 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Apr 15, 2025We introduce Kimina-Prover Preview, a large language model that pioneers a novel reasoning-driven exploration paradigm for formal theorem proving, as showcased in this preview release. Trained with a large-scale reinforcement learning pipeline from Qwen2.5-72B, Kimina-Prover demonstrates strong performance in Lean 4 proof generation by employing a structured reasoning pattern we term \textit{formal reasoning pattern}. This approach allows the model to emulate human problem-solving strategies in Lean, iteratively generating and refining proof steps. Kimina-Prover sets a new state-of-the-art on the miniF2F benchmark, reaching 80.7% with pass@8192. Beyond improved benchmark performance, our work yields several key insights: (1) Kimina-Prover exhibits high sample efficiency, delivering strong results even with minimal sampling (pass@1) and scaling effectively with computational budget, stemming from its unique reasoning pattern and RL training; (2) we demonstrate clear performance scaling with model size, a trend previously unobserved for neural theorem provers in formal mathematics; (3) the learned reasoning style, distinct from traditional search algorithms, shows potential to bridge the gap between formal verification and informal mathematical intuition. We open source distilled versions with 1.5B and 7B parameters of Kimina-Prover
Behavior-Regularized Diffusion Policy Optimization for Offline Reinforcement Learning
Feb 07, 2025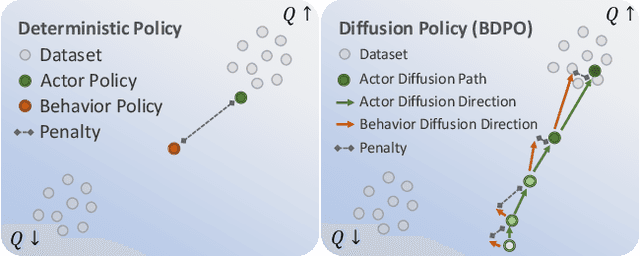
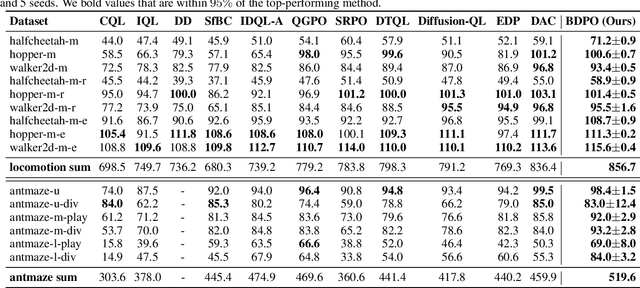
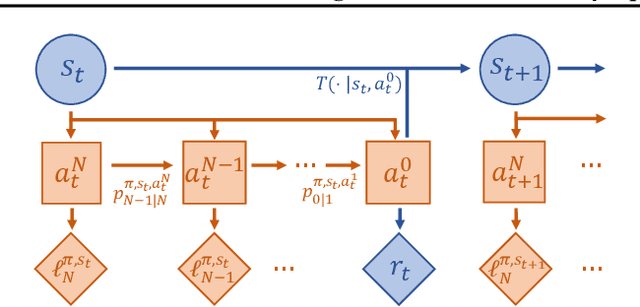
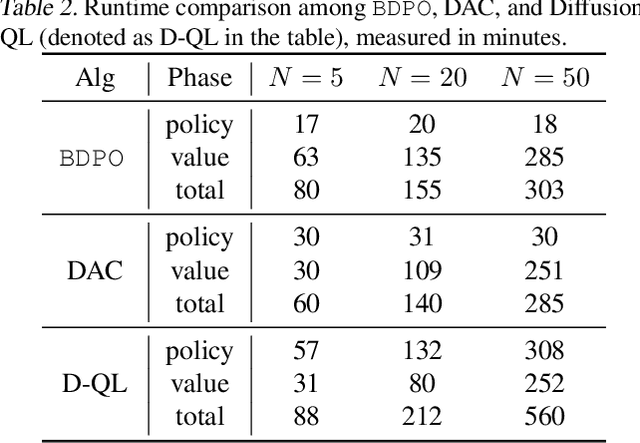
The primary focus of offline reinforcement learning (RL) is to manage the risk of hazardous exploitation of out-of-distribution actions. An effective approach to achieve this goal is through behavior regularization, which augments conventional RL objectives by incorporating constraints that enforce the policy to remain close to the behavior policy. Nevertheless, existing literature on behavior-regularized RL primarily focuses on explicit policy parameterizations, such as Gaussian policies. Consequently, it remains unclear how to extend this framework to more advanced policy parameterizations, such as diffusion models. In this paper, we introduce BDPO, a principled behavior-regularized RL framework tailored