 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFM-EAC: Feature Model-based Enhanced Actor-Critic for Multi-Task Control in Dynamic Environments
Dec 17, 2025Model-based reinforcement learning (MBRL) and model-free reinforcement learning (MFRL) evolve along distinct paths but converge in the design of Dyna-Q [1]. However, modern RL methods still struggle with effective transferability across tasks and scenarios. Motivated by this limitation, we propose a generalized algorithm, Feature Model-Based Enhanced Actor-Critic (FM-EAC), that integrates planning, acting, and learning for multi-task control in dynamic environments. FM-EAC combines the strengths of MBRL and MFRL and improves generalizability through the use of novel feature-based models and an enhanced actor-critic framework. Simulations in both urban and agricultural applications demonstrate that FM-EAC consistently outperforms many state-of-the-art MBRL and MFRL methods. More importantly, different sub-networks can be customized within FM-EAC according to user-specific requirements.
Trading Vector Data in Vector Databases
Nov 10, 2025Vector data trading is essential for cross-domain learning with vector databases, yet it remains largely unexplored. We study this problem under online learning, where sellers face uncertain retrieval costs and buyers provide stochastic feedback to posted prices. Three main challenges arise: (1) heterogeneous and partial feedback in configuration learning, (2) variable and complex feedback in pricing learning, and (3) inherent coupling between configuration and pricing decisions. We propose a hierarchical bandit framework that jointly optimizes retrieval configurations and pricing. Stage I employs contextual clustering with confidence-based exploration to learn effective configurations with logarithmic regret. Stage II adopts interval-based price selection with local Taylor approximation to estimate buyer responses and achieve sublinear regret. We establish theoretical guarantees with polynomial time complexity and validate the framework on four real-world datasets, demonstrating consistent improvements in cumulative reward and regret reduction compared with existing methods.
Semantic Caching for Low-Cost LLM Serving: From Offline Learning to Online Adaptation
Aug 12, 2025Large Language Models (LLMs) are revolutionizing how users interact with information systems, yet their high inference cost poses serious scalability and sustainability challenges. Caching inference responses, allowing them to be retrieved without another forward pass through the LLM, has emerged as one possible solution. Traditional exact-match caching, however, overlooks the semantic similarity between queries, leading to unnecessary recomputation. Semantic caching addresses this by retrieving responses based on semantic similarity, but introduces a fundamentally different cache eviction problem: one must account for mismatch costs between incoming queries and cached responses. Moreover, key system parameters, such as query arrival probabilities and serving costs, are often unknown and must be learned over time. Existing semantic caching methods are largely ad-hoc, lacking theoretical foundations and unable to adapt to real-world uncertainty. In this paper, we present a principled, learning-based framework for semantic cache eviction under unknown query and cost distributions. We formulate both offline optimization and online learning variants of the problem, and develop provably efficient algorithms with state-of-the-art guarantees. We also evaluate our framework on a synthetic dataset, showing that our proposed algorithms perform matching or superior performance compared with baselines.
Learning Best Paths in Quantum Networks
Jun 14, 2025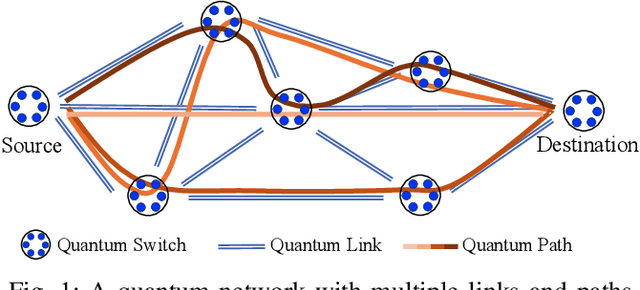



Quantum networks (QNs) transmit delicate quantum information across noisy quantum channels. Crucial applications, like quantum key distribution (QKD) and distributed quantum computation (DQC), rely on efficient quantum information transmission. Learning the best path between a pair of end nodes in a QN is key to enhancing such applications. This paper addresses learning the best path in a QN in the online learning setting. We explore two types of feedback: "link-level" and "path-level". Link-level feedback pertains to QNs with advanced quantum switches that enable link-level benchmarking. Path-level feedback, on the other hand, is associated with basic quantum switches that permit only path-level benchmarking. We introduce two online learning algorithms, BeQuP-Link and BeQuP-Path, to identify the best path using link-level and path-level feedback, respectively. To learn the best path, BeQuP-Link benchmarks the critical links dynamically, while BeQuP-Path relies on a subroutine, transferring path-level observations to estimate link-level parameters in a batch manner. We analyze the quantum resource complexity of these algorithms and demonstrate that both can efficiently and, with high probability, determine the best path. Finally, we perform NetSquid-based simulations and validate that both algorithms accurately and efficiently identify the best path.
Federated In-Context Learning: Iterative Refinement for Improved Answer Quality
Jun 09, 2025For question-answering (QA) tasks, in-context learning (ICL) enables language models to generate responses without modifying their parameters by leveraging examples provided in the input. However, the effectiveness of ICL heavily depends on the availability of high-quality examples, which are often scarce due to data privacy constraints, annotation costs, and distribution disparities. A natural solution is to utilize examples stored on client devices, but existing approaches either require transmitting model parameters - incurring significant communication overhead - or fail to fully exploit local datasets, limiting their effectiveness. To address these challenges, we propose Federated In-Context Learning (Fed-ICL), a general framework that enhances ICL through an iterative, collaborative process. Fed-ICL progressively refines responses by leveraging multi-round interactions between clients and a central server, improving answer quality without the need to transmit model parameters. We establish theoretical guarantees for the convergence of Fed-ICL and conduct extensive experiments on standard QA benchmarks, demonstrating that our proposed approach achieves strong performance while maintaining low communication costs.
A Unified Online-Offline Framework for Co-Branding Campaign Recommendations
May 28, 2025



