExpert, we have developed a Retrieval-Augmented Generation (RAG) system, based on the IC design knowledge base. We also released the first IC design benchmark ChipICD-Bench, to evaluate the capabilities of LLMs across multiple IC design sub-domains. Through comprehensive experiments conducted on this benchmark, ChipExpert demonstrated a high level of expertise in IC design knowledge Question-and-Answer tasks.
Analytically-Driven Resource Management for Cloud-Native Microservices
Jan 05, 2024



Resource management for cloud-native microservices has attracted a lot of recent attention. Previous work has shown that machine learning (ML)-driven approaches outperform traditional techniques, such as autoscaling, in terms of both SLA maintenance and resource efficiency. However, ML-driven approaches also face challenges including lengthy data collection processes and limited scalability. We present Ursa, a lightweight resource management system for cloud-native microservices that addresses these challenges. Ursa uses an analytical model that decomposes the end-to-end SLA into per-service SLA, and maps per-service SLA to individual resource allocations per microservice tier. To speed up the exploration process and avoid prolonged SLA violations, Ursa explores each microservice individually, and swiftly stops exploration if latency exceeds its SLA. We evaluate Ursa on a set of representative and end-to-end microservice topologies, including a social network, media service and video processing pipeline, each consisting of multiple classes and priorities of requests with different SLAs, and compare it against two representative ML-driven systems, Sinan and Firm. Compared to these ML-driven approaches, Ursa provides significant advantages: It shortens the data collection process by more than 128x, and its control plane is 43x faster than ML-driven approaches. At the same time, Ursa does not sacrifice resource efficiency or SLAs. During online deployment, Ursa reduces the SLA violation rate by 9.0% up to 49.9%, and reduces CPU allocation by up to 86.2% compared to ML-driven approaches.
Sinan: Data-Driven, QoS-Aware Cluster Management for Microservices
May 27, 2021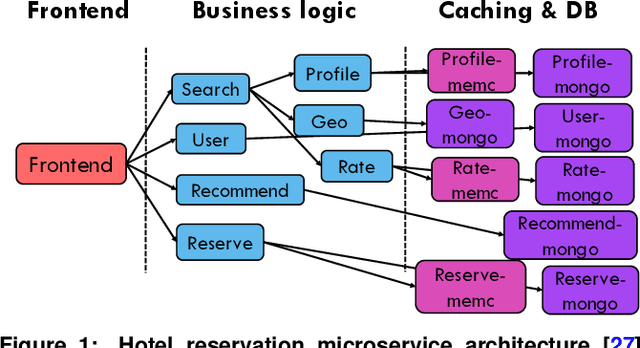
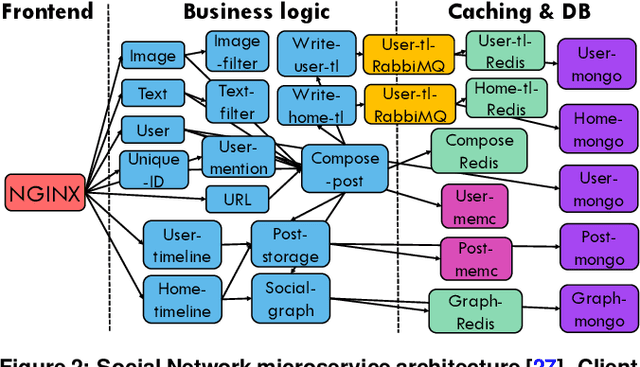

Cloud applications are increasingly shifting from large monolithic services, to large numbers of loosely-coupled, specialized microservices. Despite their advantages in terms of facilitating development, deployment, modularity, and isolation, microservices complicate resource management, as dependencies between them introduce backpressure effects and cascading QoS violations. We present Sinan, a data-driven cluster manager for interactive cloud microservices that is online and QoS-aware. Sinan leverages a set of scalable and validated machine learning models to determine the performance impact of dependencies between microservices, and allocate appropriate resources per tier in a way that preserves the end-to-end tail latency target. We evaluate Sinan both on dedicated local clusters and large-scale deployments on Google Compute Engine (GCE) across representative end-to-end applications built with microservices, such as social networks and hotel reservation sites. We show that Sinan always meets QoS, while also maintaining cluster utilization high, in contrast to prior work which leads to unpredictable performance or sacrifices resource efficiency. Furthermore, the techniques in Sinan are explainable, meaning that cloud operators can yield insights from the ML models on how to better deploy and design their applications to reduce unpredictable performance.
Leveraging Deep Learning to Improve the Performance Predictability of Cloud Microservices
May 02, 2019

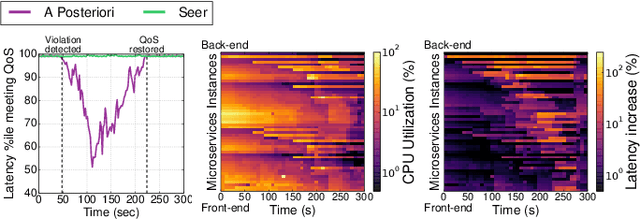

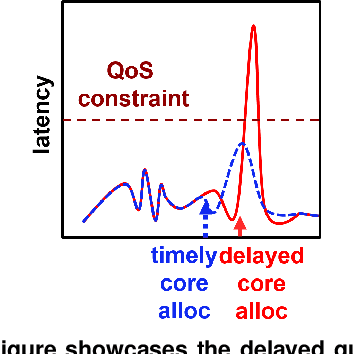
Performance unpredictability is a major roadblock towards cloud adoption, and has performance, cost, and revenue ramifications. Predictable performance is even more critical as cloud services transition from monolithic designs to microservices. Detecting QoS violations after they occur in systems with microservices results in long recovery times, as hotspots propagate and amplify across dependent services. We present Seer, an online cloud performance debugging system that leverages deep learning and the massive amount of tracing data cloud systems collect to learn spatial and temporal patterns that translate to QoS violations. Seer combines lightweight distributed RPC-level tracing, with detailed low-level hardware monitoring to signal an upcoming QoS violation, and diagnose the source of unpredictable performance. Once an imminent QoS violation is detected, Seer notifies the cluster manager to take action to avoid performance degradation altogether. We evaluate Seer both in local clusters, and in large-scale deployments of end-to-end applications built with microservices with hundreds of users. We show that Seer correctly anticipates QoS violations 91% of the time, and avoids the QoS violation to begin with in 84% of cases. Finally, we show that Seer can identify application-level design bugs, and provide insights on how to better architect microservices to achieve predictable performance.