 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelightful Gradients Accelerate Corner Escape
May 12, 2026Softmax policy gradient converges at $O(1/t)$, but its transient behavior near sub-optimal corners of the simplex can be exponentially slow. The bottleneck is self-trapping: negative-advantage actions reinforce the corner policy and can initially push the optimal action backward. We study \emph{Delightful Policy Gradient} (DG), which gates each policy-gradient term by the product of advantage and action surprisal. For $K$-armed bandits, we prove that the zero-temperature limit of DG removes this corner-trapping mechanism on a quantitative sector near any sub-optimal corner, yielding a first-exit escape bound logarithmic in the initial probability ratio. At every fixed temperature, the same local mechanism persists because harmful actions are polynomially suppressed as they become rare. A key structural insight is that every action better than the corner action is an \emph{ally}: its contribution to escape is non-negative. Combining corner instability with a monotonic value improvement identity, we prove that DG converges globally to the optimal policy in both bandits and tabular MDPs at an asymptotic $O(1/t)$ rate. We also show, via an exact counterexample, that this tabular mechanism can fail under shared function approximation. In MNIST contextual bandits with a shared-parameter neural network, DG nevertheless recovers from bad initializations faster than standard policy gradient, suggesting that the counterexample marks a boundary of the theory rather than a practical prohibition.
Revisiting Mixture Policies in Entropy-Regularized Actor-Critic
May 09, 2026Mixture policies theoretically offer greater flexibility than unimodal policies in continuous action reinforcement learning, but the practical benefits of this complexity remain elusive. Mixture policies are notably absent from most state-of-the-art algorithms, raising a fundamental question: Is the added representational overhead useful? We show that increased flexibility can theoretically enhance solution quality and entropy robustness. Yet standard algorithms like SAC do not leverage these advantages. A core issue is the lack of a low-variance reparameterization trick for mixtures, a luxury Gaussian policies enjoy. We propose a marginalized reparameterization (MRP) estimator to address this, proving it offers lower variance than the standard likelihood-ratio (LR) approach. Our experiments across Gym MuJoCo, DeepMind Control Suite, and MetaWorld show that MRP mixture policies significantly outperform their LR ones, and reach parity (sometimes better) with Gaussian counterparts. In addition, we do find several cases where MRP mixture policies exhibit clear empirical advantages. In this paper, we provide a clearer understanding of the trade-offs involved, elevating MRP mixture policies from theoretical curiosity to a practical tool.
Rethinking the Global Convergence of Softmax Policy Gradient with Linear Function Approximation
May 06, 2025Policy gradient (PG) methods have played an essential role in the empirical successes of reinforcement learning. In order to handle large state-action spaces, PG methods are typically used with function approximation. In this setting, the approximation error in modeling problem-dependent quantities is a key notion for characterizing the global convergence of PG methods. We focus on Softmax PG with linear function approximation (referred to as $\texttt{Lin-SPG}$) and demonstrate that the approximation error is irrelevant to the algorithm's global convergence even for the stochastic bandit setting. Consequently, we first identify the necessary and sufficient conditions on the feature representation that can guarantee the asymptotic global convergence of $\texttt{Lin-SPG}$. Under these feature conditions, we prove that $T$ iterations of $\texttt{Lin-SPG}$ with a problem-specific learning rate result in an $O(1/T)$ convergence to the optimal policy. Furthermore, we prove that $\texttt{Lin-SPG}$ with any arbitrary constant learning rate can ensure asymptotic global convergence to the optimal policy.