for diffusion-based policies, thereby combining the expressive power of diffusion policies and the robustness provided by regularization. The key ingredient of our method is to calculate the Kullback-Leibler (KL) regularization analytically as the accumulated discrepancies in reverse-time transition kernels along the diffusion trajectory. By integrating the regularization, we develop an efficient two-time-scale actor-critic RL algorithm that produces the optimal policy while respecting the behavior constraint. Comprehensive evaluations conducted on synthetic 2D tasks and continuous control tasks from the D4RL benchmark validate its effectiveness and superior performance.
Large Language Model-Enhanced Multi-Armed Bandits
Feb 03, 2025Large language models (LLMs) have been adopted to solve sequential decision-making tasks such as multi-armed bandits (MAB), in which an LLM is directly instructed to select the arms to pull in every iteration. However, this paradigm of direct arm selection using LLMs has been shown to be suboptimal in many MAB tasks. Therefore, we propose an alternative approach which combines the strengths of classical MAB and LLMs. Specifically, we adopt a classical MAB algorithm as the high-level framework and leverage the strong in-context learning capability of LLMs to perform the sub-task of reward prediction. Firstly, we incorporate the LLM-based reward predictor into the classical Thompson sampling (TS) algorithm and adopt a decaying schedule for the LLM temperature to ensure a transition from exploration to exploitation. Next, we incorporate the LLM-based reward predictor (with a temperature of 0) into a regression oracle-based MAB algorithm equipped with an explicit exploration mechanism. We also extend our TS-based algorithm to dueling bandits where only the preference feedback between pairs of arms is available, which requires non-trivial algorithmic modifications. We conduct empirical evaluations using both synthetic MAB tasks and experiments designed using real-world text datasets, in which the results show that our algorithms consistently outperform previous baseline methods based on direct arm selection. Interestingly, we also demonstrate that in challenging tasks where the arms lack semantic meanings that can be exploited by the LLM, our approach achieves considerably better performance than LLM-based direct arm selection.
