 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying KV Cache Compression for Large Language Models with LeanKV
Paper and Code
Dec 04, 2024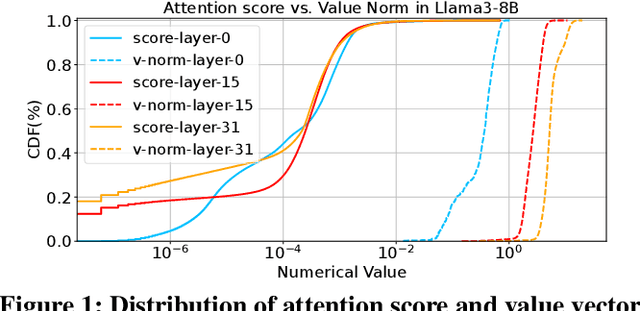
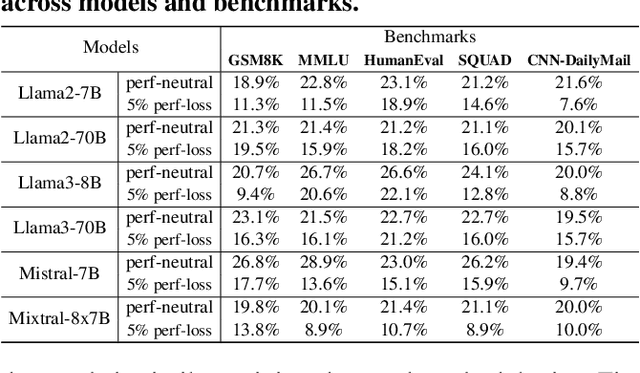
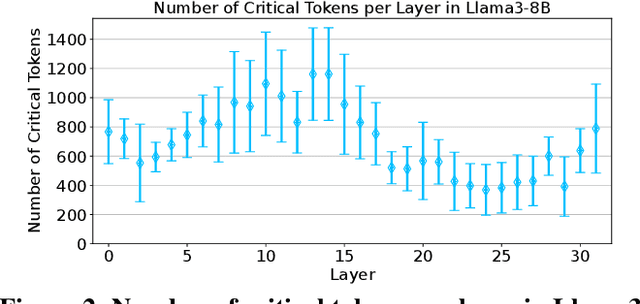
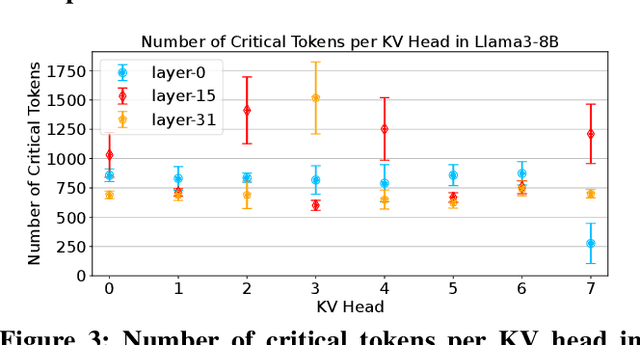
Large language models (LLMs) demonstrate exceptional performance but incur high serving costs due to substantial memory demands, with the key-value (KV) cache being a primary bottleneck. Existing KV cache compression methods, including quantization and pruning, struggle with limitations such as uniform treatment of keys and values and static memory allocation across attention heads. To address these challenges, we introduce LeanKV, a unified KV cache compression framework that enhances LLM serving efficiency without compromising accuracy through three innovations: (1) Hetero-KV quantization, which stores keys at a higher precision than values to reflect their greater impact on attention computations; (2) per-head dynamic sparsity, which allocates memory based on token importance per head and per request; and (3) unified KV compression, integrating mixed-precision quantization and selective pruning to enable a smooth tradeoff between model accuracy and memory efficiency. To efficiently support these techniques, LeanKV introduces systems optimizations including unified paging and on-GPU parallel memory management. Implemented on vLLM, LeanKV compresses the KV cache by $3.0\times$ to $5.0\times$ without accuracy loss and up to $11.0\times$ with under 5% accuracy loss, enhancing throughput by $1.9\times$ to $2.5\times$, and up to $6.9\times$.