Ordering-based Conditions for Global Convergence of Policy Gradient Methods
Apr 02, 2025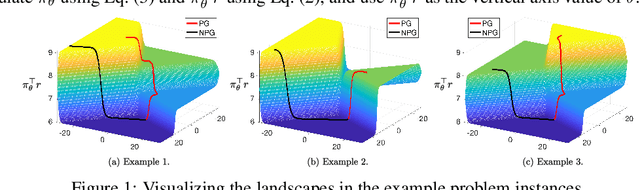
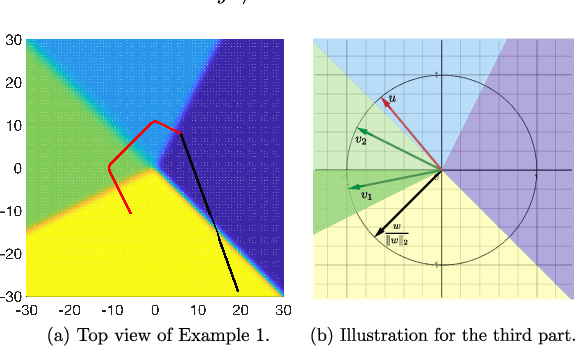
We prove that, for finite-arm bandits with linear function approximation, the global convergence of policy gradient (PG) methods depends on inter-related properties between the policy update and the representation. textcolor{blue}{First}, we establish a few key observations that frame the study: \textbf{(i)} Global convergence can be achieved under linear function approximation without policy or reward realizability, both for the standard Softmax PG and natural policy gradient (NPG). \textbf{(ii)} Approximation error is not a key quantity for characterizing global convergence in either algorithm. \textbf{(iii)} The conditions on the representation that imply global convergence are different between these two algorithms. Overall, these observations call into question approximation error as an appropriate quantity for characterizing the global convergence of PG methods under linear function approximation. \textcolor{blue}{Second}, motivated by these observations, we establish new general results: \textbf{(i)} NPG with linear function approximation achieves global convergence \emph{if and only if} the projection of the reward onto the representable space preserves the optimal action's rank, a quantity that is not strongly related to approximation error. \textbf{(ii)} The global convergence of Softmax PG occurs if the representation satisfies a non-domination condition and can preserve the ranking of rewards, which goes well beyond policy or reward realizability. We provide experimental results to support these theoretical findings.
Small steps no more: Global convergence of stochastic gradient bandits for arbitrary learning rates
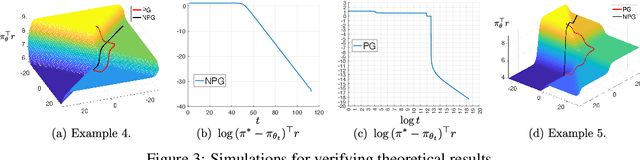
Feb 11, 2025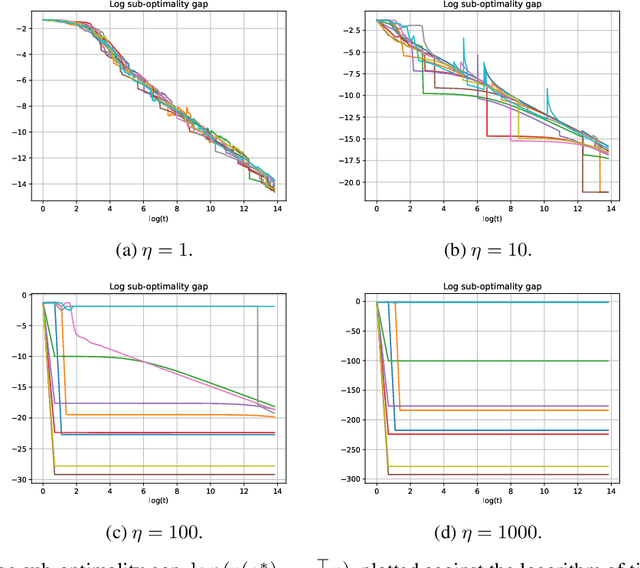
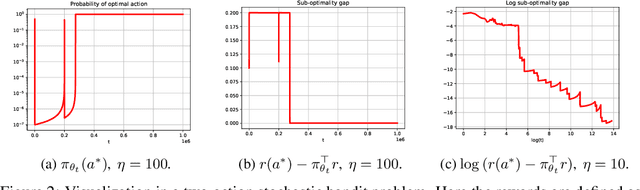
We provide a new understanding of the stochastic gradient bandit algorithm by showing that it converges to a globally optimal policy almost surely using \emph{any} constant learning rate. This result demonstrates that the stochastic gradient algorithm continues to balance exploration and exploitation appropriately even in scenarios where standard smoothness and noise control assumptions break down. The proofs are based on novel findings about action sampling rates and the relationship between cumulative progress and noise, and extend the current understanding of how simple stochastic gradient methods behave in bandit settings.
Faster WIND: Accelerating Iterative Best-of-$N$ Distillation for LLM Alignment
Oct 28, 2024


Recent advances in aligning large language models with human preferences have corroborated the growing importance of best-of-N distillation (BOND). However, the iterative BOND algorithm is prohibitively expensive in practice due to the sample and computation inefficiency. This paper addresses the problem by revealing a unified game-theoretic connection between iterative BOND and self-play alignment, which unifies seemingly disparate algorithmic paradigms. Based on the connection, we establish a novel framework, WIN rate Dominance (WIND), with a series of efficient algorithms for regularized win rate dominance optimization that approximates iterative BOND in the parameter space. We provides provable sample efficiency guarantee for one of the WIND variant with the square loss objective. The experimental results confirm that our algorithm not only accelerates the computation, but also achieves superior sample efficiency compared to existing methods.
