 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial: An Intuitive Explanation of Offline Reinforcement Learning Theory
Aug 11, 2025Offline reinforcement learning (RL) aims to optimize the return given a fixed dataset of agent trajectories without additional interactions with the environment. While algorithm development has progressed rapidly, significant theoretical advances have also been made in understanding the fundamental challenges of offline RL. However, bridging these theoretical insights with practical algorithm design remains an ongoing challenge. In this survey, we explore key intuitions derived from theoretical work and their implications for offline RL algorithms. We begin by listing the conditions needed for the proofs, including function representation and data coverage assumptions. Function representation conditions tell us what to expect for generalization, and data coverage assumptions describe the quality requirement of the data. We then examine counterexamples, where offline RL is not solvable without an impractically large amount of data. These cases highlight what cannot be achieved for all algorithms and the inherent hardness of offline RL. Building on techniques to mitigate these challenges, we discuss the conditions that are sufficient for offline RL. These conditions are not merely assumptions for theoretical proofs, but they also reveal the limitations of these algorithms and remind us to search for novel solutions when the conditions cannot be satisfied.
AVG-DICE: Stationary Distribution Correction by Regression
Mar 03, 2025Off-policy policy evaluation (OPE), an essential component of reinforcement learning, has long suffered from stationary state distribution mismatch, undermining both stability and accuracy of OPE estimates. While existing methods correct distribution shifts by estimating density ratios, they often rely on expensive optimization or backward Bellman-based updates and struggle to outperform simpler baselines. We introduce AVG-DICE, a computationally simple Monte Carlo estimator for the density ratio that averages discounted importance sampling ratios, providing an unbiased and consistent correction. AVG-DICE extends naturally to nonlinear function approximation using regression, which we roughly tune and test on OPE tasks based on Mujoco Gym environments and compare with state-of-the-art density-ratio estimators using their reported hyperparameters. In our experiments, AVG-DICE is at least as accurate as state-of-the-art estimators and sometimes offers orders-of-magnitude improvements. However, a sensitivity analysis shows that best-performing hyperparameters may vary substantially across different discount factors, so a re-tuning is suggested.
Target Networks and Over-parameterization Stabilize Off-policy Bootstrapping with Function Approximation
May 31, 2024We prove that the combination of a target network and over-parameterized linear function approximation establishes a weaker convergence condition for bootstrapped value estimation in certain cases, even with off-policy data. Our condition is naturally satisfied for expected updates over the entire state-action space or learning with a batch of complete trajectories from episodic Markov decision processes. Notably, using only a target network or an over-parameterized model does not provide such a convergence guarantee. Additionally, we extend our results to learning with truncated trajectories, showing that convergence is achievable for all tasks with minor modifications, akin to value truncation for the final states in trajectories. Our primary result focuses on temporal difference estimation for prediction, providing high-probability value estimation error bounds and empirical analysis on Baird's counterexample and a Four-room task. Furthermore, we explore the control setting, demonstrating that similar convergence conditions apply to Q-learning.
Correcting discount-factor mismatch in on-policy policy gradient methods
Jun 23, 2023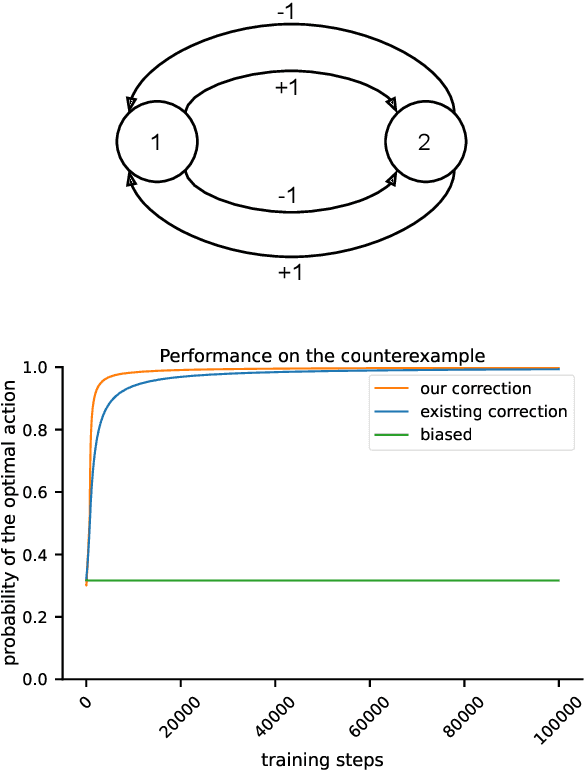
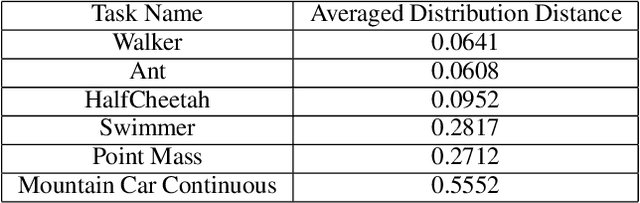
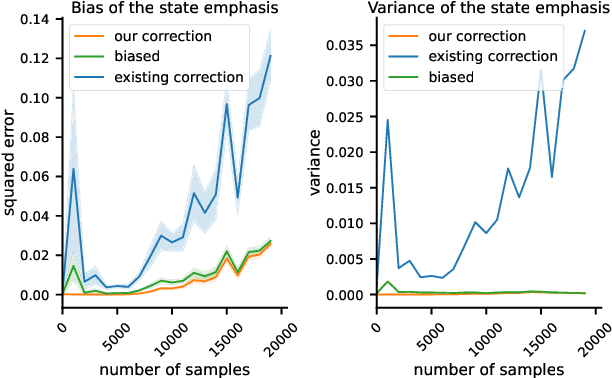
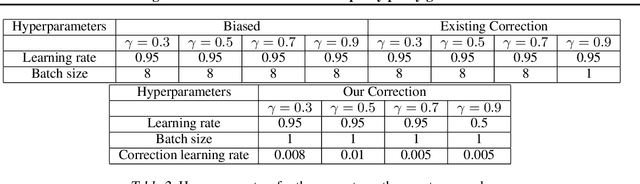
The policy gradient theorem gives a convenient form of the policy gradient in terms of three factors: an action value, a gradient of the action likelihood, and a state distribution involving discounting called the \emph{discounted stationary distribution}. But commonly used on-policy methods based on the policy gradient theorem ignores the discount factor in the state distribution, which is technically incorrect and may even cause degenerate learning behavior in some environments. An existing solution corrects this discrepancy by using $\gamma^t$ as a factor in the gradient estimate. However, this solution is not widely adopted and does not work well in tasks where the later states are similar to earlier states. We introduce a novel distribution correction to account for the discounted stationary distribution that can be plugged into many existing gradient estimators. Our correction circumvents the performance degradation associated with the $\gamma^t$ correction with a lower variance. Importantly, compared to the uncorrected estimators, our algorithm provides improved state emphasis to evade suboptimal policies in certain environments and consistently matches or exceeds the original performance on several OpenAI gym and DeepMind suite benchmarks.