Co-branding has become a vital strategy for businesses aiming to expand market reach within recommendation systems. However, identifying effective cross-industry partnerships remains challenging due to resource imbalances, uncertain brand willingness, and ever-changing market conditions. In this paper, we provide the first systematic study of this problem and propose a unified online-offline framework to enable co-branding recommendations. Our approach begins by constructing a bipartite graph linking ``initiating'' and ``target'' brands to quantify co-branding probabilities and assess market benefits. During the online learning phase, we dynamically update the graph in response to market feedback, while striking a balance between exploring new collaborations for long-term gains and exploiting established partnerships for immediate benefits. To address the high initial co-branding costs, our framework mitigates redundant exploration, thereby enhancing short-term performance while ensuring sustainable strategic growth. In the offline optimization phase, our framework consolidates the interests of multiple sub-brands under the same parent brand to maximize overall returns, avoid excessive investment in single sub-brands, and reduce unnecessary costs associated with over-prioritizing a single sub-brand. We present a theoretical analysis of our approach, establishing a highly nontrivial sublinear regret bound for online learning in the complex co-branding problem, and enhancing the approximation guarantee for the NP-hard offline budget allocation optimization. Experiments on both synthetic and real-world co-branding datasets demonstrate the practical effectiveness of our framework, with at least 12\% improvement.
Leveraging the Power of Conversations: Optimal Key Term Selection in Conversational Contextual Bandits
May 27, 2025



Conversational recommender systems proactively query users with relevant "key terms" and leverage the feedback to elicit users' preferences for personalized recommendations. Conversational contextual bandits, a prevalent approach in this domain, aim to optimize preference learning by balancing exploitation and exploration. However, several limitations hinder their effectiveness in real-world scenarios. First, existing algorithms employ key term selection strategies with insufficient exploration, often failing to thoroughly probe users' preferences and resulting in suboptimal preference estimation. Second, current algorithms typically rely on deterministic rules to initiate conversations, causing unnecessary interactions when preferences are well-understood and missed opportunities when preferences are uncertain. To address these limitations, we propose three novel algorithms: CLiSK, CLiME, and CLiSK-ME. CLiSK introduces smoothed key term contexts to enhance exploration in preference learning, CLiME adaptively initiates conversations based on preference uncertainty, and CLiSK-ME integrates both techniques. We theoretically prove that all three algorithms achieve a tighter regret upper bound of $O(\sqrt{dT\log{T}})$ with respect to the time horizon $T$, improving upon existing methods. Additionally, we provide a matching lower bound $\Omega(\sqrt{dT})$ for conversational bandits, demonstrating that our algorithms are nearly minimax optimal. Extensive evaluations on both synthetic and real-world datasets show that our approaches achieve at least a 14.6% improvement in cumulative regret.
Offline Clustering of Linear Bandits: Unlocking the Power of Clusters in Data-Limited Environments
May 25, 2025Contextual linear multi-armed bandits are a learning framework for making a sequence of decisions, e.g., advertising recommendations for a sequence of arriving users. Recent works have shown that clustering these users based on the similarity of their learned preferences can significantly accelerate the learning. However, prior work has primarily focused on the online setting, which requires continually collecting user data, ignoring the offline data widely available in many applications. To tackle these limitations, we study the offline clustering of bandits (Off-ClusBand) problem, which studies how to use the offline dataset to learn cluster properties and improve decision-making across multiple users. The key challenge in Off-ClusBand arises from data insufficiency for users: unlike the online case, in the offline case, we have a fixed, limited dataset to work from and thus must determine whether we have enough data to confidently cluster users together. To address this challenge, we propose two algorithms: Off-C$^2$LUB, which we analytically show performs well for arbitrary amounts of user data, and Off-CLUB, which is prone to bias when data is limited but, given sufficient data, matches a theoretical lower bound that we derive for the offline clustered MAB problem. We experimentally validate these results on both real and synthetic datasets.
Fusing Reward and Dueling Feedback in Stochastic Bandits
Apr 22, 2025This paper investigates the fusion of absolute (reward) and relative (dueling) feedback in stochastic bandits, where both feedback types are gathered in each decision round. We derive a regret lower bound, demonstrating that an efficient algorithm may incur only the smaller among the reward and dueling-based regret for each individual arm. We propose two fusion approaches: (1) a simple elimination fusion algorithm that leverages both feedback types to explore all arms and unifies collected information by sharing a common candidate arm set, and (2) a decomposition fusion algorithm that selects the more effective feedback to explore the corresponding arms and randomly assigns one feedback type for exploration and the other for exploitation in each round. The elimination fusion experiences a suboptimal multiplicative term of the number of arms in regret due to the intrinsic suboptimality of dueling elimination. In contrast, the decomposition fusion achieves regret matching the lower bound up to a constant under a common assumption. Extensive experiments confirm the efficacy of our algorithms and theoretical results.
Provable Zero-Shot Generalization in Offline Reinforcement Learning
Mar 11, 2025

In this work, we study offline reinforcement learning (RL) with zero-shot generalization property (ZSG), where the agent has access to an offline dataset including experiences from different environments, and the goal of the agent is to train a policy over the training environments which performs well on test environments without further interaction. Existing work showed that classical offline RL fails to generalize to new, unseen environments. We propose pessimistic empirical risk minimization (PERM) and pessimistic proximal policy optimization (PPPO), which leverage pessimistic policy evaluation to guide policy learning and enhance generalization. We show that both PERM and PPPO are capable of finding a near-optimal policy with ZSG. Our result serves as a first step in understanding the foundation of the generalization phenomenon in offline reinforcement learning.