Target Networks and Over-parameterization Stabilize Off-policy Bootstrapping with Function Approximation
May 31, 2024We prove that the combination of a target network and over-parameterized linear function approximation establishes a weaker convergence condition for bootstrapped value estimation in certain cases, even with off-policy data. Our condition is naturally satisfied for expected updates over the entire state-action space or learning with a batch of complete trajectories from episodic Markov decision processes. Notably, using only a target network or an over-parameterized model does not provide such a convergence guarantee. Additionally, we extend our results to learning with truncated trajectories, showing that convergence is achievable for all tasks with minor modifications, akin to value truncation for the final states in trajectories. Our primary result focuses on temporal difference estimation for prediction, providing high-probability value estimation error bounds and empirical analysis on Baird's counterexample and a Four-room task. Furthermore, we explore the control setting, demonstrating that similar convergence conditions apply to Q-learning.
Value-Incentivized Preference Optimization: A Unified Approach to Online and Offline RLHF
May 29, 2024


Reinforcement learning from human feedback (RLHF) has demonstrated great promise in aligning large language models (LLMs) with human preference. Depending on the availability of preference data, both online and offline RLHF are active areas of investigation. A key bottleneck is understanding how to incorporate uncertainty estimation in the reward function learned from the preference data for RLHF, regardless of how the preference data is collected. While the principles of optimism or pessimism under uncertainty are well-established in standard reinforcement learning (RL), a practically-implementable and theoretically-grounded form amenable to large language models is not yet available, as standard techniques for constructing confidence intervals become intractable under arbitrary policy parameterizations. In this paper, we introduce a unified approach to online and offline RLHF -- value-incentivized preference optimization (VPO) -- which regularizes the maximum-likelihood estimate of the reward function with the corresponding value function, modulated by a $\textit{sign}$ to indicate whether the optimism or pessimism is chosen. VPO also directly optimizes the policy with implicit reward modeling, and therefore shares a simpler RLHF pipeline similar to direct preference optimization. Theoretical guarantees of VPO are provided for both online and offline settings, matching the rates of their standard RL counterparts. Moreover, experiments on text summarization and dialog verify the practicality and effectiveness of VPO.
Stochastic Gradient Succeeds for Bandits
Feb 27, 2024



We show that the \emph{stochastic gradient} bandit algorithm converges to a \emph{globally optimal} policy at an $O(1/t)$ rate, even with a \emph{constant} step size. Remarkably, global convergence of the stochastic gradient bandit algorithm has not been previously established, even though it is an old algorithm known to be applicable to bandits. The new result is achieved by establishing two novel technical findings: first, the noise of the stochastic updates in the gradient bandit algorithm satisfies a strong ``growth condition'' property, where the variance diminishes whenever progress becomes small, implying that additional noise control via diminishing step sizes is unnecessary; second, a form of ``weak exploration'' is automatically achieved through the stochastic gradient updates, since they prevent the action probabilities from decaying faster than $O(1/t)$, thus ensuring that every action is sampled infinitely often with probability $1$. These two findings can be used to show that the stochastic gradient update is already ``sufficient'' for bandits in the sense that exploration versus exploitation is automatically balanced in a manner that ensures almost sure convergence to a global optimum. These novel theoretical findings are further verified by experimental results.
Beyond Expectations: Learning with Stochastic Dominance Made Practical
Feb 05, 2024



Stochastic dominance models risk-averse preferences for decision making with uncertain outcomes, which naturally captures the intrinsic structure of the underlying uncertainty, in contrast to simply resorting to the expectations. Despite theoretically appealing, the application of stochastic dominance in machine learning has been scarce, due to the following challenges: $\textbf{i)}$, the original concept of stochastic dominance only provides a $\textit{partial order}$, therefore, is not amenable to serve as an optimality criterion; and $\textbf{ii)}$, an efficient computational recipe remains lacking due to the continuum nature of evaluating stochastic dominance.%, which barriers its application for machine learning. In this work, we make the first attempt towards establishing a general framework of learning with stochastic dominance. We first generalize the stochastic dominance concept to enable feasible comparisons between any arbitrary pair of random variables. We next develop a simple and computationally efficient approach for finding the optimal solution in terms of stochastic dominance, which can be seamlessly plugged into many learning tasks. Numerical experiments demonstrate that the proposed method achieves comparable performance as standard risk-neutral strategies and obtains better trade-offs against risk across a variety of applications including supervised learning, reinforcement learning, and portfolio optimization.