Bayesian Q-learning With Imperfect Expert Demonstrations
Oct 01, 2022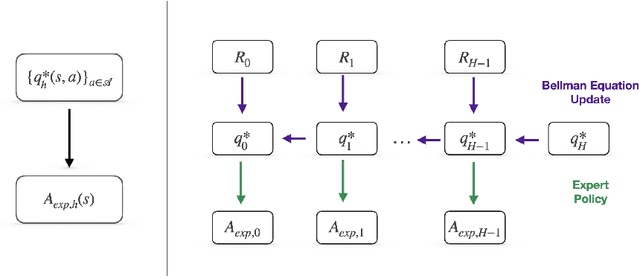
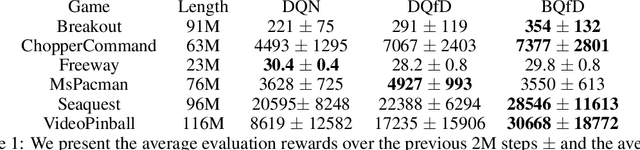
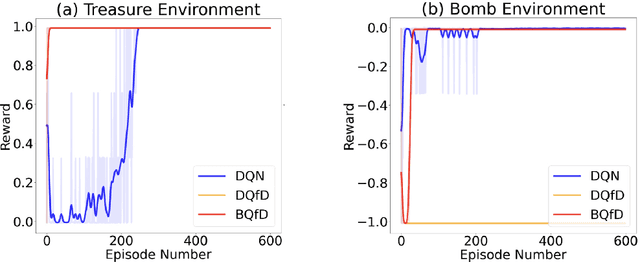

Guided exploration with expert demonstrations improves data efficiency for reinforcement learning, but current algorithms often overuse expert information. We propose a novel algorithm to speed up Q-learning with the help of a limited amount of imperfect expert demonstrations. The algorithm avoids excessive reliance on expert data by relaxing the optimal expert assumption and gradually reducing the usage of uninformative expert data. Experimentally, we evaluate our approach on a sparse-reward chain environment and six more complicated Atari games with delayed rewards. With the proposed methods, we can achieve better results than Deep Q-learning from Demonstrations (Hester et al., 2017) in most environments.
Detecting GAN generated errors
Dec 02, 2019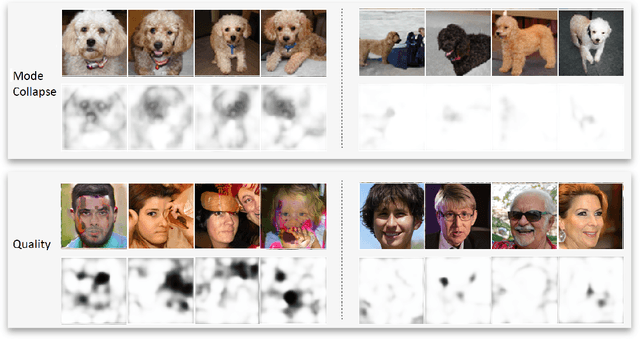



Despite an impressive performance from the latest GAN for generating hyper-realistic images, GAN discriminators have difficulty evaluating the quality of an individual generated sample. This is because the task of evaluating the quality of a generated image differs from deciding if an image is real or fake. A generated image could be perfect except in a single area but still be detected as fake. Instead, we propose a novel approach for detecting where errors occur within a generated image. By collaging real images with generated images, we compute for each pixel, whether it belongs to the real distribution or generated distribution. Furthermore, we leverage attention to model long-range dependency; this allows detection of errors which are reasonable locally but not holistically. For evaluation, we show that our error detection can act as a quality metric for an individual image, unlike FID and IS. We leverage Improved Wasserstein, BigGAN, and StyleGAN to show a ranking based on our metric correlates impressively with FID scores. Our work opens the door for better understanding of GAN and the ability to select the best samples from a GAN model.