$β$-DQN: Improving Deep Q-Learning By Evolving the Behavior
Jan 01, 2025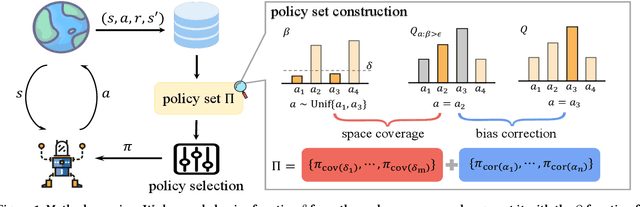
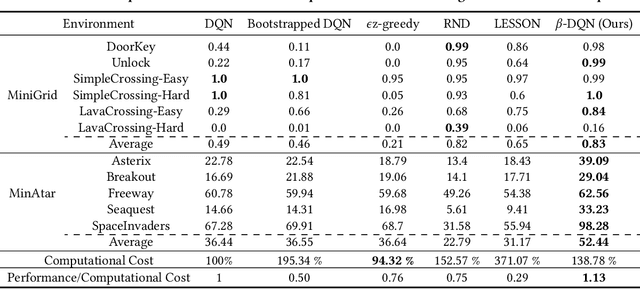
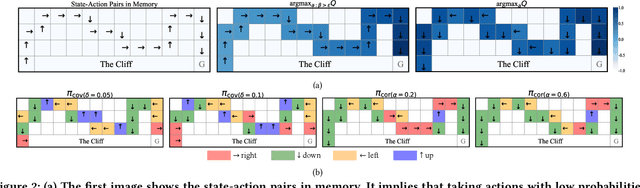

While many sophisticated exploration methods have been proposed, their lack of generality and high computational cost often lead researchers to favor simpler methods like $\epsilon$-greedy. Motivated by this, we introduce $\beta$-DQN, a simple and efficient exploration method that augments the standard DQN with a behavior function $\beta$. This function estimates the probability that each action has been taken at each state. By leveraging $\beta$, we generate a population of diverse policies that balance exploration between state-action coverage and overestimation bias correction. An adaptive meta-controller is designed to select an effective policy for each episode, enabling flexible and explainable exploration. $\beta$-DQN is straightforward to implement and adds minimal computational overhead to the standard DQN. Experiments on both simple and challenging exploration domains show that $\beta$-DQN outperforms existing baseline methods across a wide range of tasks, providing an effective solution for improving exploration in deep reinforcement learning.
Hindsight Preference Learning for Offline Preference-based Reinforcement Learning
Jul 05, 2024



Offline preference-based reinforcement learning (RL), which focuses on optimizing policies using human preferences between pairs of trajectory segments selected from an offline dataset, has emerged as a practical avenue for RL applications. Existing works rely on extracting step-wise reward signals from trajectory-wise preference annotations, assuming that preferences correlate with the cumulative Markovian rewards. However, such methods fail to capture the holistic perspective of data annotation: Humans often assess the desirability of a sequence of actions by considering the overall outcome rather than the immediate rewards. To address this challenge, we propose to model human preferences using rewards conditioned on future outcomes of the trajectory segments, i.e. the hindsight information. For downstream RL optimization, the reward of each step is calculated by marginalizing over possible future outcomes, the distribution of which is approximated by a variational auto-encoder trained using the offline dataset. Our proposed method, Hindsight Preference Learning (HPL), can facilitate credit assignment by taking full advantage of vast trajectory data available in massive unlabeled datasets. Comprehensive empirical studies demonstrate the benefits of HPL in delivering robust and advantageous rewards across various domains. Our code is publicly released at https://github.com/typoverflow/WiseRL.
Diffusion Spectral Representation for Reinforcement Learning
Jun 23, 2024



Diffusion-based models have achieved notable empirical successes in reinforcement learning (RL) due to their expressiveness in modeling complex distributions. Despite existing methods being promising, the key challenge of extending existing methods for broader real-world applications lies in the computational cost at inference time, i.e., sampling from a diffusion model is considerably slow as it often requires tens to hundreds of iterations to generate even one sample. To circumvent this issue, we propose to leverage the flexibility of diffusion models for RL from a representation learning perspective. In particular, by exploiting the connection between diffusion model and energy-based model, we develop Diffusion Spectral Representation (Diff-SR), a coherent algorithm framework that enables extracting sufficient representations for value functions in Markov decision processes (MDP) and partially observable Markov decision processes (POMDP). We further demonstrate how Diff-SR facilitates efficient policy optimization and practical algorithms while explicitly bypassing the difficulty and inference cost of sampling from the diffusion model. Finally, we provide comprehensive empirical studies to verify the benefits of Diff-SR in delivering robust and advantageous performance across various benchmarks with both fully and partially observable settings.
Target Networks and Over-parameterization Stabilize Off-policy Bootstrapping with Function Approximation
May 31, 2024We prove that the combination of a target network and over-parameterized linear function approximation establishes a weaker convergence condition for bootstrapped value estimation in certain cases, even with off-policy data. Our condition is naturally satisfied for expected updates over the entire state-action space or learning with a batch of complete trajectories from episodic Markov decision processes. Notably, using only a target network or an over-parameterized model does not provide such a convergence guarantee. Additionally, we extend our results to learning with truncated trajectories, showing that convergence is achievable for all tasks with minor modifications, akin to value truncation for the final states in trajectories. Our primary result focuses on temporal difference estimation for prediction, providing high-probability value estimation error bounds and empirical analysis on Baird's counterexample and a Four-room task. Furthermore, we explore the control setting, demonstrating that similar convergence conditions apply to Q-learning.
An MRP Formulation for Supervised Learning: Generalized Temporal Difference Learning Models
Apr 23, 2024
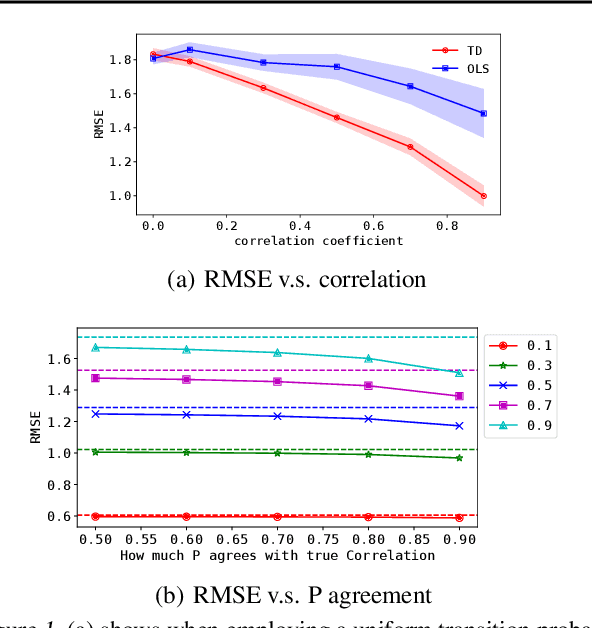
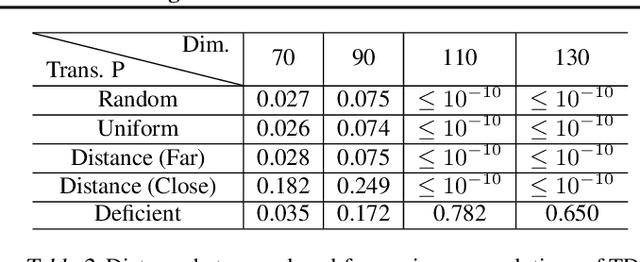
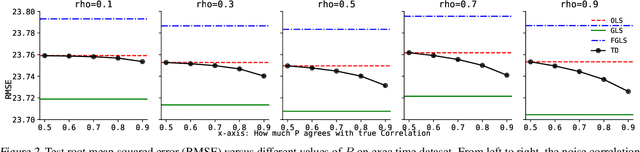
In traditional statistical learning, data points are usually assumed to be independently and identically distributed (i.i.d.) following an unknown probability distribution. This paper presents a contrasting viewpoint, perceiving data points as interconnected and employing a Markov reward process (MRP) for data modeling. We reformulate the typical supervised learning as an on-policy policy evaluation problem within reinforcement learning (RL), introducing a generalized temporal difference (TD) learning algorithm as a resolution. Theoretically, our analysis draws connections between the solutions of linear TD learning and ordinary least squares (OLS). We also show that under specific conditions, particularly when noises are correlated, the TD's solution proves to be a more effective estimator than OLS. Furthermore, we establish the convergence of our generalized TD algorithms under linear function approximation. Empirical studies verify our theoretical results, examine the vital design of our TD algorithm and show practical utility across various datasets, encompassing tasks such as regression and image classification with deep learning.